Hi friend,
I would like some help to extract all values from a PDF, to export to excel after.
Hint
The only different rule is for the last value, that the information “ICMS-ST INTEREST DE SP PARA RJ 102016” could be anything or null.
The code will need to search that point and bring some value tha could be with any lenght character.
could anyone help me?
I’m not know anything about regex, and I know that regex is the best option for that.
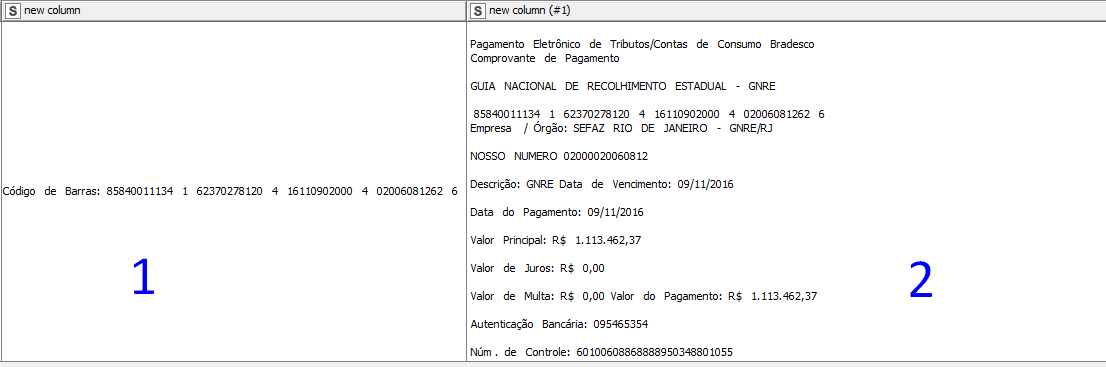
The first one is exactly what I want, but without the name “Código de Barras”. I only want the values after “:”
So, I tried the second code, creating a “group” with (.*) and calling with “$1”,. But why the result is showing all values?
I didn’t find the right rule.
I studied a great explanation from @takbb about some rule I “copy cat”.
@Felipereis50 at the end of the above article there is a YML file with the necessary configurations in Python to use the packages. You can also use the Conda Environment Propagation if you have the KNIME Python extension installed.
@Felipereis50 what will be the ‘rule’ that will define this part of the text? I had good results with putting examples and rules to ChatGPT and ask for a Regex format.
You might have to double escape backlashes in KNIME though. Also you might want to test several edge cases and think about what could go wrong.
I have tried to ChatGPT in various ways of questions.
I’m 4 hours trying to show only that content in knime column but nothing.
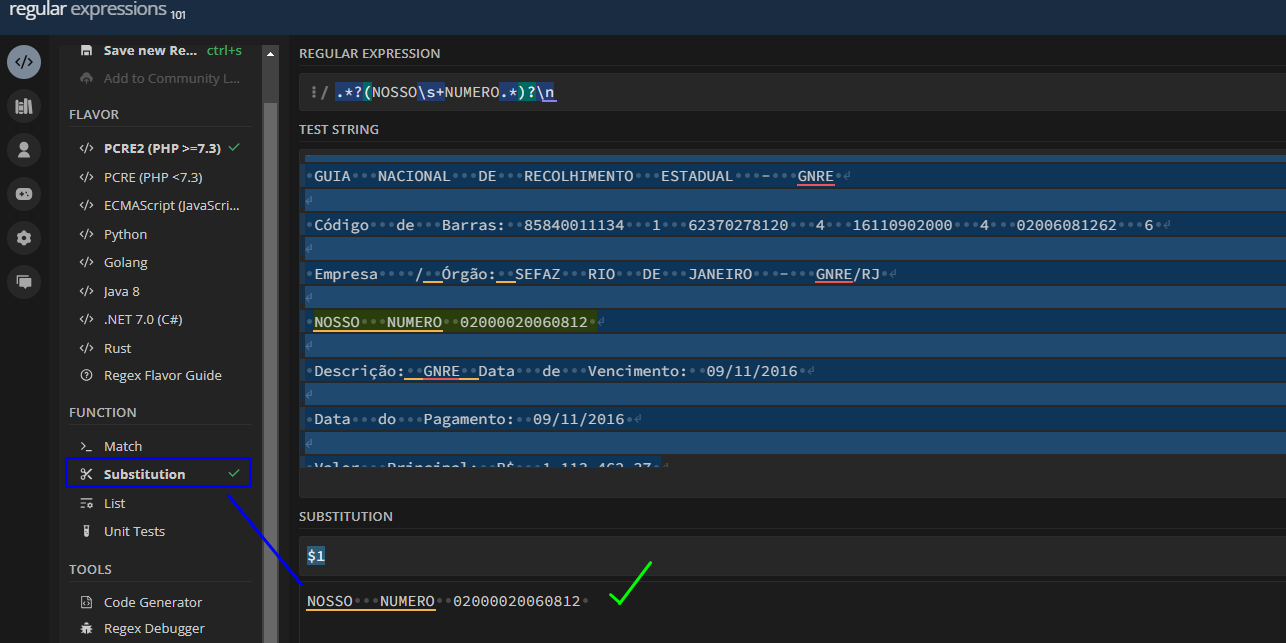
I managed to extract some values when capturing the entire line.
But since I need to capture only a part of the line, I can’t finish it in Knime.
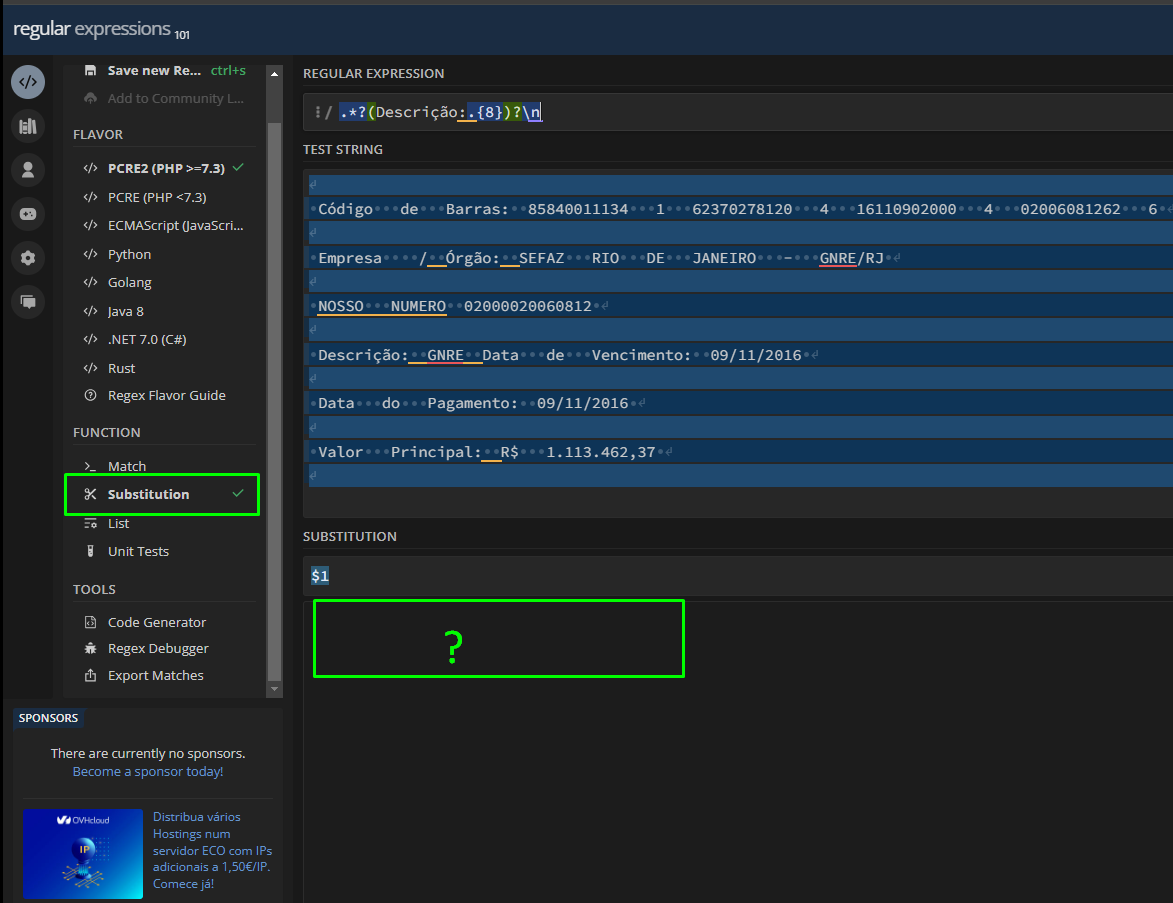
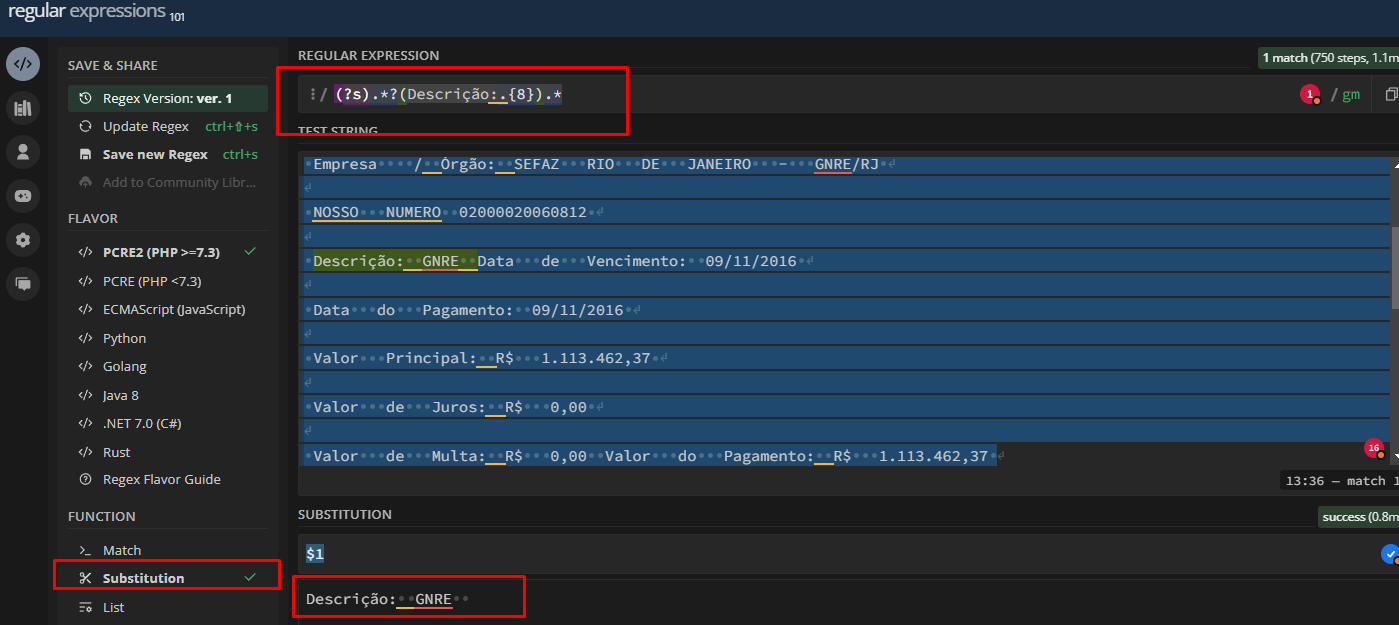
I need to complement the Regex so that only what I want is highlighted in green and the rest in blue, just like the example above. But I think because the middle of the line doesn’t have the new line character, the function doesn’t work.