I’m trying to create a flow that will do a few things:
Parse some pdfs (about 280 of them)
Extract keywords that I choose
Count the keywords and match them with the file name, per column.
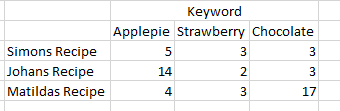
The output should look something like this:
As you can see, I want to know how many time the word, say “chocolate” appears in each pdf, so I can later rank the files by, for example, “the most chocolate-y”.
I’ve gone through most knowledge bases here and even got somewher on my own but I guess Im just too old/slow to make this work on my own … Anyone care to help me out? I would be so thankful!
For your use case I would use the text processing extension of KNIME Analytics Platform. Are you familiar with text processing?
My idea would be to
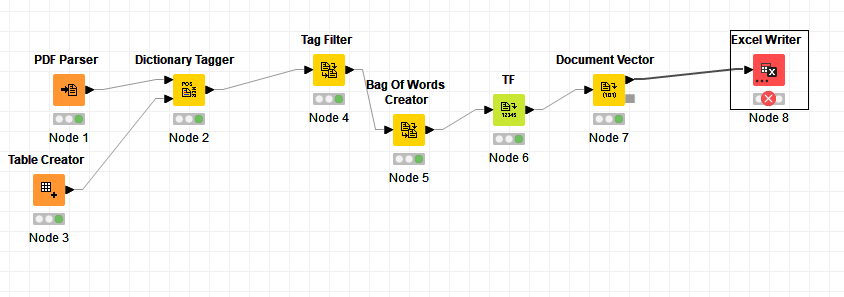
Use the PDF Parser node or Tika Parser node to read your PDFs (in case you use the Tika Parser node, you need the strings to document node in addition)
Use the Dictionary Tagger node to tag all your Keywords
Use the Tag Filter node to remove all words which you didn’t tag
Create a Bag of Words using the Bag of Words Creator node
Use the TF node (stands for Term Frequency) to add a column with the information of how often a keyword occurs in a document
Create a Document Vector with the Document Vector node (here it is important to uncheck the checkboxes “Bitvector” and “As collection cell”.
The result should be similar to your table
Please let me know if you need more information in one the steps!
Cheers
Kathrin
PS: Between Step 1 and 2 you might want to clean up your documents, e.g. by lowercasing everything.
ERROR Excel Writer 3:8 Execute failed: The input table at port 0 contains exeeds the column limit (16384) for XLSX.
Any ideas why this might be happening?
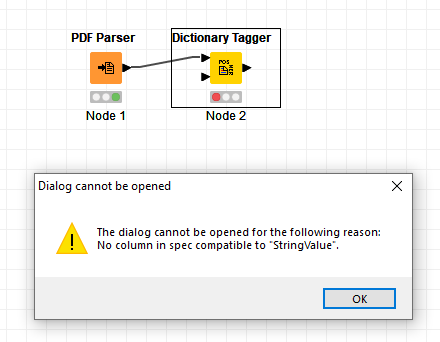
EDIT: Looks like its making each keyword in the entire document into a column … I think i messed up in the table creator -> dictionary tagger setup. How should I structure the keywords?
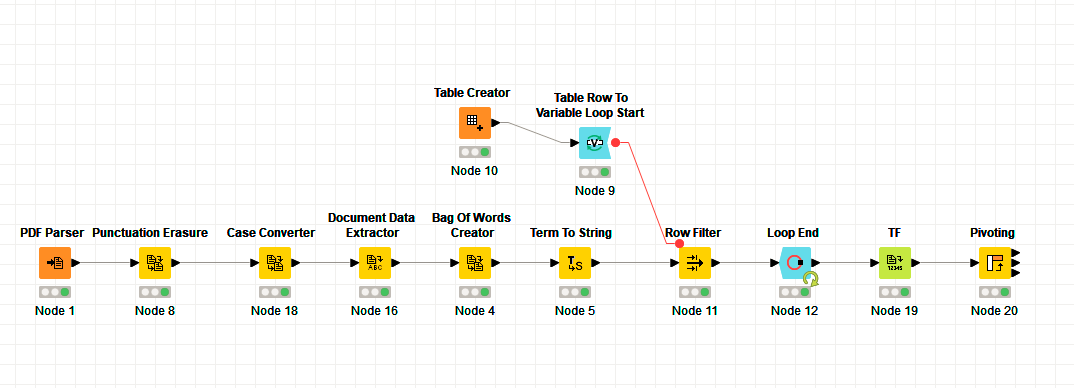
You need to use instead of Document Vector Tag to string and Pivot nodes. The error you have because you included the document not the document name. TF node has to keep Filepath column. Use it as document name.