I’m sure Guido will give you the proper fix; but in case it helps in the short-term, I have found that explicitly setting the MOE nodes to write to disk (under Memory Policy) gets round these sorts of issues for me.
Again i had the same problem. after calculating descriptors in MOE, I could not save the work-flow and the message was "Java heap space"
then i have started to develop some classifcation models and it shows following error.
ERROR Weka Predictor Unable to clone input data at port 0: Java heap space
ERROR Weka Predictor Execute failed: Java heap space
ERROR Weka Predictor Execute failed: GC overhead limit exceeded
ERROR Weka Predictor Unable to clone input data at port 0: Java heap space
ERROR Weka Predictor Unable to clone input data at port 0: Java heap space
ERROR Weka Predictor Unable to clone input data at port 0: Java heap space
ERROR Weka Predictor Execute failed: GC overhead limit exceeded
I am running KNIME latest version in Ubunto. I am looking forward to see your reply
Just to be sure: did you increase "-XX:MaxPermSize" or "-Xmx"? Only the latter really gives you more memory, the former is just for adjusting the different memory areas of Java.
The problem with the Weka integration is that they read the data into memory before starting to process them which is due to the underlying library. In your case, you will need at least 26.000 rows x 500 columns x #bytes. Any chance to run the KNIME feature elimination setup, before running the Weka learning method?
InputStream fis = null;
JsonArray json_array = null;
try {
fis = new FileInputStream( c_Location );
JsonReader reader = Json.createReader(fis);
json_array = (JsonArray) reader.readArray();
out_json = new JsonValue[json_array.size()];
for(int i = 0; i < json_array.size(); i++){
JsonValue object = json_array.get(i);
// now do something with the Object
out_json[i] = object;
}
reader.close();
} catch (IOException e) {
// e.printStackTrace();
}
conclusion
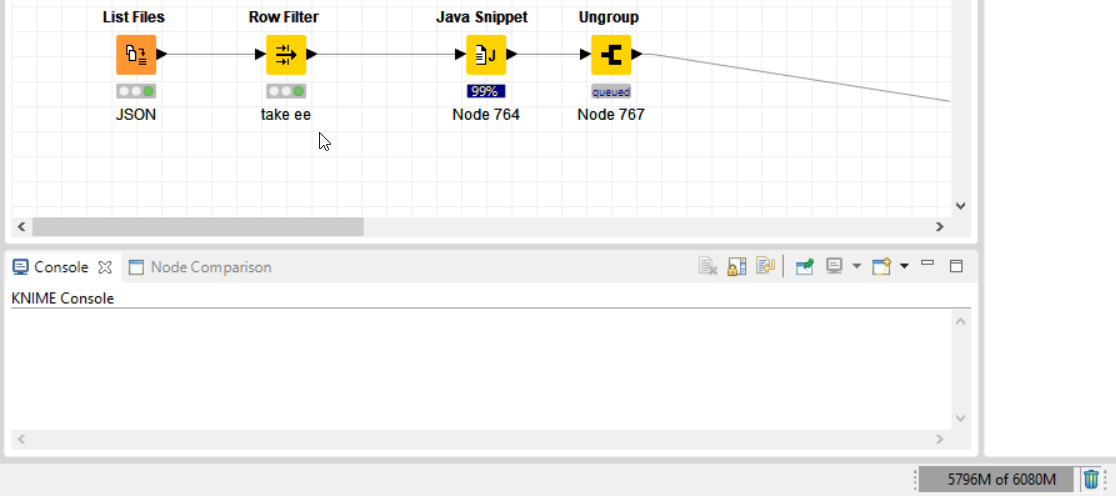
-use the ListFiles node and fetch the Location as input for the Java Snippet (create chunked loops if needed)
-the inputstream and json reader reader can easily absorb the json within the heapspace limits.
-the for loop will create an array of JsonValues, which can than be ungrouped and further processed (with JSONPath per row)
-the for loop however takes a while as it will have to copy the data from an ArrayList to a native array of JsonValues
so your flow will remain on 99% for a while, but it will make it through
Happening the same with the JSON Reader. Windows 10 on SSD, 8GB + I5, last version to 19/12/2019, already tried to write tables in disk, -Xmx7048m, reading a JSON file of about 1GB size.
I managed to use PowerQuery and export to XLS, and while it’s very slow to load the file Knime seems to handle it, but this is suboptimal and if I’m using Knime is precisely to not use PowerQuery…