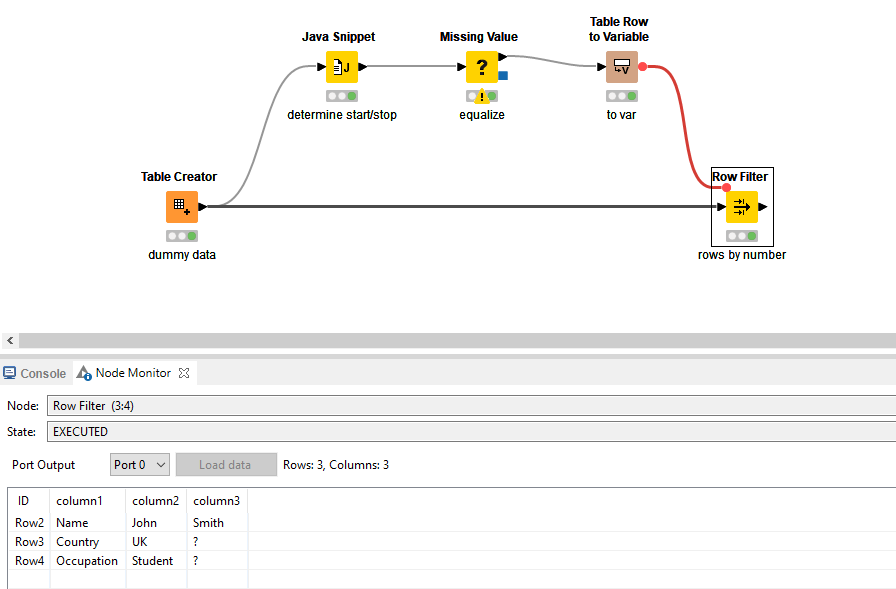
I have an Excel file that I only want to extract specific rows from. More specifically, I want to be able to extract the rows where column A contains a specific word until column A contains another specific word.
For example,
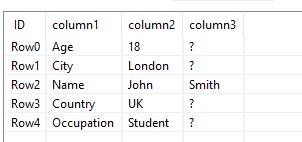
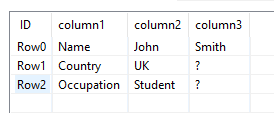
Col A | Col B | Col C
Name | John | Smith
Country | UK
Occupation | Student
So in the example above, I want to extract the rows from Name to Occupation. However, the position of this row can vary between different Excel files (i.e. in one file, it could be row 20, and in another, could be row 100), and there could be multiple rows in between Name and Occupation.
Is there a way to do this please? Thank you for any help you can provide on this.
This is definitely possible, but a question that comes to mind: How should the start and stop point be determined? Are those fixed values, should the user input this manually or is it determined somewhere in your script? The answers to these questions will determine what a suitable solution could be for your use case.
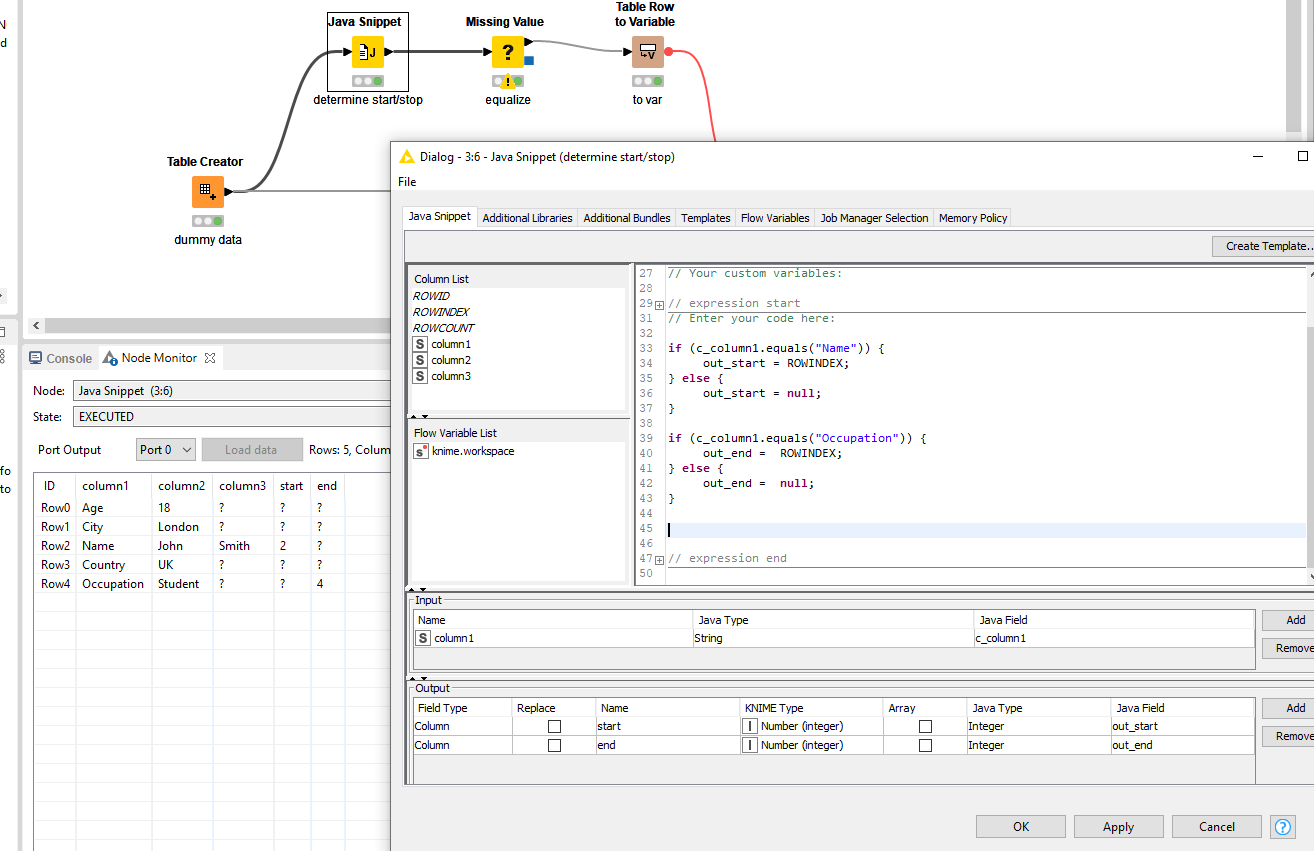
First, determine where the start and end values are located within the table. You can do this by looking for the RowIndex of “Name” and “Occupation”. I opt to use a Java Snippet for this since this attribute is included in there.
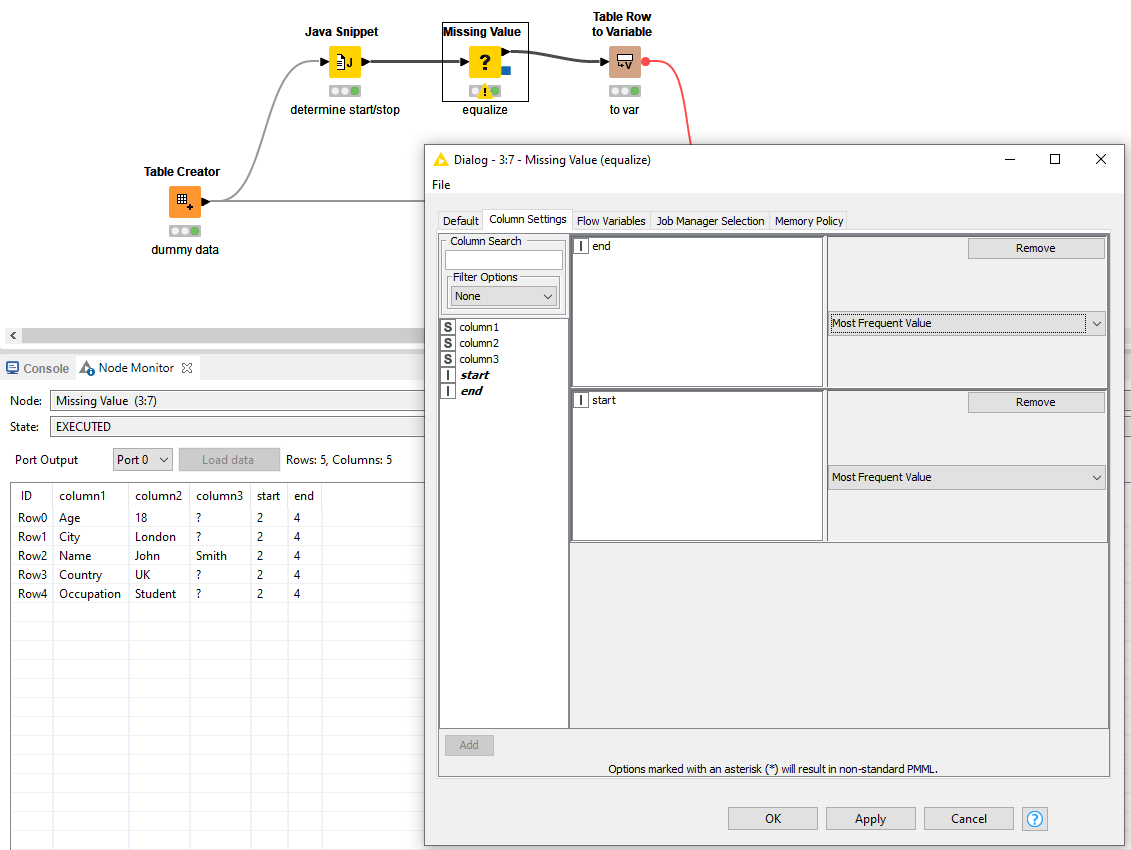
Note: make sure that the output is of type integer. Now I know it’s between row index 2 and 4. To equalize all values of the start and end, a Missing Value node can be used.
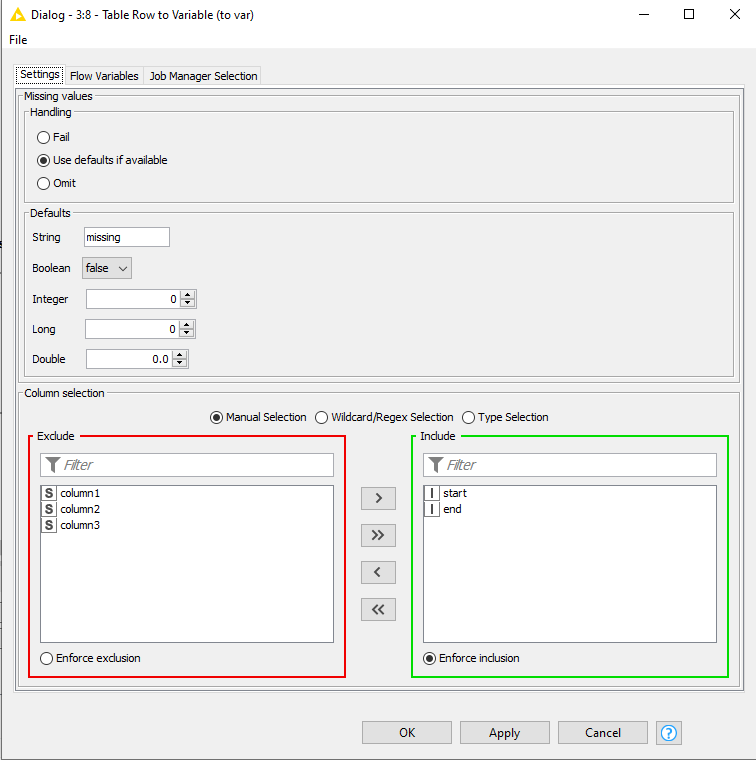
You now have the start and end determined dynamically which you can subsequently use in a Row Filter. Connect the variable output to the row filter.
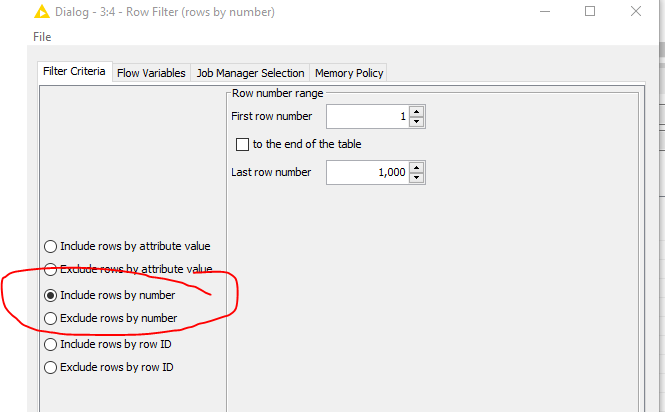
In here, there is an option to filter based on rows by number.
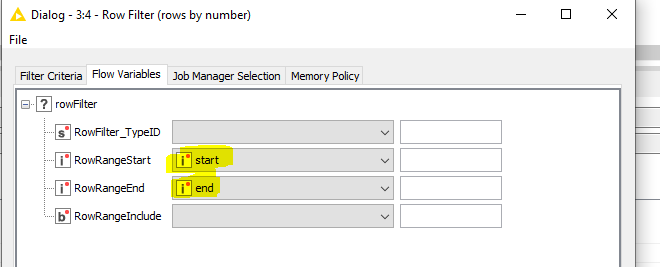
To use the variables created earlier, navigate to the Flow Variables tabsheet and select the start and end variable for the RowRangeStart and RowRangeEnd
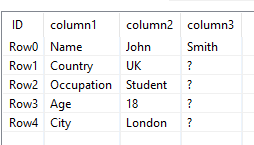
With input:
The output is:
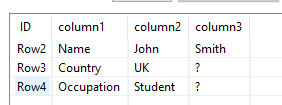
Another input in a different order:
Output:
Note1: this approach assumes that the “Name” and “Occupation” only appear once. Note2: this assumes that “Name” and “Occupation” will appear in this particular order.
Therefore, depending on your actual dataset this has approach may has to be tweaked a bit!
I wish the Row Splitter node had similar options to the Row Filter node… I nearly always split instead of filter. The Row Filter node has some interesting options built into it for situations like this, while the Row Splitter node seems to basically just be a duplicate of the Rule Based Row Splitter with a different presentation.
stumbled on this thread today. With the new Table Splitter – KNIME Community Hub used twice should do the job. First split off the rows before Name. With the second node split off the rows after Occupation.