I am setting up a workflow that extracts the server logs through the API to monitor of my scheduled workflows on the server.
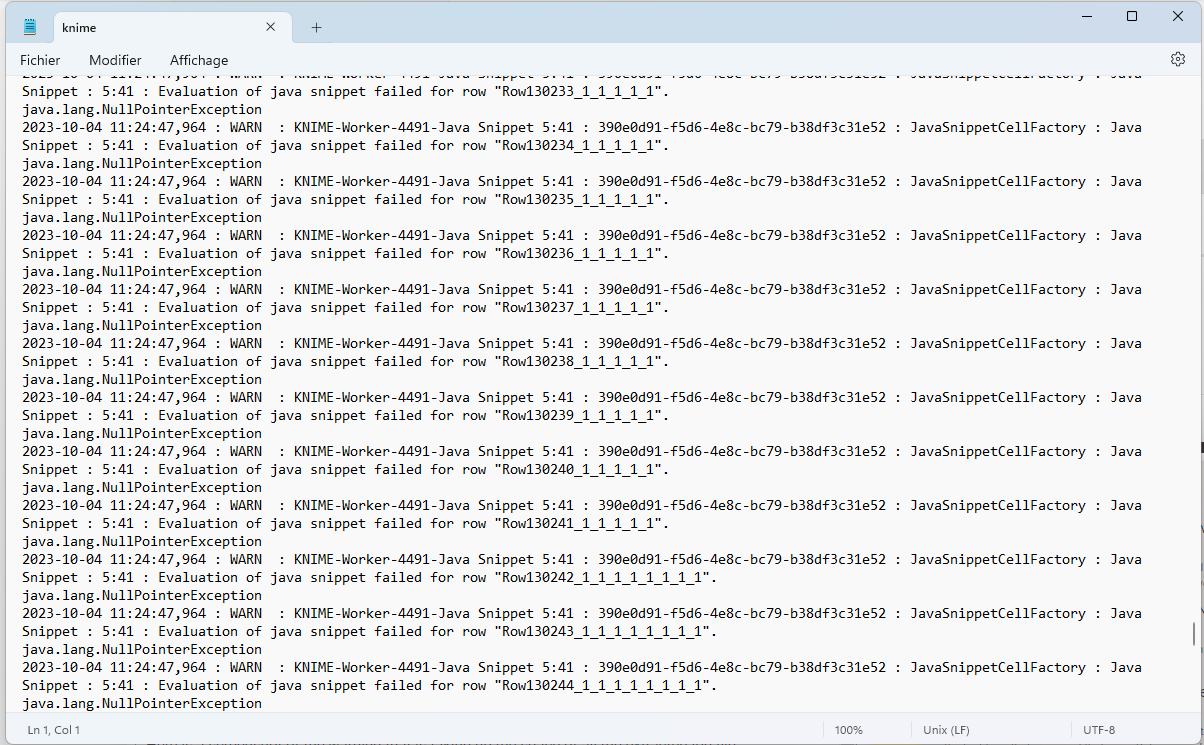
The problem is that I have a java snippet in a loop in one of the workflows that is outputting big amounts of warnings, for which I do not care, but the fact is that is overpopulating the executor log file and I cannot see the executor logs from the past days, even if I want to extract the logs from a month ago I see only the ones of today at the time that wf is run.
How could I either mask the logging of this specific node/wf or extract a bigger amount of the log files?
Here is a screenshot of the warning that is taking up the space of all the extracted log file:
Seems like this is called very frequently looking at the timestamps - so why not prevent the NullPointerException directly in your code? Quite likely all these log outputs and stack traces cause a performance penalty which could easily be avoided by adding an if (x !== null) ….
Thanks for the suggestion, I had thought about it as well and did exactly what you mentioned, I hope now there won’t be this problem further along the way.
However, there still is the problem that I cannot retrieve the logs which are older. Earlier today I managed to have the logs from 2 months ago but now I only have that timestamp, do you know if there is any way to retrieve the earlier executor logs or they are lost?
Thanks @qqilihq for answering half of the questions!
I’m gonna try to answer the second half and giving other details about logs:
Logs of workflows running on an executor would be stored in an executor’s knime.log file. The executor logs by default rotates out once it reaches 10 MB in size. [1]
This can be configured in the knime.ini with the following line according to your needs (100m means 100 MB): -Dknime.logfile.maxsize=100m
In case the knime.log file is missing, please see following setting in the server administration. [2]
com.knime.server.executor.max_log_file_timeout=<duration with unit, e.g. 30s> [RT]
Specifies the maximum time the servers wait for executors to send their logs files when they are requested by an admin. The default is 10s and is sufficient in most cases. However if you have executors with large log files or the connection to the executor is slow then you may have to increase the timeout in case some executors’ log file are missing from the downloaded archive.
It is possible to save the logs within the job folder via client profile. You may consider adding this line to your executor.epf file (or other .epf files) so that the workflow/job “log” will also be saved within the job itself. This is another way of saving the log files to a different location, and you can then also go back to just the workflow/job folder to find the log for that specific job. /instance/org.knime.workbench.core/logging.logfile.location=true
If you want to log all Workflow Job related activities (Execution Start/Stop) you may need to enable the Job Tracing ’ log. See for further reference how to do this in [3].
As for the logs that have already been rotated out, I’m afraid you can’t recall them.