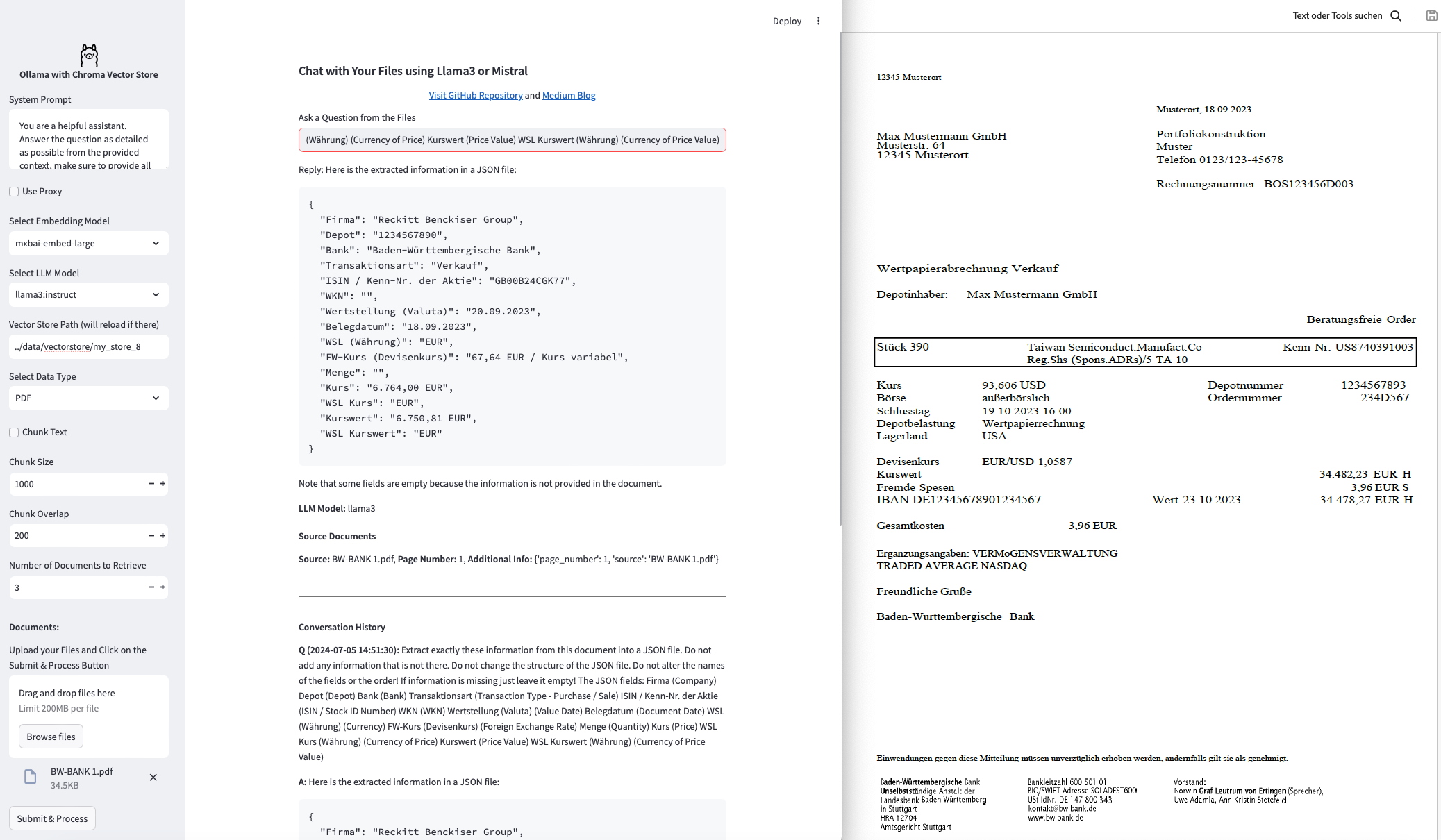
@jannikw99 I set up a workflow to extract information from your PDFs with two different LLM models (Llama3, Mistral). From what I saw it will make sense to work on the prompt for example adding a passage about making sure the JSON structure is valid and avoid nested data.
Your PDFs are from different banks and contain different sets of data like buying different products (stocks and bonds). I focussed on the first bank and stocks and I assume it will take some work on the prompt(s) to be ready for several different versions. It might be necessary to have different prompts for different banks. I think it is also possible to employ LLM models to construct the prompt to use. You could set up a two or three step approach where you set up the fields you want and then send some documents per bank and ask the model to provide a prompt for this bank. An even more advanced set would be to employ agent systems like crewai.com to ‘battle out’ the best prompt - though it might be difficult for the system to judge what is a goof result.
I might write a whole article about this but let us dive into a few steps of the workflow.
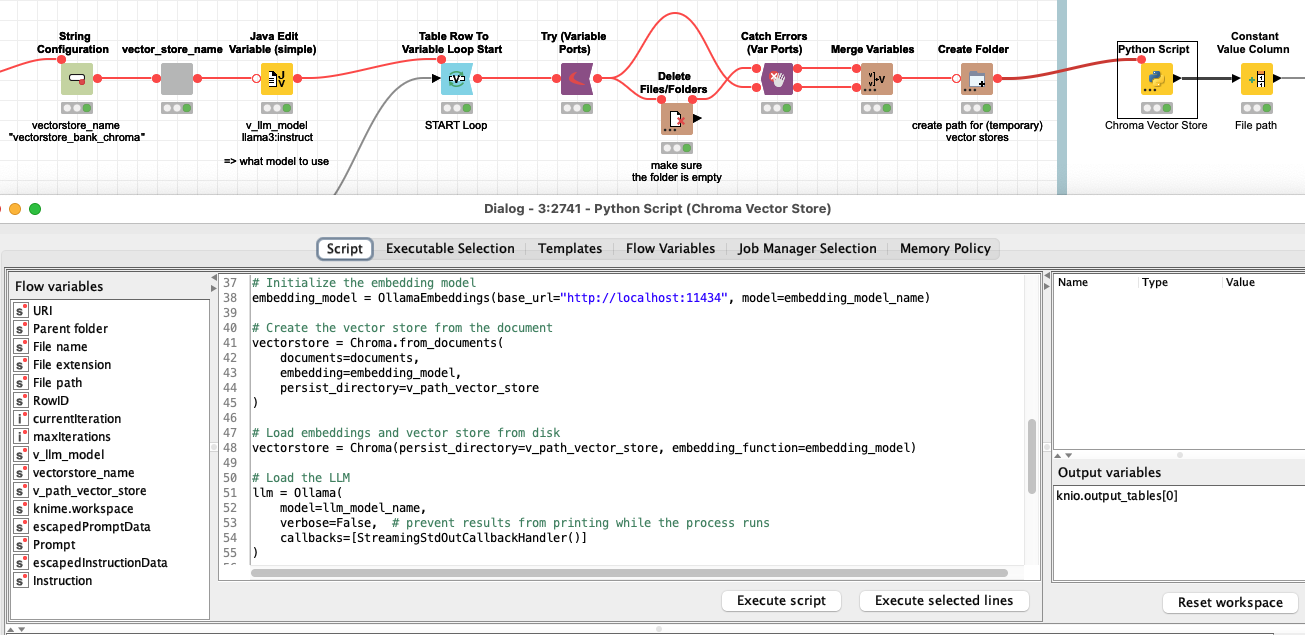
Scan the PDFs in a folder and provide an instruction and a prompt and also set which model you want to use. I have two lines in the workflow. One using Chroma and on FAISS vector store. I have used Llama3 and Mistral - both have interesting results.
Each individual PDF (or other document) will run thru the Python node and will be embedded (with mxbai-embed-large) and then will be put to the LLM model in one step.
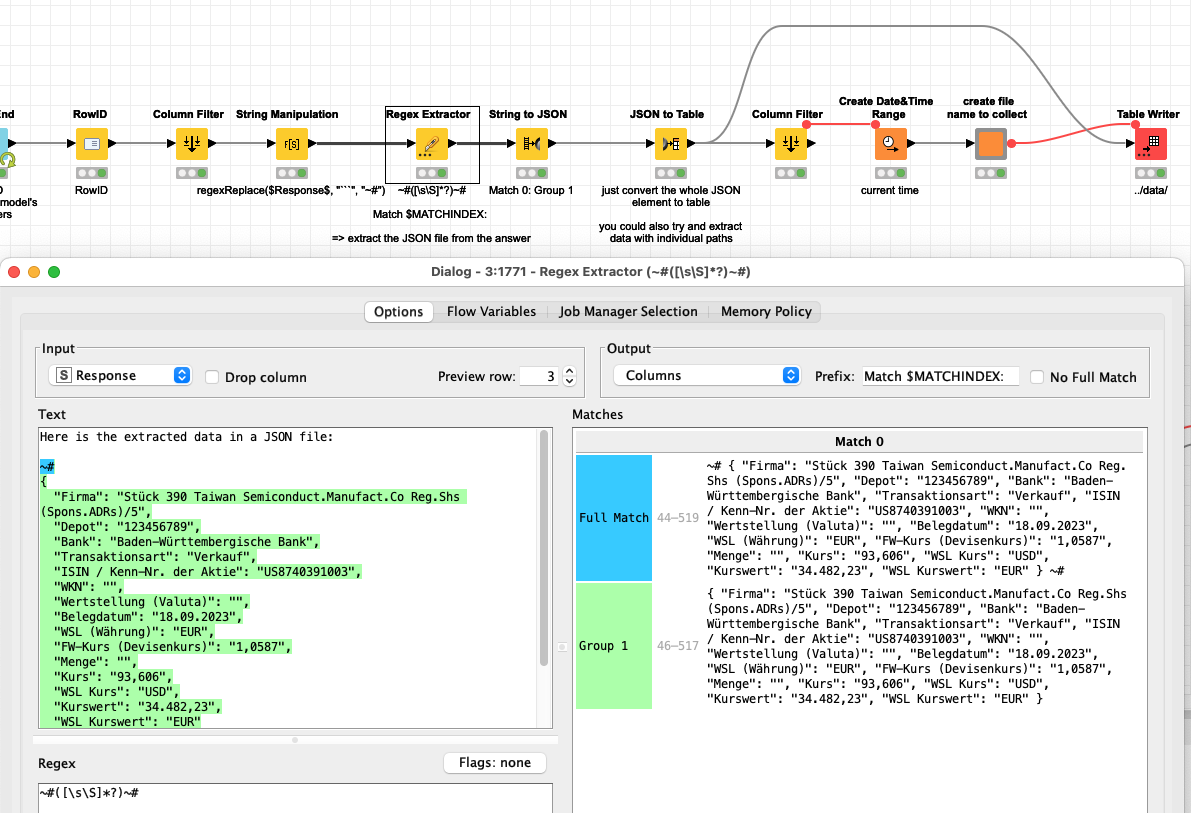
KNIME will later collect the results which are in JSON structures and will be extracted into a simple table. It seems both LLMs are able to provide a quite good result. If you are missing fields you might have to provide a more detailed prompt:
Mistral seems to be good at providing just the JSON although sometimes some fields might be slightly different so you can use KNIME to make sure the structure is the same (and deal with missing fields later).
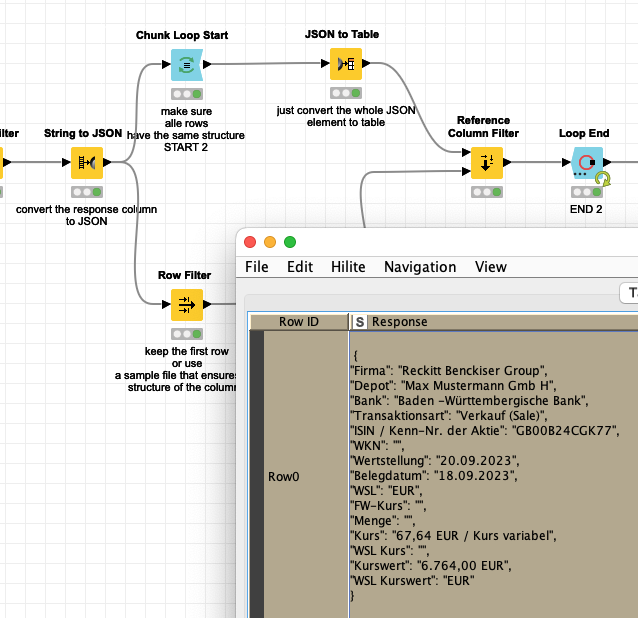
In the end the results will be in a table like this:
With regard to process you could now compare the results of the two models - you might have to do some tweaking of formats and column names - and when both models agree you can use the results for example.
You could also think about a four steps approach where you now use the compared results and provide that along with (again) the vector store and ask the model to try and find missing information.
I am not sure if an approach might help to provide a sample of other PDFs as a pattern. I tried to experiment with that in the Streamlit app but was not satisfied with the result. It might be that a one shot approach for extraction and relying on what the LLM ‘knows’ internally might be OK.
One idea could be to include some general description of what the files might contain in oder to smooth the process (“you are about to see bank statements in german with stock purchases and sales …”). This might be slightly hindered by the anonymised nature of your public bank files since they might not contain the real structure of addresses, names and so on.
At this point (again) a reminder that all this is taking place on your local machine. I was quite satisfied with the speed of my Apple Silicon M1.
This example will run on KNIME 4.7 for the sake of compatibility within my organisation. I think I might provide a similar example using more recent KNIME nodes, GPT4All and KNIME 5.3 - so to have this in a more knime-like way
(maybe best to download the whole workflow group)