Hello dear friends
I have a very big problem!
I have 6 large tables in SQL Server, each of which has over 50 million rows and between 10 and 20 columns!
I extract data through database nodes (such as db joiner and db concatenate nodes, etc.), but when I want to extract that data from SQL Server through the db reader node and perform other analyses on it, it takes about 30 minutes, which is too much time for my needs and the employer does not accept this!
Please help me solve this problem
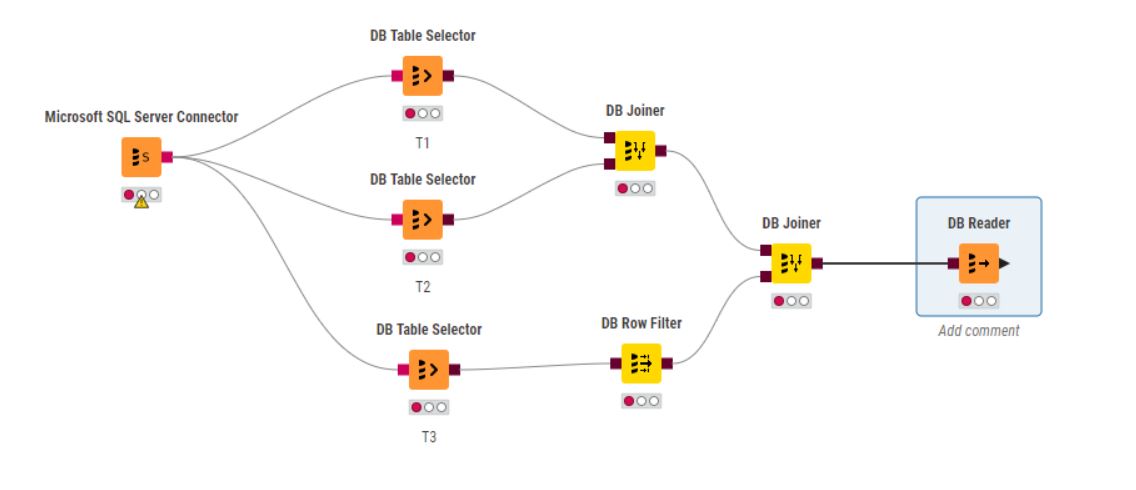
Hi @alex1368 , there are a number of factors at play here.
For example what indexes are on your database, and what is the speed of your network, how much memory have you got available and allocated to KNIME and what other things are happening on your PC at the same time. Is this a high powered server, or a lowly laptop?
Assuming the query runs perfectly with absolutely no query overhead (i.e. SQL Server can execute it immediately with no delay), then your network speed and available memory and disk speed are going to play a big part here.
How much data per row is there in your 10-20 columns. Is it textual, or numeric? Let’s say you had 500 bytes per row, then 50 million rows is 25 GB.
Can you say with certainty that you can easily download 25GB (or whatever) on your network in 30 minutes?
What is the maximum time that will be “acceptable” to your employer. You should ask, as then you (a) know what to aim for and (b) can try to determine if it is feasible in an objective manner.
So, supposing you know the task must take no longer than 20 minutes… Can your network support 25GB (or whatever your data volume is) in 20 minutes? If you know that in principle it can support this sustained transfer rate, you then need to establish that your database query is optimised, and that the database itself can deliver the data in the timeframe necessary.
KNIME is generally not going to optimise the SQL for you as it knows nothing about your database. It will assume that you have all the necessary indexes on the database, and that you have specified all the required joins.
What you can do, though, is find what query KNIME is generating by attaching a DB Query Extractor to your final DB Joiner, and viewing the query it produces.
If possible, you could try running that query directly against SQL Server in a different client application to see how long the delay is before data starts to be returned, and if necessary see if there are any optimisations needed on the database such as different indexes.
Are your DB Table Selectors merely set to output individual tables, or are they each custom queries? Have you got all the correct join conditions in the DB Joiner nodes (e.g. you aren’t missing some join columns which is causing far more data to be returned than they should)
2 Likes
I have about 128 GB of RAM, of which I have allocated about 80 GB for knime
I am using a g10 server
The table I have has date numbers and text, but I have stored everything as strings and text
My total data is 500 million rows, and at the time of extraction, maybe 5000 or 10000 rows are needed for extraction (depending on my search) and there is no need for all 500,000,000 rows to be transferred to the output. Only the search result should be displayed.
The maximum time considered by the employer is under 90 seconds.
Another question!!! My search is based on phone numbers, and if I enter the phone numbers as strings into the database, will it affect the speed of extraction from SQL Server? I mean at the time of receiving the output from the DB Reader node.
Ah ok, so now you are talking 5000 or 10000 rows in under 90 seconds which is much more likely to be achievable and it doesn’t sound like your hardware is an issue, and KNIME should have no problem in achieving that so this then really means you need to look at the performance of the query itself.
500 million rows though is a large amount of data so you’d need to know that your tables have the right indexes. A full table scan of 500 million rows in a query could take “forever” otherwise
The question I asked about the DB Table Selectors - are these set to read whole tables or custom queries?
Also, how many rows would you think are in each of the tables/queries in each of the DB Table Selectors? (i.e. they are presumably not all 500 million rows?)
Did you look at the query being executed (using the DB Query Extractor)?
Would you be able to share that query here?
Have you checked that the database has all the necessary indexes to support the query?
Having phone numbers as strings shouldn’t have a dramatic effect on speed of extraction, I would expect them to be stored as strings, as phone number format can contain non-numerics such as brackets, spaces, hyphens and + symbol. If you are filtering on phone number (in the DB Row Filter?) the phone number column on the database will need to be indexed.
I should add that I personally prefer to write the SQL rather than using the in-database nodes so that I have more control over it, but whether that’s an option to you depends on your familiarity with SQL. That’s not to say though that this shouldn’t be doable if the database is sufficiently optimised, although I haven’t used SQL Server with a 500 million row table.
3 Likes
When I read “everything is STRING”, this rings an alarm bell. Are there any relevant indexes defined to speed up the process?
Are the unique identifiers for the JOINs all in STRING - which can cause such a delay, especially if used without an index?
1 Like
Hi,
I’m wondering if your employer really need all the data with 500 Mio rows and many columns.
Can you give some insights what’s happening with data? E.g. anyways some calculations like groupby or filtering are done you can apply these methods at the database.
Friends, my data was stored in the tables in string format, and I solved the problem to some extent by changing the format of the key columns to bigint, and then I indexed the important columns until the problem was solved.
2 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.