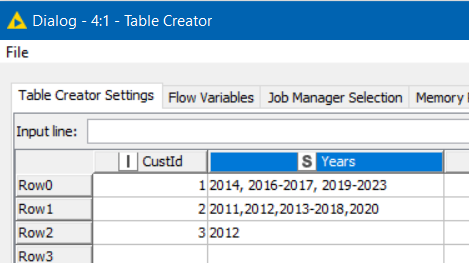
Problem:
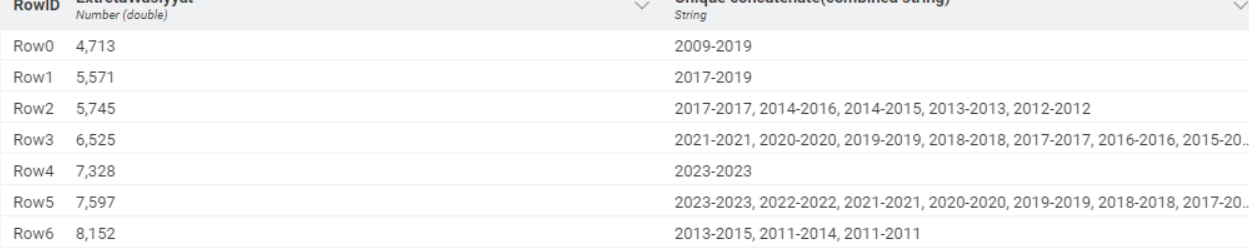
So for example customerID 8152 has set year ranges defined as: 2011-2011, 2011-2014, 2013-2015:
Solution
2011-2011 → column 2011 and cell gets populated with 2011
2011-2014 → columns 2011, 2012, 2013, 2014 and cells get populated.
2013-2015 → columns 2013, 2014, 2015 and cells get populated.
Note: There could be year gaps for some customer IDs. So its not necessary that a Customer ID will always have contigious years, but could have a gap year.
Totally lost on how to approach this problem.
I am a beginner with Knime ( learning on my own time for a non-profit org).
To add what @rfeigel already mentioned, in the first screenshot that is cut-off at the top, it looks like a unique concatenate aggregation is used to create that string.
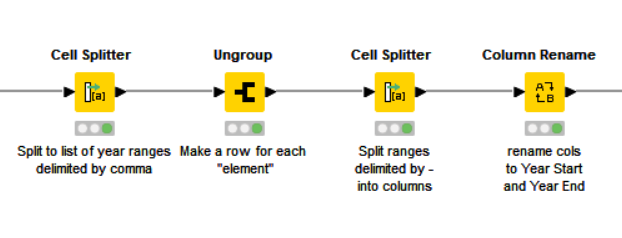
I have a feeling that getting your desired result is better achievable without this since one of the first steps you would have to take to get to a solution is to ungroup the list back again to analyse the individual date ranges.
So the more your can provide in a workable format, the better the chances are of getting the desired help
Hi @kit_kat, expansion of your years can be performed with a combination of cell splitters and ungrouping.
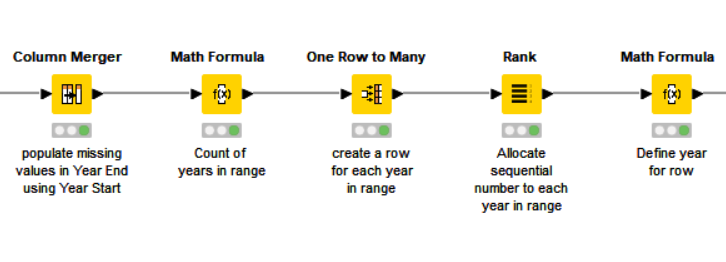
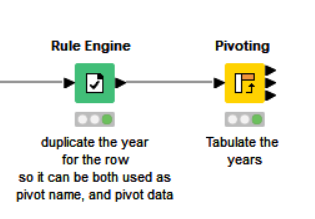
Generation of the range data (i.e. the years between start and end of ranges) can be performed using “math formula”, “rank” and “one row to many” nodes
CustID
CustA would get populated '2022 under 2022 column and ‘2023’ under 2023 column
Cust X would get populated under 2011, 2020, 2021 columns
CustY would get populated under 2018, 2019, 2023 columns.