I have a very specific question. I’m wondering if there is a way to extract the number of elements from the molecular formula? Let’s say the molecular formulas are:
C6H12O3S
C12H35O4Cl
C8HF17O3S
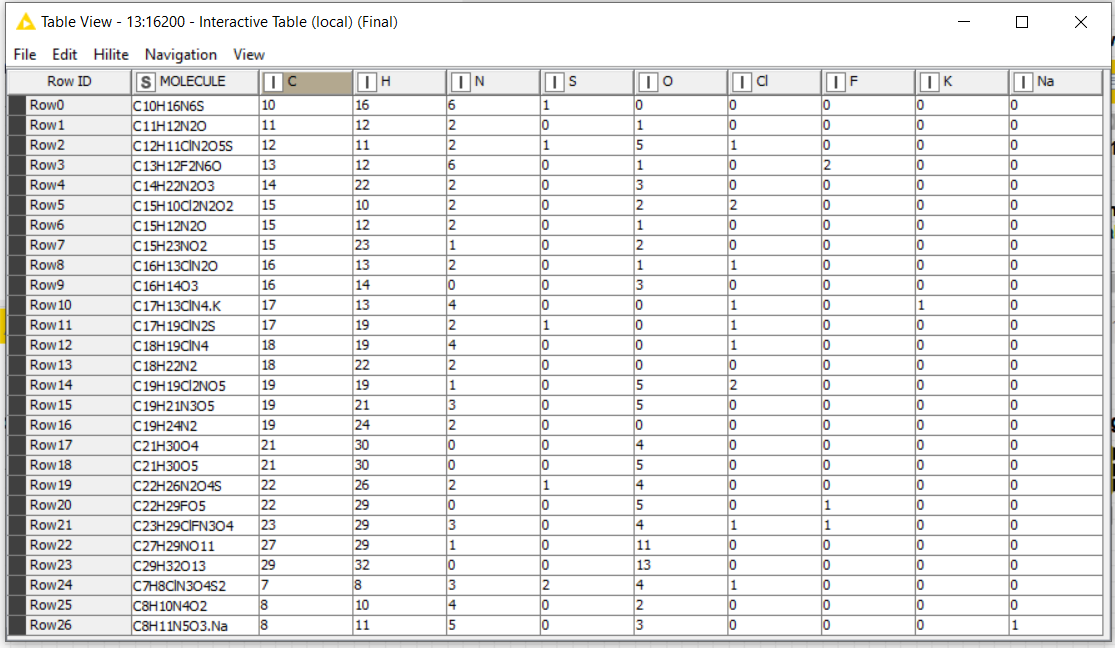
and I would like to end up with something like this:
If you only have the molecular formulas, then you can try modifying this workflow to loop over all the common atoms and append the results as new columns
If you have chemical information (SMILES, SD file, etc), you can use a substructure counter node and SMARTS queries to do this.
Can you share the data you plan on using for this?
Complementary to @elsamuel approach, please find below a possible solution based on regular expressions. It is generic and accepts any Atom from the periodic table. It can also handle salts or mixtures separated by “.” (or not) if this is a requirement:
Sorry, this file contains these counts. However, I am going to use an in-house database and those counts are not included there due to the space limitation. This is going to be a part of the workflow that I am working on… Sorry for confusion.
@Amanda252 I think that any of the approaches here could work.
However, if your molecular formulas are not rigorously validated/cleaned then any RegEx-based solution will cause problems. For example, the file you shared has formulas such as C10F21CHCH2 and C10F21CH2CH2SO3H and C11F23CFCHCOOH which are hard to parse. Things like organic salts could also be problematic.
The workflow that @aworker shared has difficulty parsing formulas like C11H5ClF9NOS and C11F23CFCHCOOH.
I’m always partial to using actual chemical information, i.e. the SMILES or SMARTS or chemical structure directly.
Thanks a lot @Thyme for completing with the regex explanations. Please feel free to improve the workflow too and to post it back.
I understand @elsamuel comments. Actually I didn’t start from @Amanda’s excel file but from a list of public smiles from which I calculated the INCHI codes and extracted the atoms with counts as in my molecule examples. I’ll provide tomorrow the little extra piece of workflow to make the algorithm robust to the failed examples but @Thyme already wisely solved it in his explanations (step 6)
Helas It’s getting late here and i’m answering from my mobile phone. More tomorrow
@elsamuel@Thyme@aworker Thank you for a quick responses/comments/suggestions. I couldn’t use actual chemical information because for most of the data I have no information at all and that’s why RegEx-based solution works well for my purpose.
Ok, so I took a look again (it was late at my place as well), I found out that the different RegEx expression is actually necessary (+ the summation at the Pivot node). @Amanda252’s example has "-" in the molecular formulas, so those are removed as well. The rest is pretty much the same (1 String Manipulation node got split into 2, to reduce the neural RAM usage).
The sample input is now also processed and the results compared against the existing values. Ael’s solution with my modifications works, but there’re 2 molecules that have wrong values in the Excel file:
C11-F14-O2
C11-H13-F13-N2-O2-S
I should mention that this does not work with duplicate values (=molecular formulas)! To remedy this, a different ID column should be used as grouping column in the Pivot node (e.g. the column “name” in the excel file).
The workings are not changed, so I won’t explain that again (see above), but I can mention the general idea behind this: The molecular formulas need to be fragmented into its parts. This is done in two steps, both times with the cell splitter. The String Manipulation is used as helper node. All of this is done to bring the data into a format that the Pivot node understands.
Now starts the tl;dr part.
Table Validator (Reference):
I like to use it to resort columns by reference and insert missing columns. Can also check data types and optionally fail. Multi-node node that’s especially handy before a Table Difference Finder.
Table Difference Finder:
Compares two tables cell by cell. Any differences it finds will be in the first output. If it doesn’t find any, the output will be empty. It’s very literal though, so the RowID and ColumnNames have to match exactly, or you’ll get lots of unmatched cells. Most of the nodes in the lower branch prepare the tables so they look exactly the same. It’s a bit of a snob. 20220215 Pikairos Count Atoms Ocurrence in Formula - modified by Thyme.knwf (239.7 KB)
I was working in parallel early this morning to make the workflow more robust too but you already did it with great improvements !
Thanks a lot for your comments yesterday which improved a lot the behavior of the algorithm. I’m posting here my version that I modified in parallel to yours because it has other features too, for instance it shows how to start from SMILES or from IUPAC instead of from Molecular Formula. I’m eventually verifying and comparing the results starting from different sources too, so this maybe a plus too. I believe both versions are complementary.
It is a pity that there is not a KNIME web collaborative common space where we could share on-line a workflow to improve it interactively. Maybe in the future? This would be a super feature !
Indeed, it would be nice if with the new upcoming KNIME versions based on a fully implemented web interface, a kind of collaborative web server space is added too ! Finger crossed !