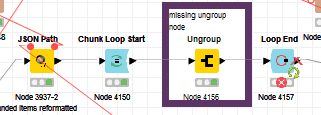
My flow that has been working well for months suddenly threw this error in the Loop End node → Execution failed in Try-Catch block: Duplicate key detected: “Row0_1#2” within Chunk Loop Start and Loop End.
This is the error message in the _error_stacktrace in the Flow Variables in the Loop End node.
[[[[[org.knime.core.util.DuplicateKeyException: Duplicate key detected: “Row0_1#2”
at org.knime.core.util.DuplicateChecker.addKey(DuplicateChecker.java:258)
at org.knime.base.node.meta.looper.ConcatenateTableFactory.addTable(ConcatenateTableFactory.java:245)
at org.knime.base.node.meta.looper.ConcatenateTableFactory.addTable(ConcatenateTableFactory.java:150)
at org.knime.base.node.meta.looper.LoopEndNodeModel.execute(LoopEndNodeModel.java:142)
at org.knime.core.node.NodeModel.execute(NodeModel.java:747)
at org.knime.core.node.NodeModel.executeModel(NodeModel.java:576)
at org.knime.core.node.Node.invokeFullyNodeModelExecute(Node.java:1245)
at org.knime.core.node.Node.execute(Node.java:1025)
at org.knime.core.node.workflow.NativeNodeContainer.performExecuteNode(NativeNodeContainer.java:558)
at org.knime.core.node.exec.LocalNodeExecutionJob.mainExecute(LocalNodeExecutionJob.java:95)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:201)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:117)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:334)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:210)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)]]]]]
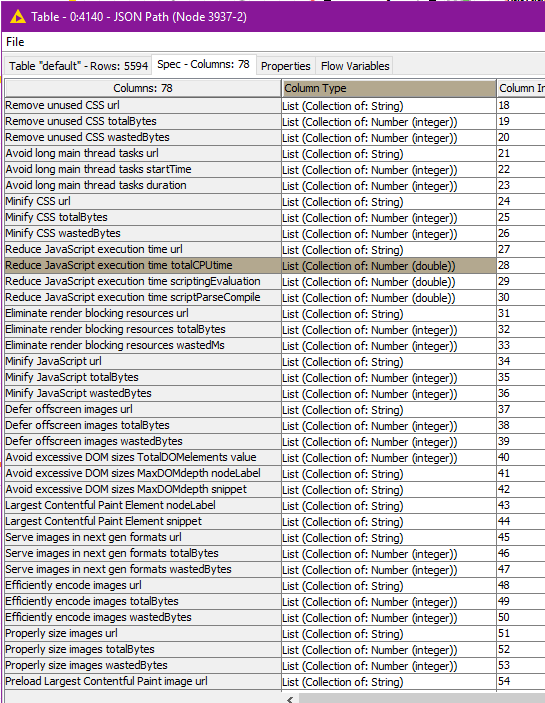
This is what the JSON Path is outputting, normal rows plus many List Collection sets.
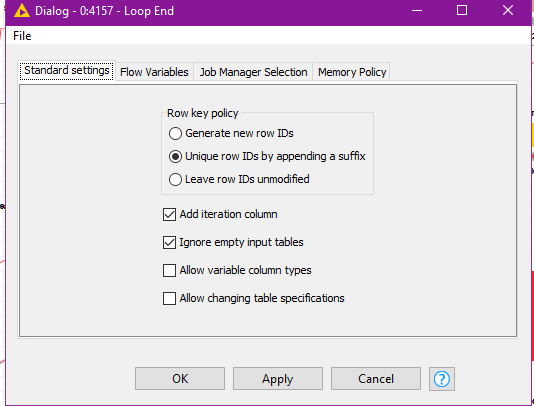
I feed it thru Ungroup node and collect with Loop End node. I have tried all 3 Row key policy and all throw the same error. I have also tried setting different # of rows per chunk in the Chunk Loop Start node.
Could anyone share your knowledge and educate me on why this is happening and how to resolve this error please?
I greatly appreciate your time and help. Thank you!!
In the Loop End node configuration, I tested with and without “Add iteration column” and that does not seem to affect the outcome, which is the same error.
I added RowID node to reset the row id between JSON Path node and Chunk Loop Start node and that did not make a difference, same error.
I executed one node at a time and things looked good until the Loop End throwing the same error.
I added RowID node between the Ungroup node and Loop End node to reset the row id and that still resulted with the same duplicate error but slightly different ID → "Duplicate key detected: “Row0#2” which is different from earlier “Row0_1#2”
I took the row count in each chunk from 2000 down to 100 and still erroring out.
I really did not change anything other than maybe feeding more data, but the Chunk Loop is there to manage. Any help or pointer would greatly be appreciated. Thank you so much in advance.
I can tell you that this shouldn’t happen, as the policies “new rowkey”/“unique through postfix” are meant to prevent that. But the workflow might be able to continue without that group loop, because it looks like the Chunk Loop is within a try-catch-block.
I’m not sure yet what could cause this or where to look. It would be helpful if you could show more of your workflow. Sharing it, and some sample data would be optimal, but that depends on whether your company allows it.
You can attempt to create a workflow that reproduces that error in the most minimal way possible. Start by copy&pasting your workflow, then remove bits until you can’t remove anything else without fixing the error. That includes nodes, input data and settings.
Thank you very much , @Thyme. It’s comforting to know that your assessment is inline with my “whaaat and whhhhyy???” The data is probably a few gig worth so I’ll work to isolate that portion with smaller data set and see if I can replicate the errors. I’ll report back here. I’ll also continue to google/search here, but I really didn’t find any matching topics. Thank you very much, @Thyme !!! Have a nice day!!
Hello @Thyme , it’s a silly question, but I’m having difficult time figuring out how to take the data from the output table from JSON Path node to a new Table Creator node in a separate workflow file. I can filter the result from JSON Path node down to small. Export it in CSV or Excel and reimport it back? I’ll try that for now. I was thinking there may be an easier way. Tabel to File or Table to JSON nodes will do the same? I’ll need to try and see. Thank you!! Working on it now.
I really like the Table Writer Node. It dumps the entire table (exluding flow variables) into a file in KNIME format, meaning it’s fast and also keeps the data types. No messing around when importing!
The files are also the most compact. Only downside is that you can read it again only with a Table Reader Node.
@alabamian2 these things come to my mind. You could try and set a Cache node right in front of the point where there is a problem.
Then you might construct a unique Key by using this node (and you might combine it with a timestamp and number of the loop) and construct a new RowID from that. So the loop end would have a unique ID that does not have too much special charactes and is cached. You might also force the cache node to write it to disk. Sometimes with very huge operations it can make sens to give Java ‘a pause’ and collect everything nicely together with a good id.
Or you might save a RowID from before in a column and reuse that later …
@Thyme Thanks for the Table Write. I’ve tested with smaller scale in a separate new workflow and everything works fine without any error. I’m exporting the full data set via Table Writer and I’m going to put it thru the same sequences but in a separate new workflow file and see if the issue is related to something that has to do with increased size of the data. It’s taking a while to write the full table. Thank you again so much for your kind guidance. Hope you have a wonderful day. I’ll report back the progress. Thank you!!
Hi @Thyme and @mlauber71 ,
Thank you very much for your help. I was trying different things (including suggestions from both of you) and it kept running out of disk space on the server. I allocated more hard disk space and re-wired the problematic portion and it worked. I don’t believe I ended up changing anything (after all the tries and modifications) except the bigger disk space. I’ll monitor and see if this will continue to work.
Thank you again for your help and time. Have a nice weekend.