Thanks for your support over a period. I have been able to learn of new things which has increased my overall productivity. I have been trying to extract some data from multiple PDF’s from 2 weeks, but I hadn’t got any success. So I did it manually, but now since I have the time I wanted to understand who can I extract specific data from PDF.
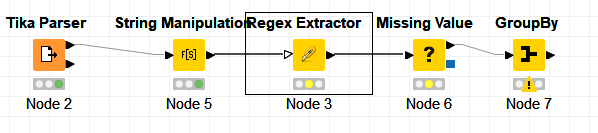
I have seen the example pdf_extract.knwf (57.8 KB) which matches with my case.
I understand that I need to follow this sequence to get my data.
The problem i have is I am not able to generate the regex to extract my specific data.
I need to extract
Name of the Trust - Page 1
Income of Trust estate - Page 2
Total tax losses carried forward to later income years - Page 3
Can some please help me creating the regex code for this. Hopefully, which this I will be able to understand extraction technique and then I can add few more items that I need to extract?
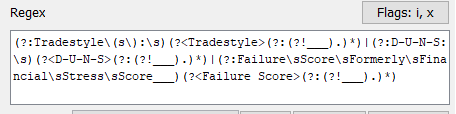
(?:Name of trust)(?<NameOfTrust>(?:(?!Australian business number).)*)|(?:Income of the trust estate A\s)(?<IncomeOfTrustEstate>(?:[0-9,])*)|(?:Total tax losses carried forward to later income years J[\s.,]*)(?<TotalTaxLosses>(?:[0-9,])*)
Description for further expressions: (?:Name of trust) - anchor before your value (?<NameOfTrust> - name of your value (?!Australian business number) - anchor that terminates your value (if needed) (?:(?!Australian business).)*) - matches your value with the terminating anchor (?:[0-9,])*) - matches your value without terminating anchor (digit and thousands separator)
‘|’ - separates your values
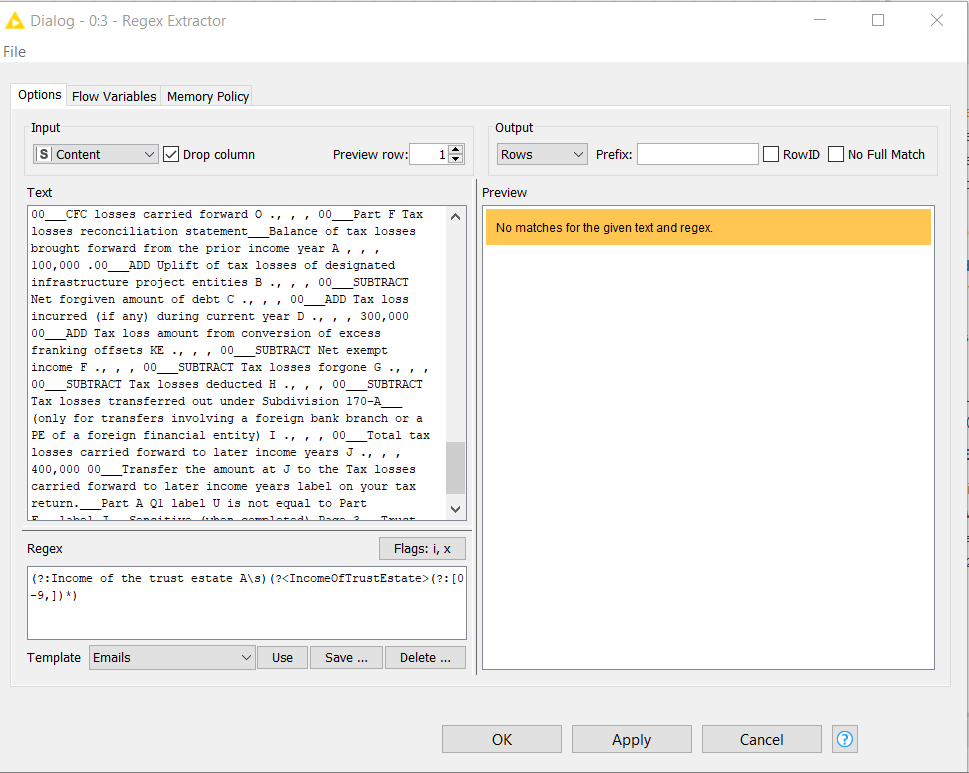
Thanks Andrew, Thanks for explaining me the logic behind the regex code. However, it does not seems to be working. I was trying to test 1 line at a time but none of them seems to be working.
Thanks a Ton Andrew. I did’t knew what Flagging does, but thanks for point me to the right direction. This helps me heaps. Never thought I could do. Really love knime