I'm trying to build a workflow to extract the domains from a given list of URLs. I'm using Knime because I'm not a coder and it allows easy integration with MySQL where the URLs are stored.
The Python Script community node seems to be a good bet to do this. I trust Python's url parsing more than something I could do with the String Manipulation node.
There aren't many tutorials, templates or even forum topics that deal with the Python Script node, but hopefully a python jedi will answer this post and show us all how to do it.
Hi, I have to extract only the short domain from an URL and der URI node just gives me the full domain part and I did not find any similar problem in the forum yet
I would use regex to trim everything to the right of the 3rd “/“, then do a regex split by “.” (Or regex to trim everything left of the 2nd “.” From the right) , then clean it up with a simple formula in the Column Expressions node.
I am still doing a lot of trial and error on RegEx test websites for things like directional character counting, but I am sure one of the RegEx masters on here can just shoot from the hip and give you a formula.
First of all, there is no such thing as the “short domain” What you are looking for is what’s commonly referred to as the domain name or simply domain, though this is also not entirely accurate (hence why I said “commonly referred to” - the proper term is the “root domain” or “apex domain”).
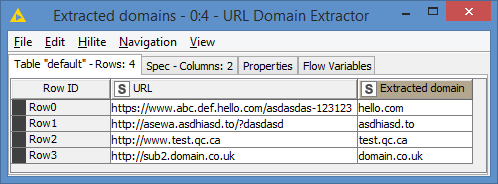
www.hello.com is a subdomain of hello.com for example, and asewa.asdhiasd.to is a subdomain of asdhiasd.to.
Looking at what @iCFO , the idea is good, but unfortunately not all domains follow this structure, so it will not work with all domain names. UK urls for example have domains that ends with .co.uk or .gov.uk (e.g: yahoo.co.uk) for example. Canadian urls also have this kind of domains, for example .qc.ca (e.g: etatcivil.gouv.qc.ca)
So, the proposed solution would not work.
Palladian offers a node called URL Domain Extractor that does exactly what you are looking for:
This is an example of the node in action:
Palladian is a very useful extension and offers a lot of tools. I would strongly recommend getting it. However, sometimes there are company policies that do not allow “external” extensions to be installed, and if that is the case for you and can’t get the Palladian extension, you can check what @takbb did there without the Palladian extension:
Awesome node share @bruno29a! In general I always find myself defaulting back to manually solving problems like these. The regex would have gotten pretty complex if it needed to handle domain structures differences that you highlighted, which is a massive time waste vs this solution. I am going to take some time and explore more of these “specialty task” nodes.