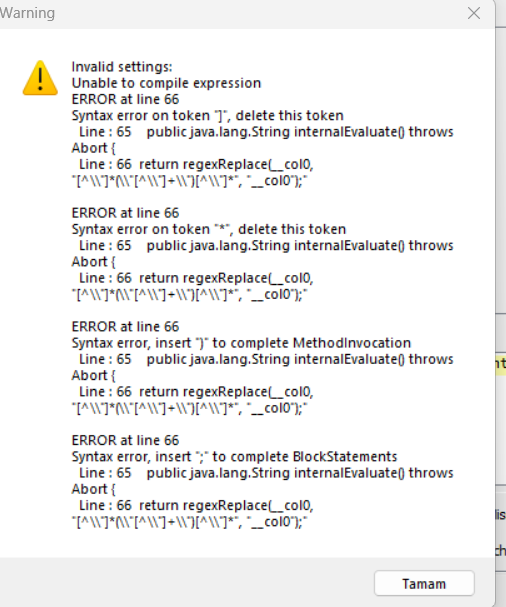
Could you please send an example of what solution is needed to extract the text between two double quotes from the data.
Within double quotes, the text character is ambiguous.
sample texts below
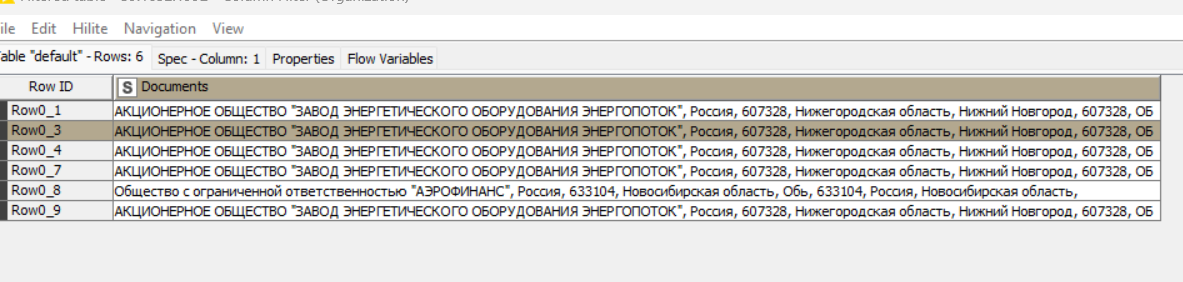
example 1 АКЦИОНЕРНОЕ ОБЩЕСТВО “ЗАВОД ЭНЕРГЕТИЧЕСКОГО ОБОРУДОВАНИЯ ЭНЕРГОПОТОК”, Россия, 607328, Нижегородская область, Нижний Новгород, 607328, ОБ
**** edit
“ЗАВОД ЭНЕРГЕТИЧЕСКОГО ОБОРУДОВАНИЯ ЭНЕРГОПОТОК”
example 2 Общество с ограниченной ответственностью “АЭРОФИНАНС”, Россия, 633104, Новосибирская область, Обь, 633104, Россия, Новосибирская область,
**** edit
“АЭРОФИНАНС”
Hi,
Will there be only one section in double quotes? And is it double quotes like this: “text” or like in your example “text”? It might be that the latter comes from our forum software reformatting your double quotes.
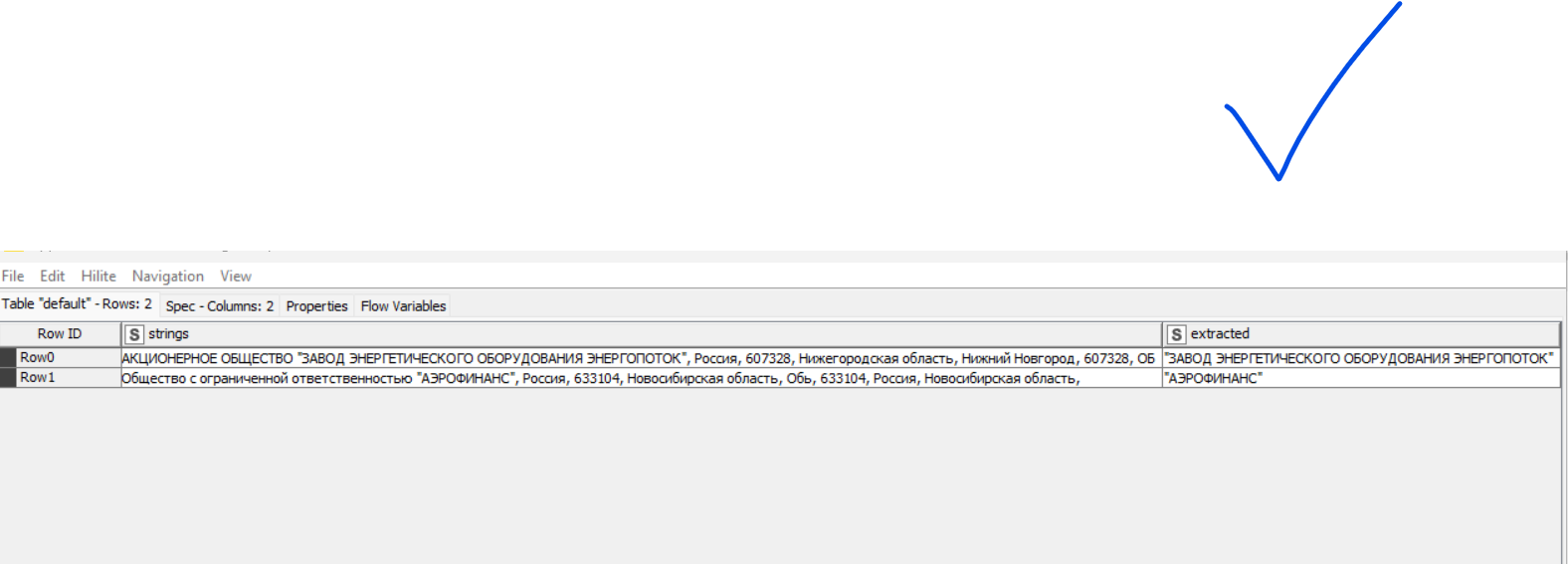
If it is the former, you can use the String Manipulation node with the following expression:
This command looks for a pattern that is basically the following: “first any number of non-double-quote-characters, followed by double quotes, followed by one or more non-double-quote-characters, followed by double quote, followed by any number of non-double-quote-characters”. We capture the relevant part by surrounding it with parentheses () and this captured part is available in the replacement string via the placeholder $1. So we replace the whole string by the part that is in double quotes.
Kind regards,
Alexander
Hi,
Apologies, there should have been only single backslashes in the code. I also think when copy-pasting you may have copied wrongly formatted characters (might be our forum software that renders them that way). Please find attached an example workflow. That should clear things up.
Kind regards,
Alexander Quotes.knwf (7.1 KB)