I am new to KNIME, but I am excited about the software.
Now I have a problem that I can’t solve.
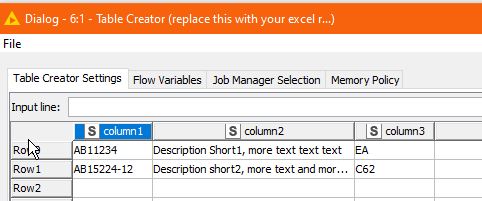
I have an Excel spreadsheet with several columns.
The cell contents have different lengths.
Column 1 = article number
Column 2 = article short text
Column 3 = unit
The cell contents have different lengths.
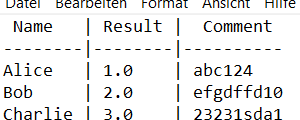
Now I have to create a txt file that looks like this:
If you need to rename the columns you can us either the Column Renamer or Table Manipulation nodes. Have you tried saving the file as txt inside Excel?
I expressed myself somewhat unhappily.
I have a KNIME workflow from various data sources. At the end I must receive a txt file with the structure shown.
I know how to create a txt file. But the structure with the borders is the problem. Also that the content has different lengths.
Hi @Elekrosch , I think I get what you are after. you want the output file to look physically like your picture, complete with all the lines.
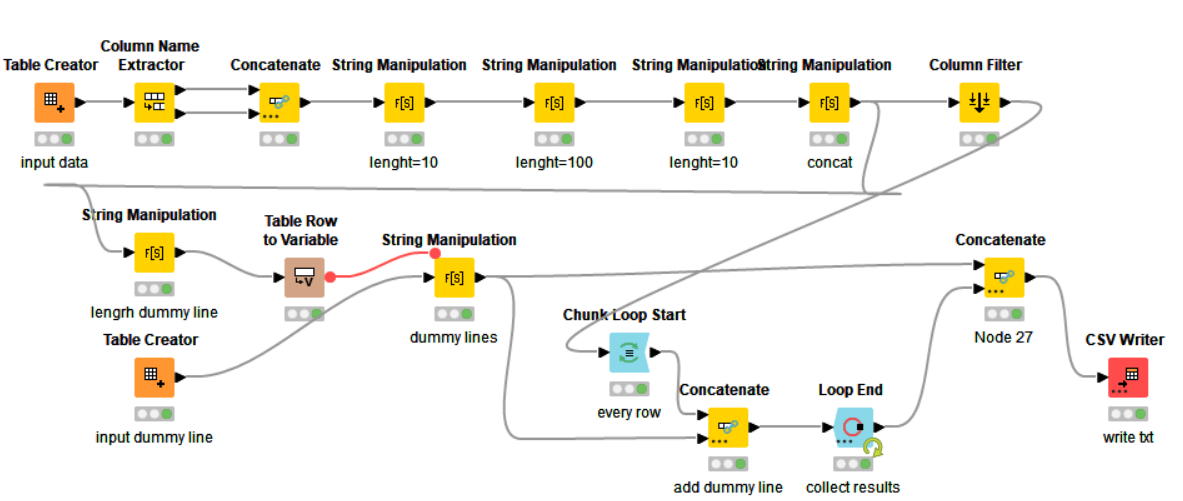
This is somewhat involved, but take a look at this workflow:
You will see at the beginning that I have just used a Table Creator to emulate your Excel file, and it simply outputs three columns column1, column2 and column3.
These are then renamed to the names you requested in the output file
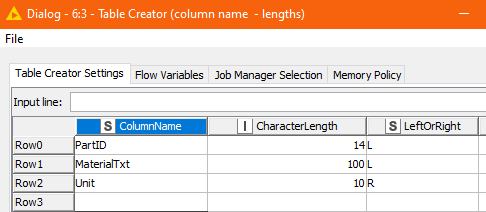
There is then a second Table Creator where you specify for each of the columns what you want the column width to be, and whether the data is Left or Right aligned. You can specify L, R and in fact C for Centre too.
The column headings are always centre aligned, as per your screenshot.
I have annotated the nodes so hopefully you might get an idea of what they are doing, and the method of processing.
The end result is this file, viewed here in notepad:
# This example script simply outputs the node's input table.
df = knio.input_tables[0].to_pandas()
outname = knio.flow_variables["FileName"]
# Function
def df_to_txt(df, filename):
# Spaltenüberschriften zentrieren
column_widths = [max(df[col].astype(str).apply(len).max(), len(col)) for col in df.columns]
header = ' | '.join([f"{col:^{column_widths[i]}}" for i, col in enumerate(df.columns)])
# Separator after heading
separator = '-|-'.join(['-' * width for width in column_widths])
# Data formatting
data_rows = []
for i, row in df.iterrows():
data_rows.append(' | '.join([f"{str(row[col]):<{column_widths[j]}}" for j, col in enumerate(df.columns)]))
# Bring everything together
with open(filename, 'w', encoding='utf-8') as f:
f.write(header + '\n')
f.write(separator + '\n')
for row in data_rows:
f.write(row + '\n')
# Write DataFrame to File
df_to_txt(df, outname)