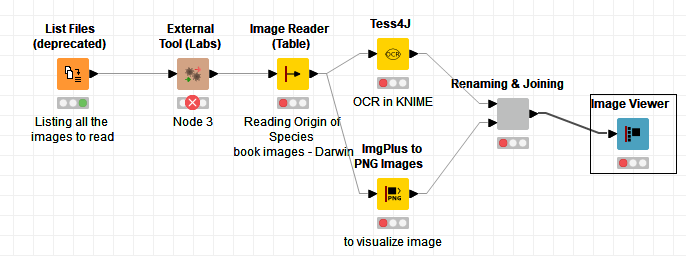
I want to convert by the way of “External Tool (Labs)” node each PDF files stored inside a directory by using poppler Open Source converter “pdfimages.exe” and read all the generated pictures (PNG files) to make OCR on the pictures files.
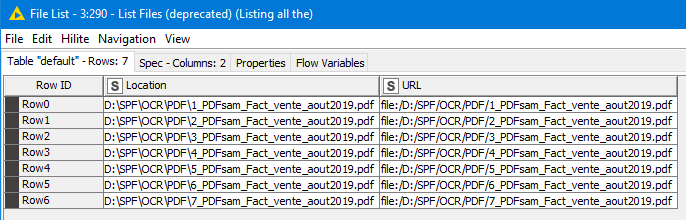
The first node create the list of all the PDF files:
I want to execute poppler converter on each PDF files (read from the table created by the “List Files node”) to convert these PDF files to pictures (PNG) files.
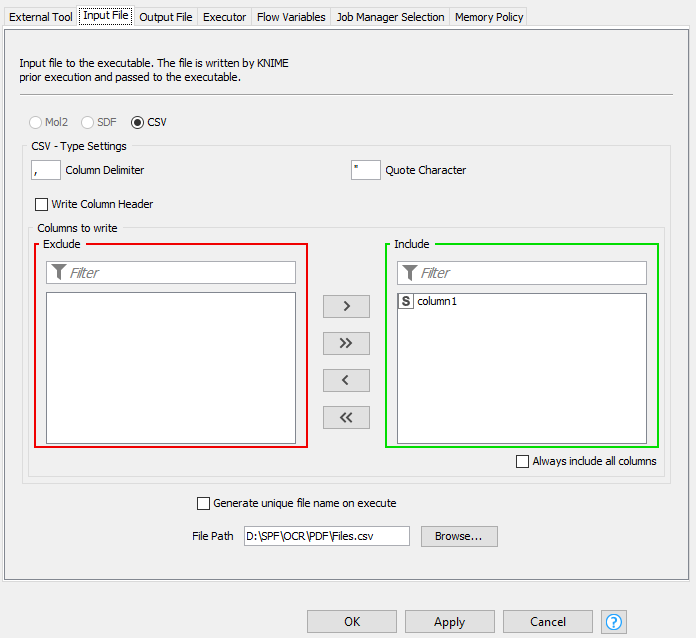
If I am not mistaken, the node actually writes the entire input table that you pass to the node into a file according to the configuration in the “Input File” tab. That is, you actually pass the path to a temporary CSV file to pdfimages.exe by using %inFile% in the Command line. Assuming that you would like to run pdfimages.exe on each row in the input table individually, you’ll have to work with a Table Row To Variable Loop Start node and create Command line by using a String Manipulation (Variable) node.
Here’s a great example that shows a similar approach:
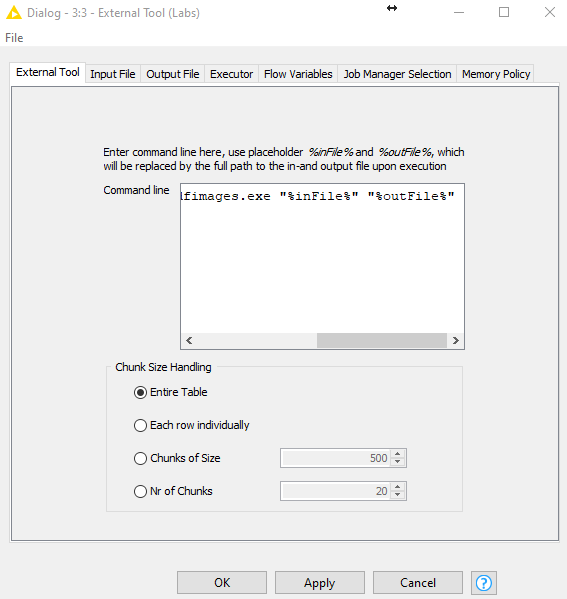
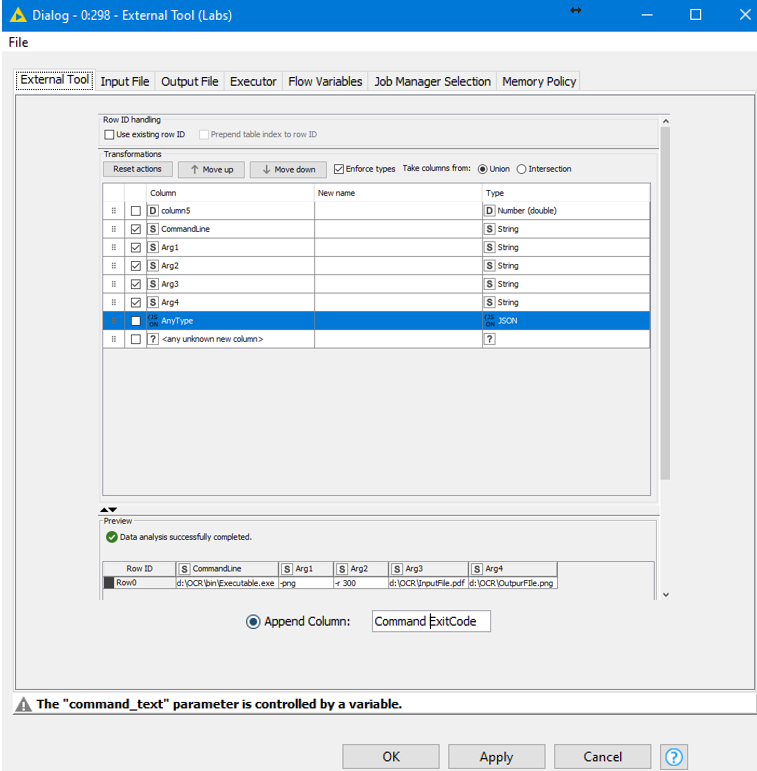
I thought the input file configuration check box “Each row individualy” of the External Tool (Labs) (see here under snapshot) send row by row to the command line executor when using %inFile% placeholder (as describe in the description of the External Tool (Labs):
External Tool
Enter the command line here. Use the place holders %inFile% and %outFile%, which will finally be replaced by the true path to the generated input file (input file = input data to the external tool = input data of the node) and the output file. Note that the command is executed as an ordinary system call. If you wanted to run the command in a (bash or tcsh) shell, you can call (for bash): /bin/bash -c “”.
You can partition the input data using the Chunk Size Handling panel. A separate process is spawned for each chunk of input data, e.g. if you choose “Each row individually” it will run as many processes as there are row in the input table. Note that the number of concurrent jobs can be controlled in the Executor tab.
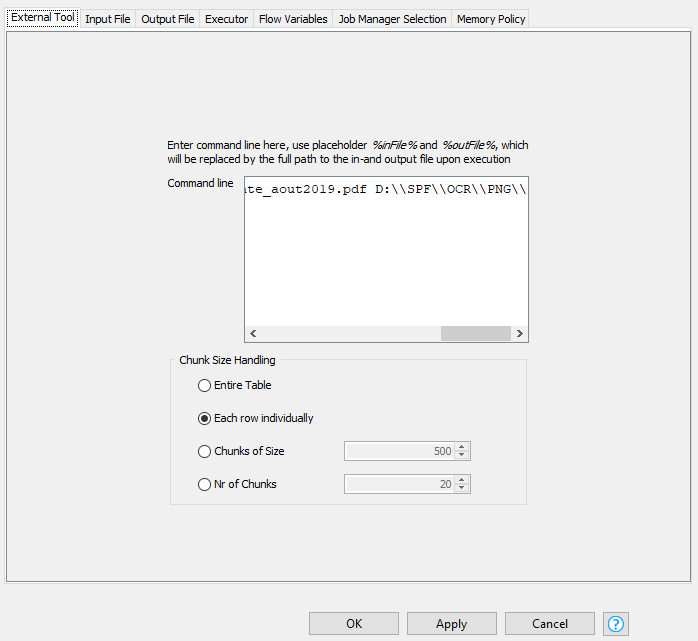
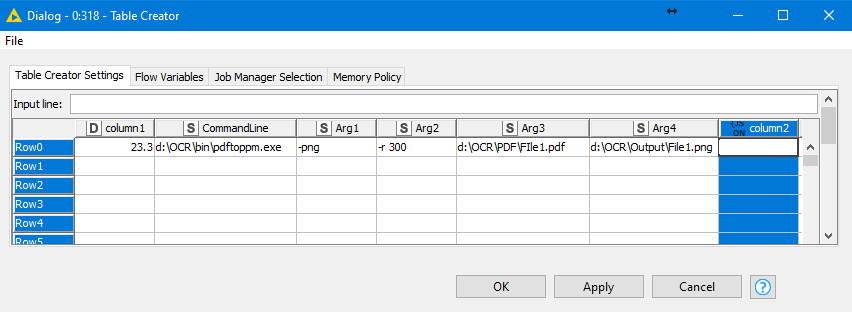
The node (see here under snapshot) runs with hard coded path in the command line: “D:\SPF\OCR\poppler-0.68.0\bin\pdfimages.exe -png D:\SPF\OCR\PDF\1_PDFsam_Fact_vente_aout2019.pdf D:\SPF\OCR\PNG”
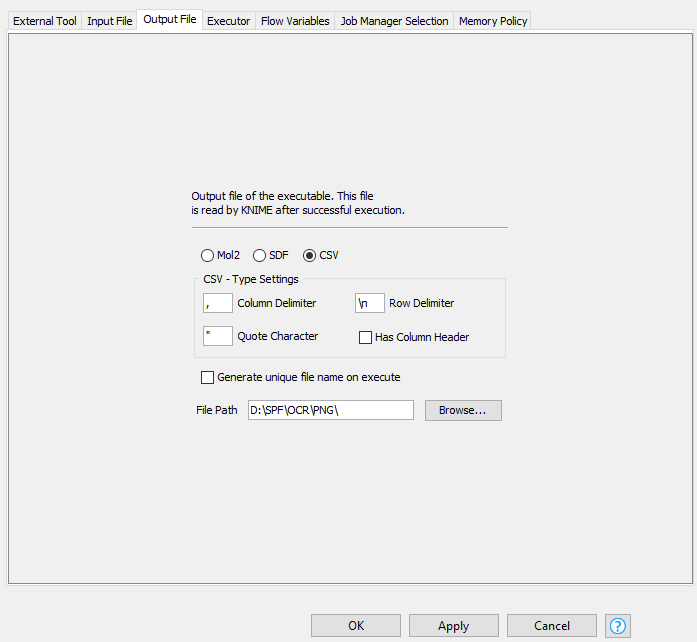
As there’s no textual output of the pdfimages.exe, I don’t see any output file (see here under snapshot) but the picture is generated in the right directory:
If I am not mistaken, the Files.csv file is deleted automatically after every execution of the node. However, I am not entirely sure how well not generating a unique filename works with chunking the input data: I would have assumed that for the chunking setting that you have selected, multiple CSV files are created – one for each process.
In any case, %inFile% and %outFile% are CSV files that contain the rows of your input table. So unless you write wrapper script for pdfimages.exe that reads the CSV file and calls the executable with the content of the CSV file, you will not get the file paths defined in your input table.
It should be interesting (and logical) to have a line by line independant execution.
Because why to use a CSV file with multiple lines?
A table could be more interesting (each line are passed to the commandLine executor).Even If it’s string, path or any other kind of data, it will be passed to the executor, line by line. As output, a table is created by each execution as binary content. By this way, the external Tool can be perfectly integrated in the KNIME phylosophy.
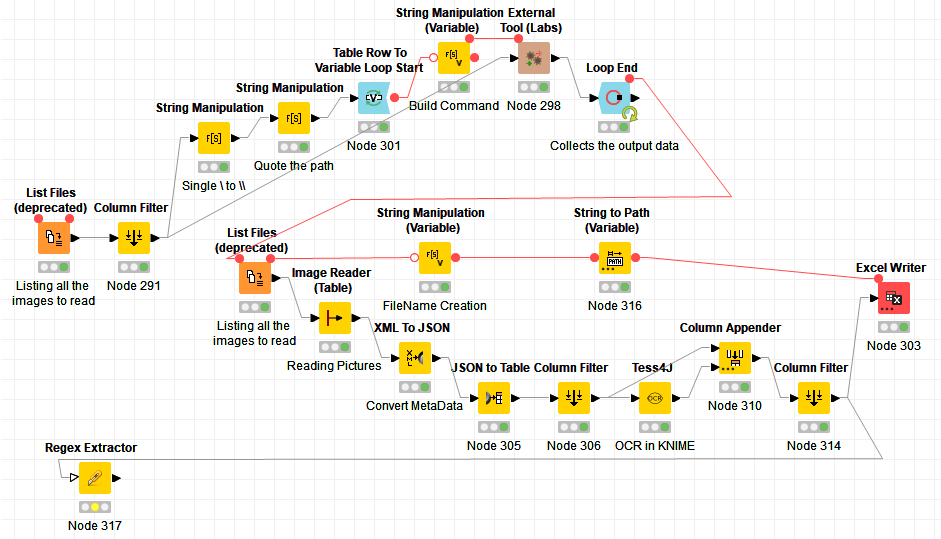
You can find the workflow I found to convert PDF files into pictures (PNG) and generate (OCR) strings. You can see the Tess4J don’t pass the input tables. It could be interesting the Tess4J node passed throught all other columns.
I am not sure that I get what you are saying, @PBJ. The CSV files that are written to disk for each process are essentially tables (or at least structured similarly). I assume that the node has been written with applications in mind that take large CSV files (100K rows for instance) and output tabular data. In this scenario, chunking makes particular sense if the application that you are executing doesn’t handle memory sensibly and just crashes when the input table is too big. With the chunking you would only ever pass smaller input tables to the application.
In general, it would indeed be great if there was an alternative way to the workflow that you are showing…
The use of a table in the KNIME sense makes it possible to pass it through the node and as indicated in the configuration of external tools (Lab), it is possible to segment the processing of the table to avoid resource problems such as you explain it. The selected column is executed by the External Tools (Lab) node and built previously to correspond to the executable input.