I am trying to extract a table from a PDF file. Similar to the way the ‘Tabularizer’ package works in R. Is this possible in KNIME?
After looking through the forum and the sample workflows, I’ve only found examples extracting text or metadata from PDFs. I want to get the table directly. Has anyone tried to do this?
Any luck as I’m trying to extract a table from a pdf file. Since I couldn’t upload a sample pdf file, here is a pdf link and if someone can provide the steps to extract the table on page 108
It is possible if the PDF allows it, meaning if the string we get from the PDF represents the table so that we can manipulate the String, to extract the table.
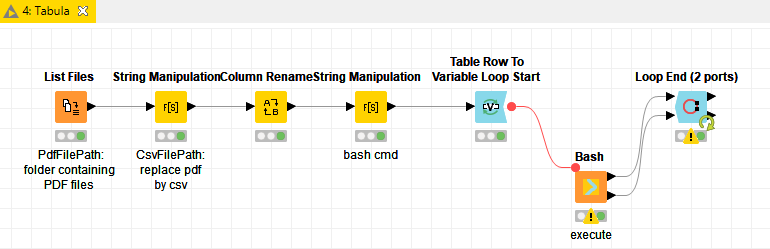
I took @JAGBI’s example and parsed the first three pages as an example. In order to extract the whole table/document, some more string manipulation would have to be done. The magic happens in the Extract Table metanode, where the string is parsed to an actual table. The workflow would have to be adapted to other PDFs/tables, but it worked pretty well on the given PDF.
This is awesome. Could you confirm if the Extract table is a node or a macro? If its macro could please share a link to a guide on how to create macros in KNIME?
@qqilihq That sure does look interesting, and might be a better/easier way to extract the table. I just played with it a little and it was not working all too well with the example provided by @JAGBI. Maybe I missed some configuration. We need some volunteers!
@izaychik63 I admit that it is not as straight forward, the parsed PDF has to be inspected in order to know on what delimiter the string, extracted from the PDF, should be split.
@JAGBI The Extract table is actually simply an encapsulated array of nodes, if you double-click the Extract table metanode you can inspect the nodes that I used.
If the PDF is not too crappy, I used to use a combination of the PDF Parser and the Document Data Extractor to get the data from my bank account statements.
Hi mate,
I reckon, if the table areas are the same, you should be able to extract it.
If you have headers with multiple lines, I’d suggest to select the data area only, as Tabula does not seem to support multi-line headers.
hi @Veys,
this is fantastic. I’m still quite new to KNIME so there is some parts i’m not very clear - do you mind to share the .knwf file with us too? Thank you so much!