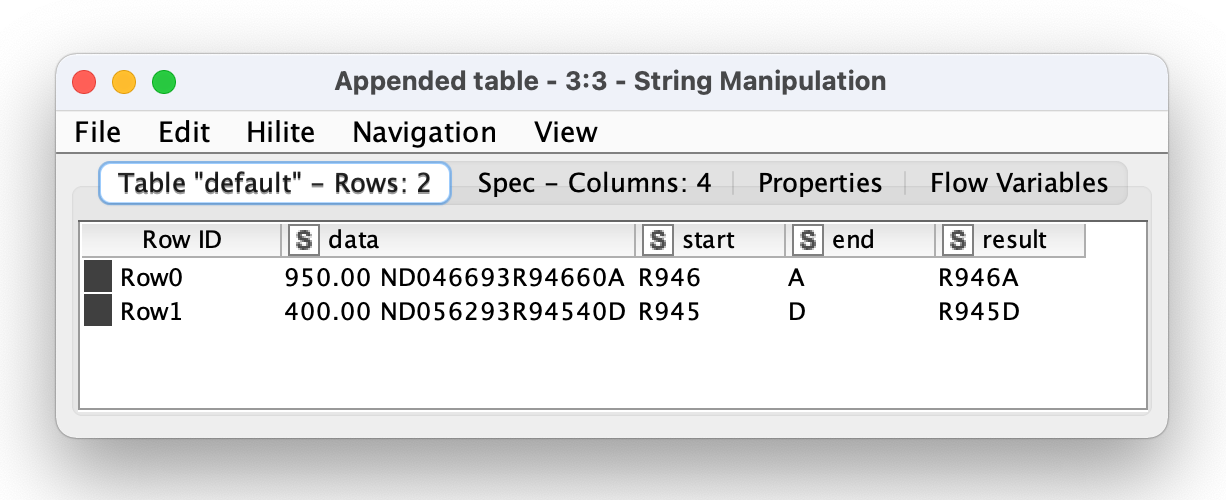
I have a column that contains rows of mixed double/strings that looks like this:
950.00 ND046693R94660A
400.00 ND056293R94540D
From the first row, I’m hoping to extract R946, and then the last letter, A, to make R946A.
From the second row, I’m hoping to extract R945, and then the last letter, D, to make R945D.
The R is constant with every row, and the extracted quantity of characters is always 4 plus the last letter.
Have wrestled with string manipulation, cell splitter, and regex, but haven’t been able to crack this nut yet.
Hi @wisemanleo with just 2 sample rows, and them being similar in structure, does not give any idea of how the data looks like.
There are a few ways to do this, but some would depend on the data structure.
If the positions are always fixed (same amount of characters, and the R is always at the same position), you can directly use the substr() function.
Otherwise, you could still use substr() but with combination of indexOf() function to get the position of R, that is as long as you only have ONE R per row.
(?<start>R\w{3}) # letter R followed by three digits
\d* # arbitrary number of digits
(?<end>\w) # one letter
As there’s characters in between which are not relevant, I’m extracting the prefix (e.g. R945) and the suffix (e.g. D) separately. Then you can join them into one string using the String Manipulation:
The substr() is probably much faster than regex, as regex would need do to a search. But the direct use of substr() only works if the position is fixed.
This (via String Manipulation) join(substr($column0$, 15, 4), substr($column0$, 21)) should do
You guys are all awesome and hilarious with the meme as well.
The position of R appears fixed, but I wanted to find it as opposed to call it by position. The length of the string starting with R is fixed, however.
@qqilihq’s solution worked great! This is the one I tried first, but @lelloba appears to work as well!
Hi @wisemanleo , it’s definitely good to know how not to depend on the position. However if the position is fixed, the substr() function will do the job much faster than regex, as substr() is just going at the exact position, while regex needs to first do a search through the string each time.
Both will work, but substr() will be the most efficient
Perfect, thanks @bruno29a. The workflow overall is simple enough to allow me to run both, which I’ll do for learning as well as to explore the tipping point at which the data size becomes large enough where the processing speed begins to diverge significantly.
No problem @wisemanleo , and as I said, it’s good to know how to be able to do this via different solutions - that’s the common thing about Knime, there are almost always different ways to reach a solution.
Keep in mind though, if you do have more than 1 R, only the substr() with fixed position will work.
For example:
950.00 NR046693R94660A
The substr() solution will give you the expected value. Regex won’t (you can test it for yourself), unless the Regex also include some positional info.