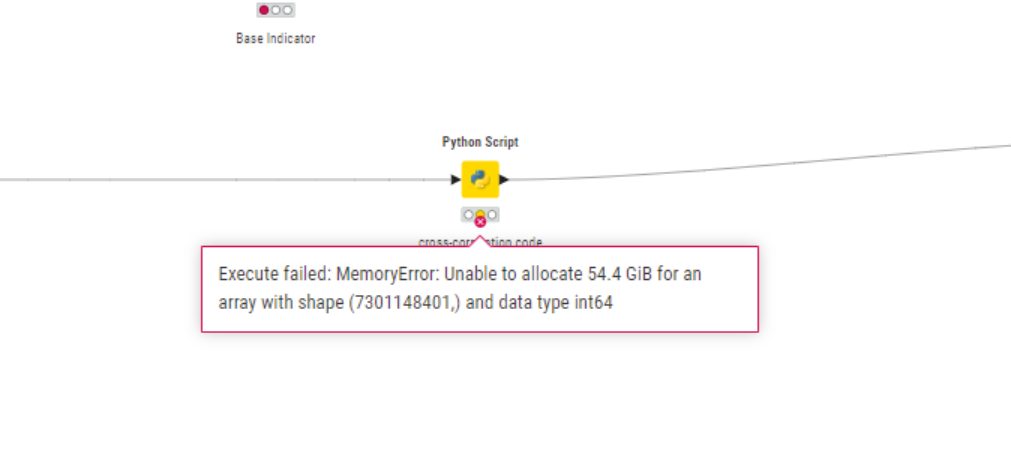
i am trying to execute python script but getting error like Execute failed: MemoryError: Unable to allocate 54.4 GiB for an array with shape (7301148401,) and data type int64. i changed knime.ini file .like -Xm5G to -Xm12G but still not solve issue please find attached below photo.
@Rohit_208 this is the memory used by python and 54GB is a lot. How much does your machine have and how large is the initial data and what is it you are trying to do?
1 Like
Hello @mlauber71 ,
My dataset comprises 6389 rows and 291 columns, and I’m attempting to calculate cross-correlations. Initially, my code will determine the year-over-year (YoY) growth. Subsequently, I’ll designate one column as the base indicator, with an overlapping code. Following this, I will compute the cross-correlation. Despite allocating 12 GB to KNIME by updating the KNIME.ini file due to my laptop’s 16 GB RAM (with 15.6 GB usable), I’m still encountering issues. If I utilize the parallel start chunk node, it’s possible that my cross-correlation results may not be accurate. This is because, during the overlapping process, only the data present in the base indicator and correlated indicator will be considered.what i do in this case?
Hello @mlauber71 ,
if i am using parallel chunk start during flow before python cross correlation script then show me error MemoryError: Unable to allocate 3.37 GiB for an array with shape (1, 452336548) and data type float64
Traceback (most recent call last):
Hello @mlauber71 ,
Do you have any idea about regard this issue?
Hi @Rohit_208 , it sounds to me that you have a process which consumes a vast amount of memory, but it’s a python script, so without knowing exactly what your script is doing, it’s going to be difficult to say what to change.
I’m confused though - if your process is running out of memory, why do you think that trying to parallel the processing will consume less memory?
I’m giving a naive example here but say your single process consumes 50GB and you split it into 10 parallel processes, then they will each try to consume (for sake of argument) 5GB, but that’s still 50GB required overall, and at some point one of those processes will try to grab its 5GB and be told it cannot have it.
When you say you are trying to create a cross-correlation script for your 6389 x 291 table, do you mean that you are therefore trying to process 6389^2 rows (41 million) so you are trying to hold an array of 41 million x 291 elements (11.8 billion) in memory at the same time?
[edit: in fact if each table has 291 elements, then the total would be 41 million x 291 x 2 (i.e. 291 cross-joined from each table) elements , so actually about 23 billion elements! If you had just 1 byte per array item, that would be 23GB, and a single float64 or int64 element consumes 8 bytes!) ]
3 Likes
Hello @takbb ,
My python script say that ,
- Data Preprocessing in
calculate_yoy_growthFunction:
- The
calculate_yoy_growthfunction takes a DataFramedfand a list of columns to skip as input. - It first converts the ‘Date’ column to datetime format and creates a new DataFrame
dcontaining only the ‘Date’ column. - Then, for each column in the input DataFrame:
- It skips the columns mentioned in the
columns_to_skiplist and those with non-numeric data types. - It identifies the non-null values’ range, interpolates missing values, and calculates the year-over-year growth using the
pct_changefunction. - The non-null growth values are then merged into the
dDataFrame using the ‘Date’ column as the merging key.
- It skips the columns mentioned in the
- Cross-Correlation Analysis in
perform_analysisFunction:
- The
perform_analysisfunction takes the result DataFrame fromcalculate_yoy_growth, a base indicator, correlation lag horizon, correlation threshold, and an optional start year as input. - It converts the result DataFrame to a numpy array for further processing and extracts the year-over-year growth values of the base indicator.
- It then performs cross-correlation analysis between the base indicator and other indicators, calculating the cross-correlation values, normalization, lag, and identifying significant correlations based on the specified threshold.
- The results of the correlation analysis are stored in a DataFrame
correlation_table_yoycontaining the details of correlated indicators, correlation values, and lag.
- Output and Explanation:
- Following the functions, the script prints the data types of the DataFrame columns using
df.dtypes. - It then calls the
calculate_yoy_growthfunction to obtain the year-over-year growth results and subsequently performs the correlation analysis using theperform_analysisfunction. - The resulting correlation table is then printed to display the correlated indicators, their correlation values, and lag.
every non-null value indicator correlated with non-null value base indicator find out cross correlation.
The script essentially processes the input data to calculate year-over-year growth for each indicator and subsequently performs a cross-correlation analysis to identify significant correlations between different indicators based on specified criteria.
Hi @Rohit_208 , a table of 6389 x 291 but when performing the cross-correlation, how many rows are being compared with how many rows?
Also, when you mentioned you specify “columns_to_skip” such as those with non-numeric datatypes, are those columns all still present even though the function “skips” them. If they aren’t needed, can you perhaps leave them out of the dataframe entirely, right from the beginning, as they all perhaps still consume memory ?
Can you limit the number of rows that you are trying to cross-correlate at any one time?
e.g. If I had a table of 1000 “things” and I want to perform a cross-correlation between each of those 1000 things, I could:
(1) Attempt to cross-join all 1000 with all 1000 and then attempt to process 1,000,000 comparisons all in one go
or
(2) Attempt to cross-join in batches of 10 (or some other small number) with all 1000, and then I would be looking at 10,000 comparisons at a time, and concatenate the results to achieve my correlation. The peak memory usage should be considerably smaller in this scenario.
It is likely that option (2) would be slower, and perhaps require a little more complexity, but data processing is in part making compromises and working out how to do what you want to achieve within the limitations of the hardware you have available.
Now option (2) would likely involve some form of chunk-loop or group-loop rather than a parallel loop, because the only way you are going to get through that data by the sound of it, is serially rather than in parallel. But it is not clear exactly what KNIME’s involvement with your python script is (is the python script itself inside a KNIME loop?), so I don’t know whether actually it is some sort of loop process within the python script that you require.
All that said… 6400 rows is not a huge starting point and there is always the possibility that you simply have a bug in your script which is inflating your array up to 50+GB, which is an extraordinary amount of data to be requiring in one go, especially on a laptop! Have you ruled out that possibility?
2 Likes
@Rohit_208 often with very large datasets you will have to cut down and iterate the task.
Maybe besides following the good advice by @takbb you can take inspiration from these articles about KNIME, performance and large datasets.
2 Likes
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.