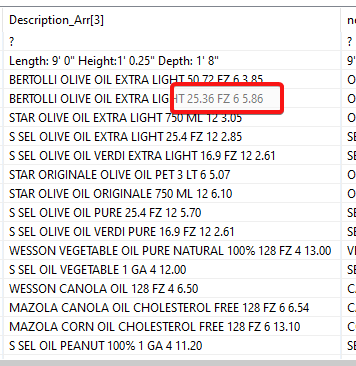
This one always plagues me during my data manipulation. I have no problem extracting data from the left to right. However, my data that I want to extract is often on the end or in worse case in the middle. The real challenge is that the string is dynamic, so a cell splitter based on spaces just creates a jumbled mess to work through. In the case outlined below, I do know that I need the data from the right of the string based on spaces (always 4), but not character counts (too dynamic). I have tried the String Manipulation with a “-4” but it just removes the first 4 characters. I have played around with ReGex, but to no avail. Basically looking to find the 4th space from the right & extract only the characters. I know I am making this way too hard…
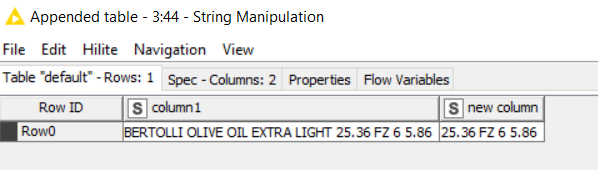
to extract the last 4 groups of non-blank chars you can use this regex in a String Manipulation node regexReplace($Description_Arr[3]$, "^.+ ([^ ]+) +([^ ]+) +([^ ]+) +([^ ]+)$", "$1 $2 $3 $4")
and then you can split the output string in a Cell Splitter node using a blank delimiter
If the regex doesn’t match $Description_Arr[3]$, that is, if $Description_Arr[3]$ contains less than 4 blanks, it returns the entire $Description_Arr[3]$. You can filter out these cases after the split, because the rightmost column (the 4th group) will contain a null value
Hope this solution works for you
Square brackets allow us to list several possible characters ([0-9] stands for any digit)
inside of square brackets, ^ negates that selection ([^äöüÄÖÜ] stands for any character except Umlaute)
outside of square brackets, ^ means at the beginning of a line; $ denotes the end of a line
Don’t forget to select @duristef’s post as solution
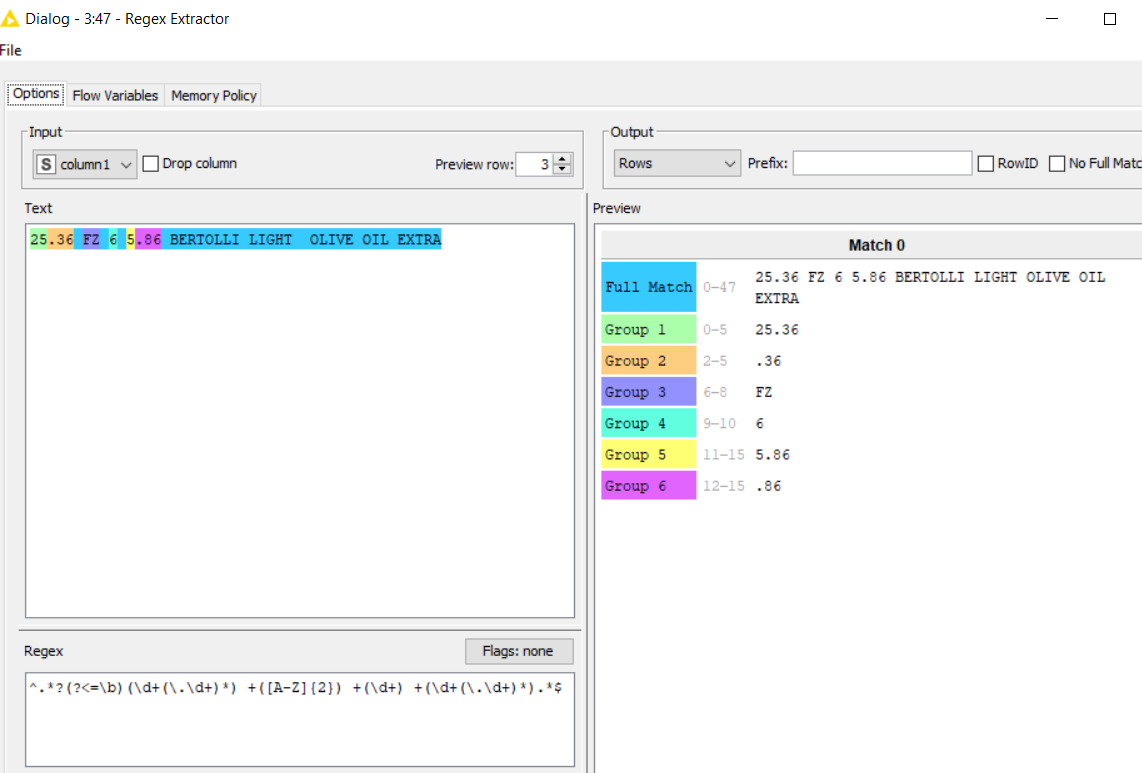
Thanks @Thyme @davehansen , in your case: ([^ ]+) is a capturing group of non-blank chars. I replace the original string with the four rightmost groups of non-blank chars separated by one or more blanks. It would be difficult to capture the same groups would they be placed in the middle of the string, unless they had a well-defined pattern. For example, you could capture a sequence like this
beginning of the string
zero or more chars
Group 1: only digit(s) or digits,dot,digits - preceded by a word delimiter or at the beginning of the string
blank(s)
Group 3: exactly 2 uppercase chars
blank(s)
Group 4: digit(s)
blank(s)
Group 5: only digit(s) or digits,dot,digits
zero or more chars
end of the string
using this regex (which works in the former case too)