Hi,
I am trying to extract words (mostly non-English) from a text string that contains unstructured combinations of other characters (letters, [-.:/]etc., and numbers). Each text string contains a different number of words. The shortest word has 2 letters. Words may contain the special letters:[ÁáÀàÂâÄäÉéÈèÊêËëÍíÌìÎîÏïIJijÓóÒòÔôÖöÚúÙùÛûÜüÝýŸÿ]
I want to extract words that only contain at least 2 letters (including special letters) and are surrounded by spaces. No periods, dash, slash etc. The icing on the cake: A valid word needs to have at least one vowel and at least one consonant.
I am trying to find a solution using the String Replacer, Regex Split, and String Manipulation nodes because all of these nodes should work. I can get somewhat close to a solution using 9 text processing nodes, but not with regular expressions. In regex101.com I can identify the words that I am looking for with the regex:
(?<=\s)([[:alpha:]])+(?=\s) but substition of the inverse is not working.
Failed attempts
- Regex Split with (?<=\s)([[:alpha:]])+(?=\s): Error message: did not match the pattern or contained more groups than expected. I presume it is the latter. Is there a way to add additional columns to the existing table even when the number of columns is different for each row? Is it somehow possible to attach a list of words to each row of the table? Can the “regex split” words be joined and attached?
I am also unable to negate/inverse the regular expression. Any ideas? - String Replacer: I can replace in regex101.com almost all text with that I don’t want, but not in Knime.
([^[:alpha:]]{2,}[ÁáÀàÂâÄäÉéÈèÊêËëÍíÌìÎîÏïIJijÓóÒòÔôÖöÚúÙùÛûÜüÝýŸÿ]{0,})
I am getting single letters and extra spaces. I need a 2nd regex to clean up the remainder
I am unable to negate the expression (?<=\s)([[:alpha:]])+(?=\s). I am not able to explicitly define the text that I do not want, because there is absolutely no pattern. - String Manipulation: I am having the same problems with the negations.
Example text → desired output
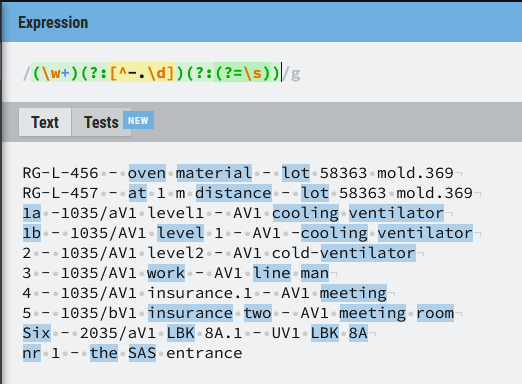
RG-L-456 - oven material - lot 58363 mold.369 → oven material lot
RG-L-457 - at 1 m distance - lot 58363 mold.369 → at distance lot
1a -1035/aV1 level1 - AV1 cooling ventilator → cooling ventilator
1b - 1035/AV1 level 1 - AV1 -cooling ventilator → level ventilator
2 - 1035/AV1 level2 - AV1 cold-ventilator → (nothing should be found)
3 - 1035/AV1 work - AV1 line man → work line man
4 - 1035/AV1 insurance.1 - AV1 meeting → meeting
5 - 1035/bV1 insurance two - AV1 meeting room → insurance two meeting room
Six - 2035/aV1 LBK 8A.1 - UV1 LBK 8A → six
nr 1 - the SAS entrance → the SAS entrance
Any help would greatly be appreciated!