I am very sure that this problem has already been faced in a lot of discussions in this forum but surprisingly I haven’t found the right solution to my problem, so far: I want to transform tables directly from some Wikipedia articles into a KNIME Database so that I can export them later as csv for example. I know that the Extract Table Node from Selenium can do this easily but I would prefer a solution using XPath, because no licence is required for this one.
I have also attached an Example Workflow to illustrate my Problem. It might be the case that I’m using the wrong XPath query definition, because with the multiple row/column option I only get the content of the first column of this table but not the rest of it. Do I need something like a loop node or can I just handle it by defining another query?
Thank you in advance for any hint to the solution!
Hello @lpterritory and Welcom to the KNIME community!
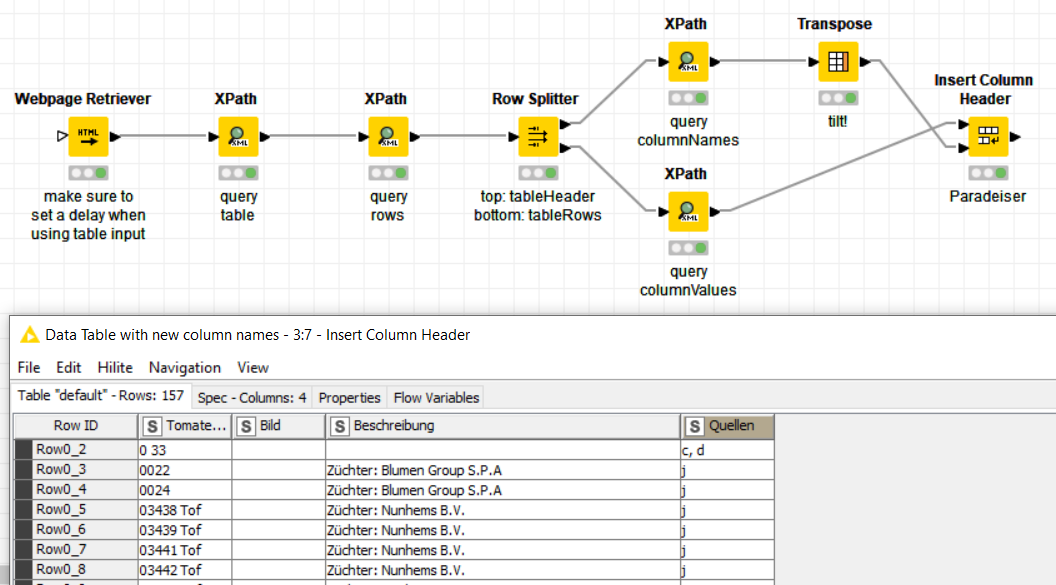
I used the Webpage retriever because it’s a standard node, but that shouldn’t make a difference. For the XPath queries I like to take things slow, querying one hierarchy level at a time:
grab the entire table (single node)
query the table rows (multi-row node)
split the result into header and rows (html quirks )
query the cell values (multi-column strings)
insert header
The Webpage Retriever can query an entire input table (make sure to set a delay, or you’ll DDoS Wikipedia), but the downstream processing can’t. The changes required for that are minor, you should be able to figure that out. Let me know if you need help with that!
Hey Thyme,
Thank you very much for your constructive and solution-oriented input. Thanks to your example workflow I have seen my mistake and understand how to get to my desired output. Nevertheless I still have some questions, you may be able to answer as well:
Is it possible to import images directly from the table or are only the links to the corresponding images displayed?
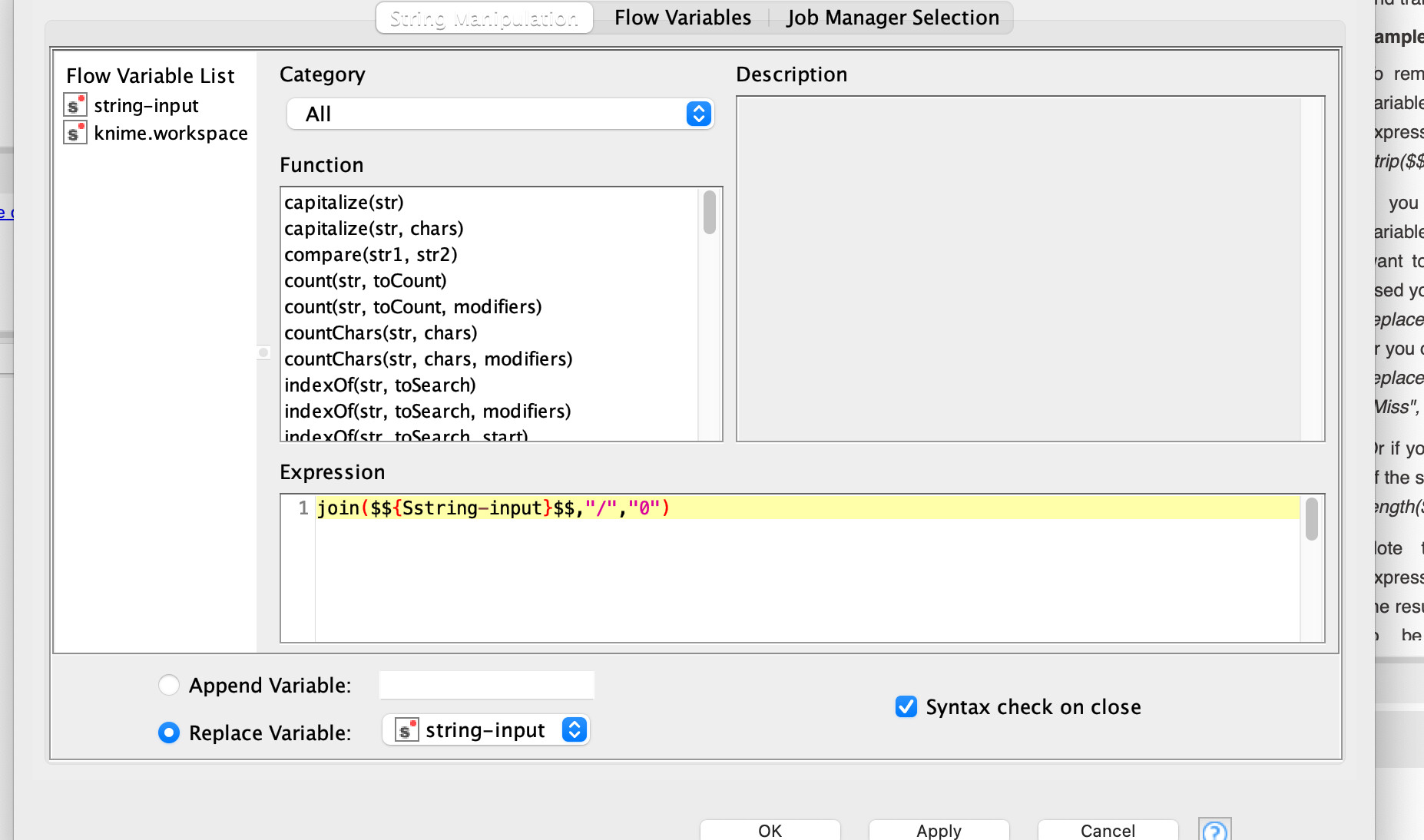
In the meantime, I have tried to work out the workflow a little more precisely. Starting from the main URL, I want to dynamically load the tables of the individual categories (0, A-Z) into the web retriever and then merge them into one large database. For this purpose, I stored the main URL of the list entry in the String Configuration Node and then passed the string to the String Manipulation Node. There I tried to append the appropriate suffixes to the URL using the Join command. Unfortunately, it is not quite clear to me how exactly I can set several attributes at once at this point. Possibly with RegexReplace? I have uploaded an example workflow again.
It appears the Webpage Retriever can only do text-based scraping. Going by the node description of the Palladian extensions HTTP Retriever you have used, it seems it can handle more than just text:
Results of the “HTTP Retriever” node are provided as “HTTP Result” cell type. The HTTP Result type bundles the actual binary content of the result, status code, and all HTTP response headers.
Not sure how to download the pictures. I can have a look tomorrow.
Regarding the url creation, if you want just these 27 pages, I’d just hardcode it:
Table Creator with all page indices (0, A-Z)
String Manipulation to create full url
Table Row to Variable Loop Start (to skip changing how html table headers are handled)
Wow, thank you very much for your help! I first thought of a similar solution, but had the feeling that there might be a more “elegant” way using a dynamic string or something similar. But the simplest solutions are often the best
If downloading the images doesn’t work, that wouldn’t be so bad either. That would be more of a nice “feature to have”.
Hardcoding is the elegant solution whenever the generalised approach is not worth the effort
Anyway, I tried to poke a few settings, but I couldn’t make the Webpage Retriever download pictures. The ones included in the table are only thumbnails anyway. I hardcoded the 4 columns to also query the image name. The link goes to another page with the full quality pic, but we can shortcut that and build the direct image locations ourselves. This is where the worfklow stops.
You can then download those 136 pictures subsequently, might even be the better approach.
Hi Thyme,
sorry for the late reply, but thank you for this fantastic solution and the effort you made! This part of the workflow is working quite well now.
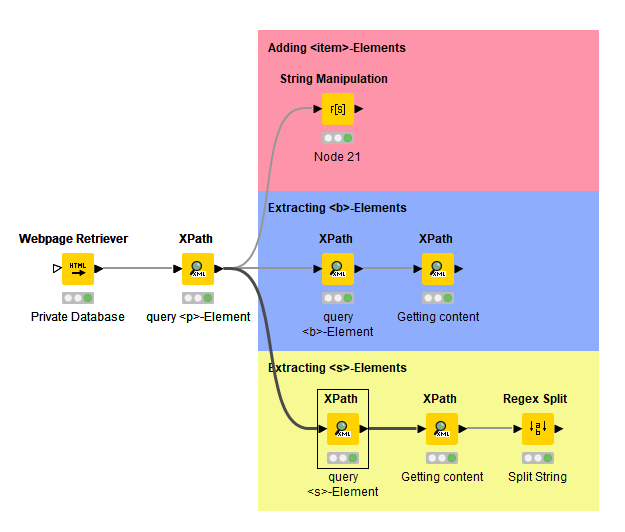
I am also working on another workflow to integrate with this one. Even though it is no longer about extracting a table from Wikipedia, the procedure is almost identical. I would like to collect the information from a private but publicly accessible database. Unfortunately, the page is not organised in a table structure, but rather by a sequence of <b> and <br> elements, which makes the targeted extraction of information somewhat more difficult. Nevertheless, I have already been able to filter out the relevant tomato varieties. I would now also like to add the description texts in a separate column in Knime. The problem is that they are not included in a separate element. My idea was therefore to adapt the XML code so that they are in an ‘artificial’ element. I thought of using a regex query, because the description text is always between two </br> elements.
The following forum post is also interesting in this context: Creating column names with XPATH Node
Unfortunately, I’m not very familiar with the regex syntax and therefore don’t really know how I would have to adapt it to realise my idea…
Another point is that I would like to integrate the numbers in front of the <b>-elements into a separate column. The procedure for this would probably be analogous to the previous one.
If anyone has a tip for this problem, I would be very grateful and would appreciate a reply!
Do you want to harvest the info only once, or do you intend to do that repeatedly?
For a one-shot, I’d just copy and paste it into Excel. The format directly after that is very friendly (the information whether a variety is crossed out is lost though). Frankly, KNIME is overkill for that.
If you want to scrape the webpage repeatedly, that’s a different story though. One-click execution of tasks that used to take hours feels great.
Let me know which one it is. I’ll help you either way, no worries
I had initially also thought of simply transferring the content of the website into Excel via copy and paste and then exporting the database as a csv file. This would probably be the easiest and possibly the most intuitive solution, but also a very static one. In any case, the corresponding website will be updated annually, or even more often per year, which is why a dynamic one-click-knime solution would be charming in any case. I would possibly apply the corresponding principle to other websites as well. I also have to admit that I like to learn new things and would like to try to deepen the handling of Knime in this way
Thanks for your support and many greetings,
lpterritory
I have bad news for you, the Webpage has no consistent structure:
primary header “Tomaten” stands on its own (not in paragraph)
first header “Rote Stabtomaten” has its own paragraph
first data batch has its own paragraph
second header and second data batch share a paragraph
everything tomato afterwards is in one paragraph
following species have one paragraph each
Every algortihm that adapts to this madness will be either over-engineered or static in nature, regardless of the implementation. That means Excel is back on the menu.
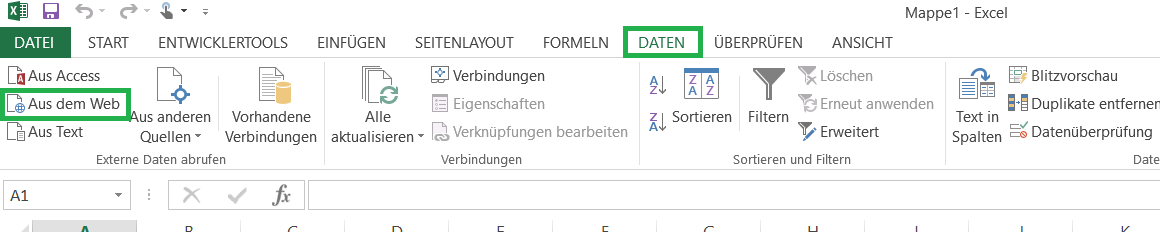
Excel can import webpages: click on “Daten” → “Aus dem Web”, copy the url and import. Don’t configure anything. Doing it this way reduces the possibility for human error. After saving the file, the rest can be done in Excel. I guess you speak german, so I didn’t bother translating the buttons in my Excel GUI.
Unfortunately, the structure is still not consistent. Dividing into name and description by rownumber doesn’t work because some varieties are single-row, others are more than 2 rows. I need to come up with something different. I’ll look into it later.
Hello Thyme,
The approach with the row indices and column indices is really remarkable. I think I need to take a closer look at the concept of pivot tables in general, but I definitely like the current approach!
If the website was at least structured in a consistent way, the current workflow would probably even be right. But as it is, it’s still a tricky challenge.
One more question or idea came to my mind: Once you import the website using Excel, you obviously transfer the content into a cell-based format. Isn’t there perhaps a node that converts the XML format into the same cell format (e.g. the XLS Writer)? That way you would also have a dynamic workflow.
A thousand thanks for your very impressive solutions so far! It all helps me a lot
The XML to JSON to table combo does exactly that, but it doesn’t work (I tried). The reason is that both the XML to JSON and the JSON to Table nodes use the underlying html structure, which is unwieldy. Excel on the other hand parses the content based on the visual structure (WYSIWYG style). This makes it more easy to use, but there’s still some formatting issues we have to deal with.
To pivot the rows into name and description columns I used RegEx. I think I caught all edge-cases, but I didn’t check too thorougly. Also, some descriptions and names are mixed together. I leave this as an exercise to you to disassemble it further. There’s two conditions for an ID+name row:
the first word starts with a digit, optionally followed by non-whitespace characters (e.g. 937c) Wildform should match)
the second word starts with either a digit or a capital letter (e.g. 50 cm or 1000 kirschgroße should not match, but 987 42 Day Tomato should)
I’m sure the Excel import can be automated with VBA, and the script can then be called using the External Tool node or something similar.
Hello and sorry for the late feedback. Unfortunately, I have a lot on my plate at the moment and can only deal with the workflow in bits and pieces.
First of all, I have taken care of the automation of the Excel import and have now successfully written a VBS script for this. I can call and execute this script without any problems via a Bash file. Without Knime integration, everything works perfectly so far. However, I am not quite sure how best to configure the external node. I have managed to run the batch file in the background and create the xlsx file, but I don’t know how best to dynamically load the resulting Excel file into Knime.
Is there another and nicer variant than using the Excel reader?
Regarding the special cases that occur in the database, I have meanwhile decided to contact the web administrator of the database and inform him about the inconsistencies I have found. Ideally, the definition of complicated regexes will then be unnecessary.
I haven’t used the External Tool node yet, but as far as I understand it, you can read a file with it, that it will present at the output.
I’d save the workbook to a static location, set the External Tool to read from that location and manage archiving the raw data with KNIME. For that you probably need to save the workbook as CSV.
I don’t recommend using the FileFormat enumerations for that, as it makes the code harder to understand. It also made it more difficult for me to figure out what the 51 is supposed to do. Instead, write something like
 )
)