Hi Thyme,
sorry for the late reply, but thank you for this fantastic solution and the effort you made! This part of the workflow is working quite well now.
I am also working on another workflow to integrate with this one. Even though it is no longer about extracting a table from Wikipedia, the procedure is almost identical. I would like to collect the information from a private but publicly accessible database. Unfortunately, the page is not organised in a table structure, but rather by a sequence of <b> and <br> elements, which makes the targeted extraction of information somewhat more difficult. Nevertheless, I have already been able to filter out the relevant tomato varieties. I would now also like to add the description texts in a separate column in Knime. The problem is that they are not included in a separate element. My idea was therefore to adapt the XML code so that they are in an ‘artificial’ element. I thought of using a regex query, because the description text is always between two </br> elements.
The following forum post is also interesting in this context: Creating column names with XPATH Node
Unfortunately, I’m not very familiar with the regex syntax and therefore don’t really know how I would have to adapt it to realise my idea…
Another point is that I would like to integrate the numbers in front of the <b>-elements into a separate column. The procedure for this would probably be analogous to the previous one.
If anyone has a tip for this problem, I would be very grateful and would appreciate a reply!
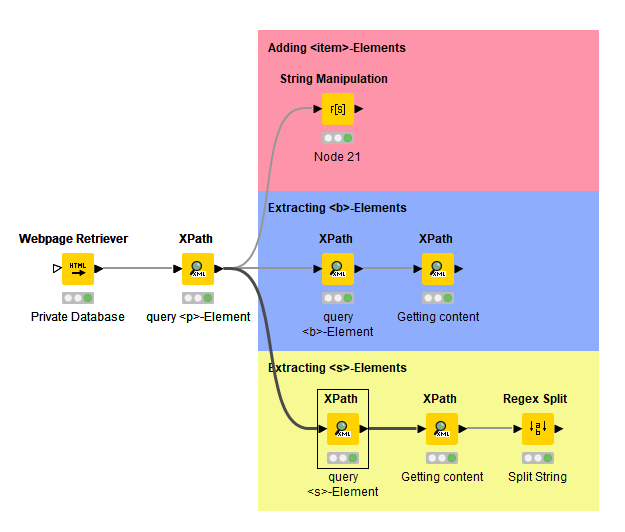
scrape content from websites.knwf (156.2 KB)
Many greetings,
lpterritory