I found a sample workflow from 2013 that shows how to execute SQL from a text file, but it’s very cumbersome. I’m hoping that someone has developed a node or some other way to execute a multi-line SQL file. I saw reference to a developer called Vernalis, but I looked through their nodepit and didn’t see anything that would help solve.
In addition and similar, I’m wondering if anyone has done this while pulling the file from a GIT repository using the GIT nodes.
I spent some more time this this example and it’s close to working. The biggest issue is nobody formats their SQL on a single line and so that’s a deal breaker for us. This old 2013 post still has some good information. Can I read in an external sql file and use this in a query
Does anyone know how you might put a multi-line text file into a single variable for DB Query Reader to use?
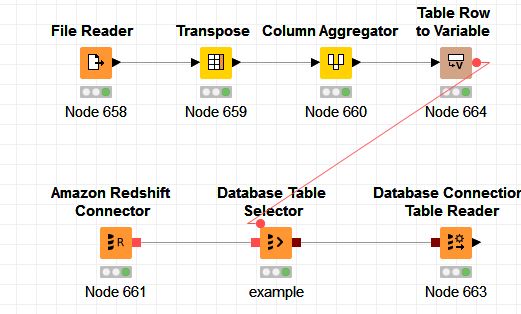
When I use a file reader for an sql file, it creates a table with 1 column and multiple rows (with sql). Then use a Transpose node and do a Column Aggregator (Concatenate, white-space delimiter ) . The result is a table with 1 cell with all the sql . The sql cell is transformed to a flow variable, that I use in the table selector
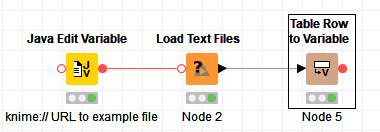
I would suggest using some of the IO nodes from the Vernalis community contribution. If you only have 1 sql file, then following will work:
In this case, the edit variable is just to create a flow variable with a knime:// protcol URL to point to the example file embedded in the workflow - you can pass the file paths in as a single ‘;’-delimited flow variable, are select them in the configuration dialog.
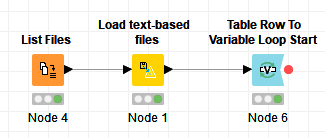
If you have lots of files, then you can loop through them using the sequence below: