Hi, I’m trying to extract reviews from the website glassdoor with Selenium nodes.
I created the following to begin with the extraction of the title only, but somehow it always skips (a) page/s. I don’t see why.
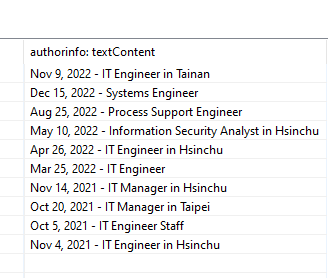
When trying the same for extracting the Job title and date, it skips a lot of entries and also they are not in the correct order. Any idea what could be wrong?
Thanks for your help.
Hi @knndcc
It’s almost impossible to troubleshoot this by just looking at the nodes you use. Sharing the workflow would help a lot here ![]()
3 Likes
Hi @ArjenEX, oh you are right, sorry.
Also for your information, this is my first workflow, with Selenium nodes. Still a beginner, so might have some things not correct. FYI, After the first 6 nodes, I need to log in to the page.
gd_scrape.knwf (72.3 KB)
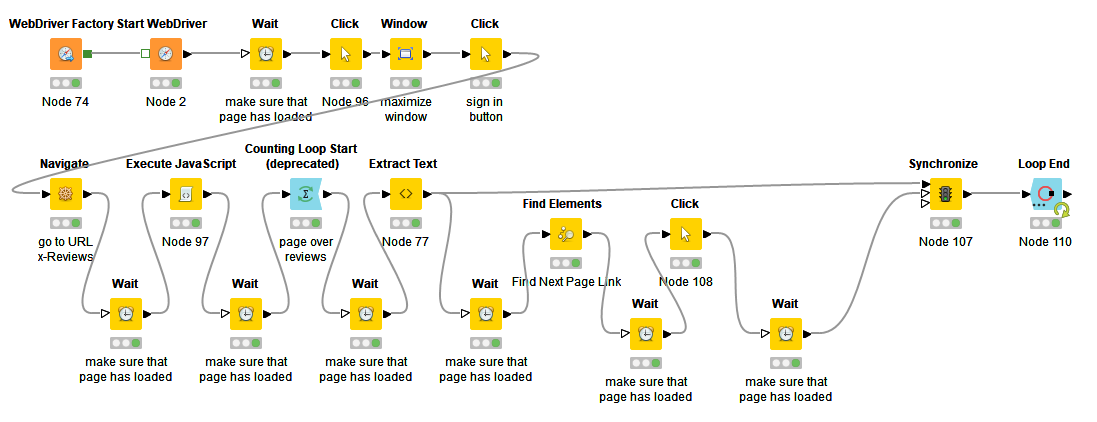
an issue seems to be that the click-node seems to be in a loop, even when I set it as “Extract first match only”. @ArjenEX, any idea why that could be?
Thanks for the workflow. I’ll have a look later.
How did you bypass this annoying problem of the login pop-up showing up at random times every single time the workflow runs?
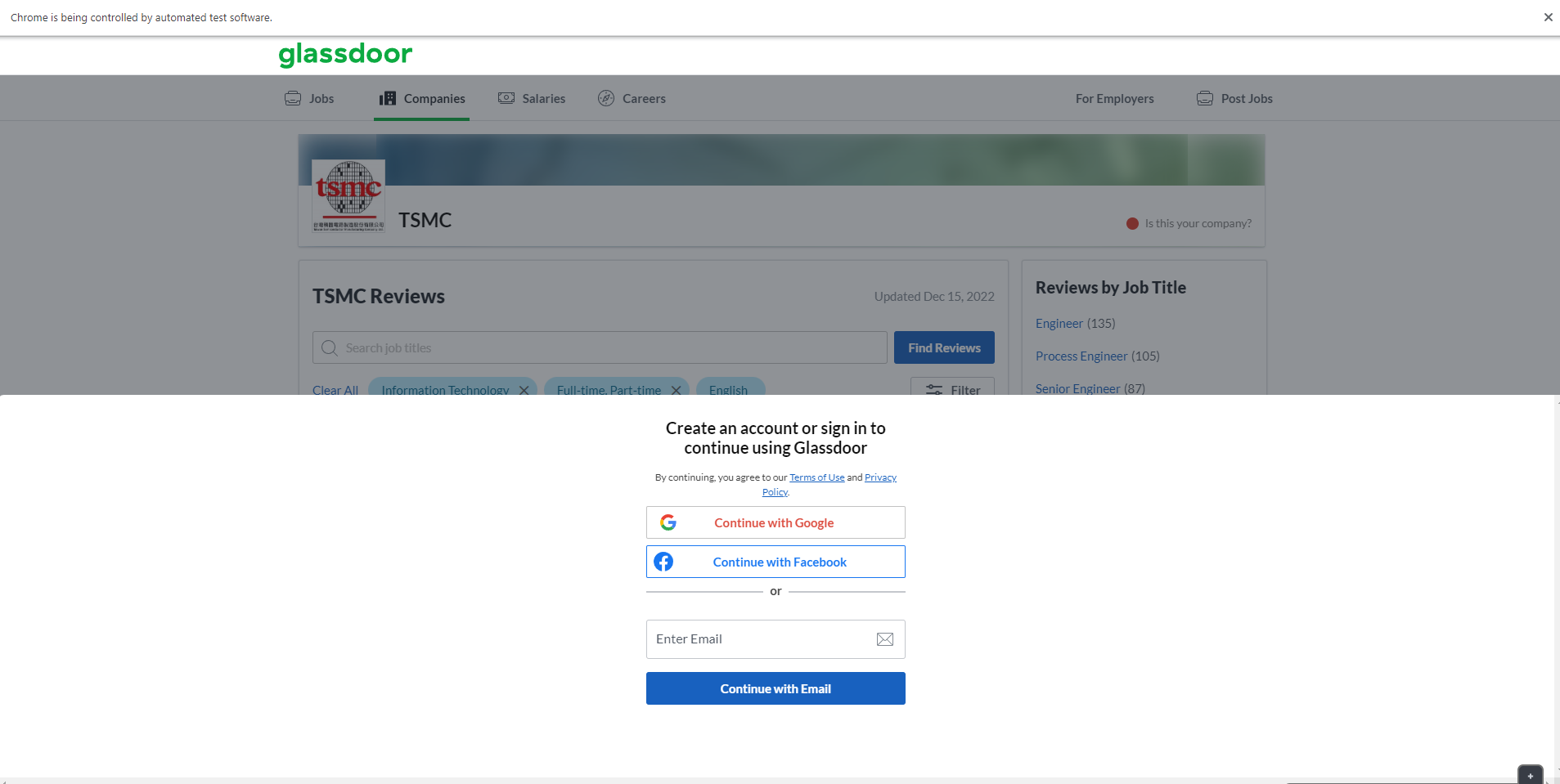
The text is fine in terms of extraction but this login keeps interfering the proces.
@qqilihq Is there anything that can be done within Selenium to prevent this? It looks like the <div class="hardsellContainer">
@ArjenEX After the first 7 nodes (first row) I’m logging in, the pop-up doesn’t appear anymore once I’m logged in.
I have shortened the workflow a little bit, but my problem now is that the “Click” node is like on loop. And because of that it’s not able to extract all data correctly.
gd_scrape.knwf (72.4 KB)
With an Execute JavaScript, you can easily remove any DOM content (such as login nags, cookie banners, newsletter sign up, etc.)
For example locate the Element using Find Elements and the run the following JavaScript:
const element = arguments[0]; // activate element to remove in the left bar
element.parentNode.removeChild(element);
Best,
Philipp
1 Like
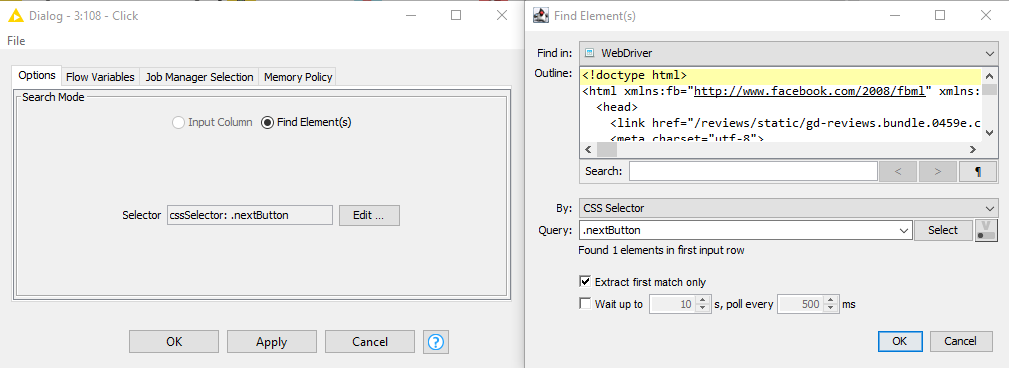
Please ensure that the “Click” node only operates once per iteration - currently you input several rows into the Click node, thus the clicks will be executed several times.
For this, connect the Click node to a table with only one row (i.e. at the loop’s beginning), or switch the Click node to the “Input Column” mode an build your selector there (this is probably cleaner and you won’t need the previous Find Elements node then).
HTH,
Philipp
1 Like
@qqilihq Thank you, putting the Click node at the beginning worked. I just had to extract the first page outside the loop and then combine it with the loop. Do you know if there is a possibility to extract multiple fields at once? I would need to have the ‘overall star-rating’, ‘date & job’, ‘title’, ‘pros’ & ‘cons’
Hi knndcc,
You’d need to do that sequentially - typical recipe: Use a Find Elements to extract the wrapping <div> element etc. for each part you want to extract, and then operate within these elements as context to extract the detail information you describe. This way you get a consistent structure.
Hope this helps!
Best,
Philipp
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.