Hello @lpterritory and Welcom to the KNIME community!
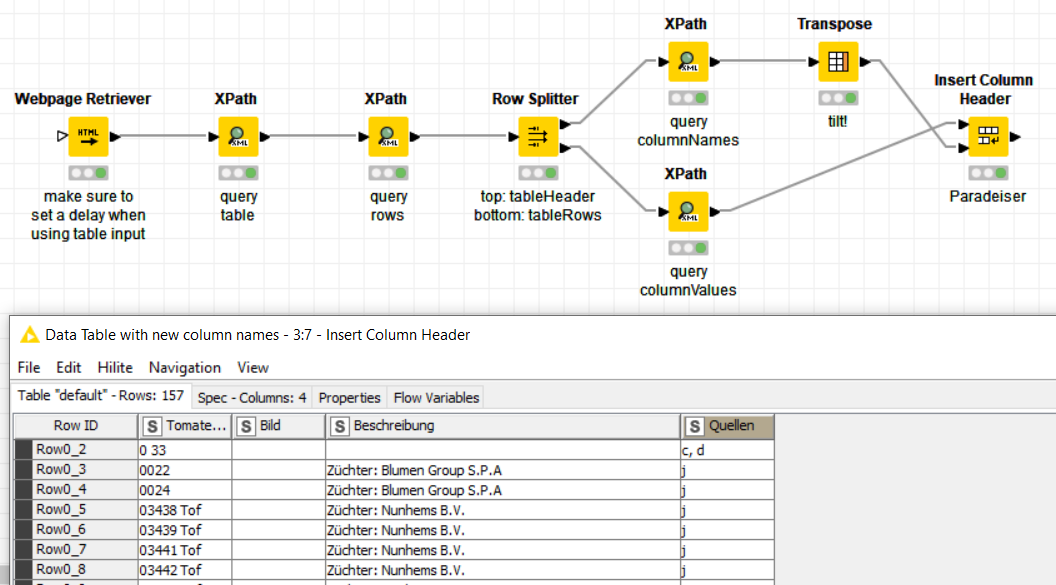
I used the Webpage retriever because it’s a standard node, but that shouldn’t make a difference. For the XPath queries I like to take things slow, querying one hierarchy level at a time:
- grab the entire table (single node)
- query the table rows (multi-row node)
- split the result into header and rows (html quirks
 )
) - query the cell values (multi-column strings)
- insert header
The Webpage Retriever can query an entire input table (make sure to set a delay, or you’ll DDoS Wikipedia), but the downstream processing can’t. The changes required for that are minor, you should be able to figure that out. Let me know if you need help with that!
scrape tables from wiki.knwf (65.5 KB)