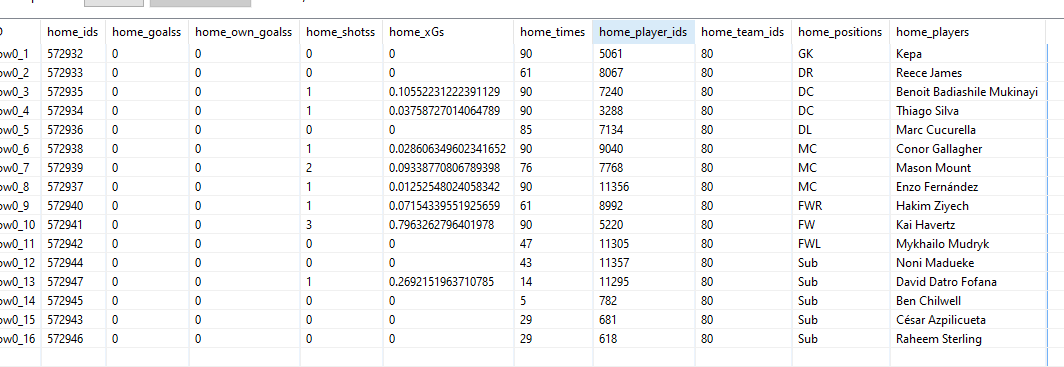
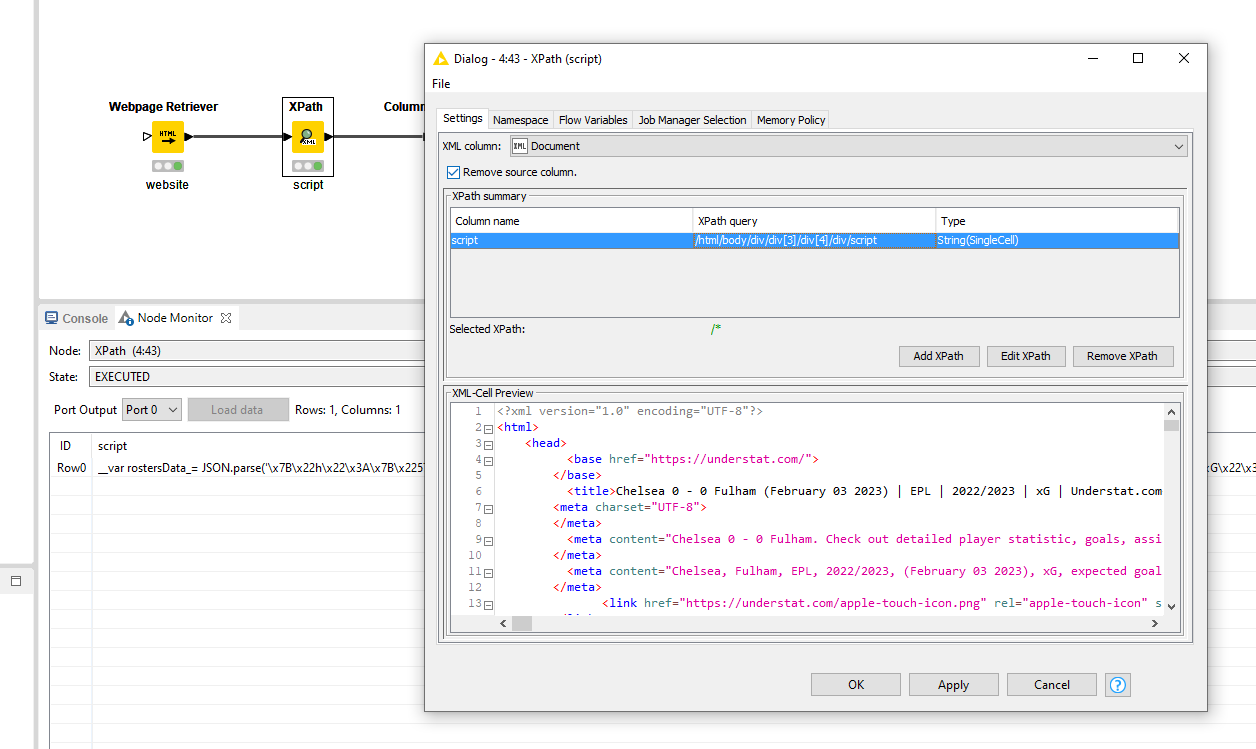
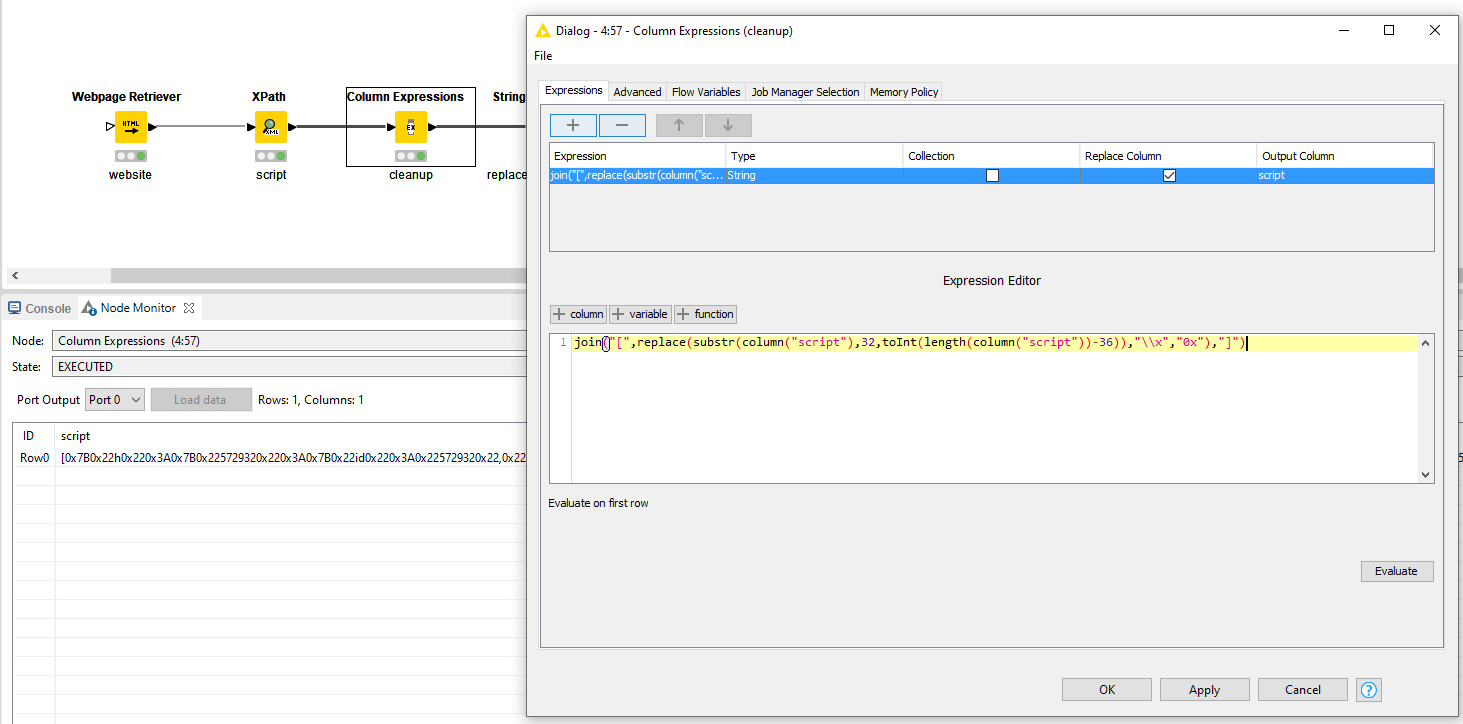
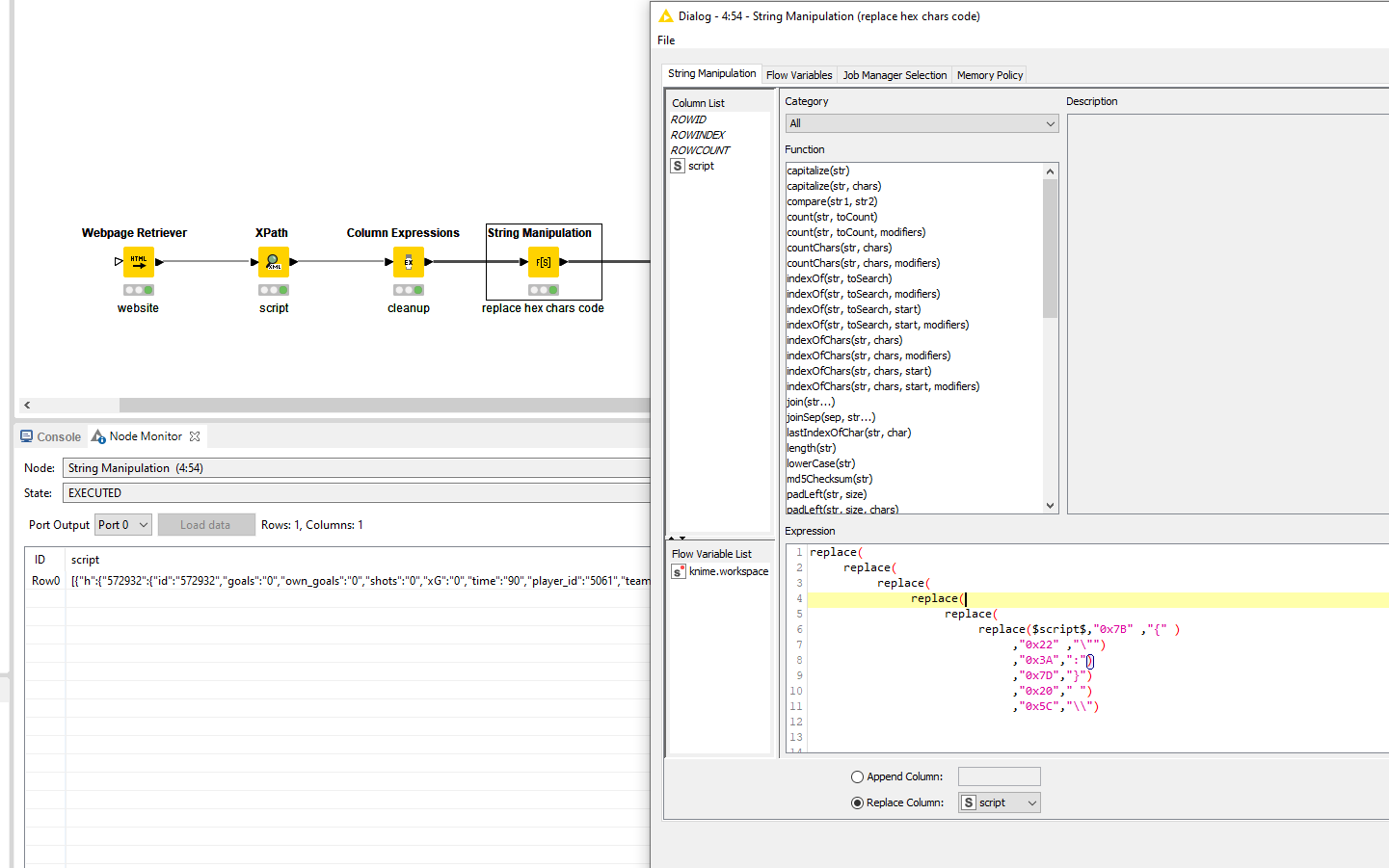
Allright @Glenn_Kuly! Below workflow should get you moving forward.
I must admin that the mentioned website is quite strange in structure and how this data is processed. The workflow might only work for this specific tabel.
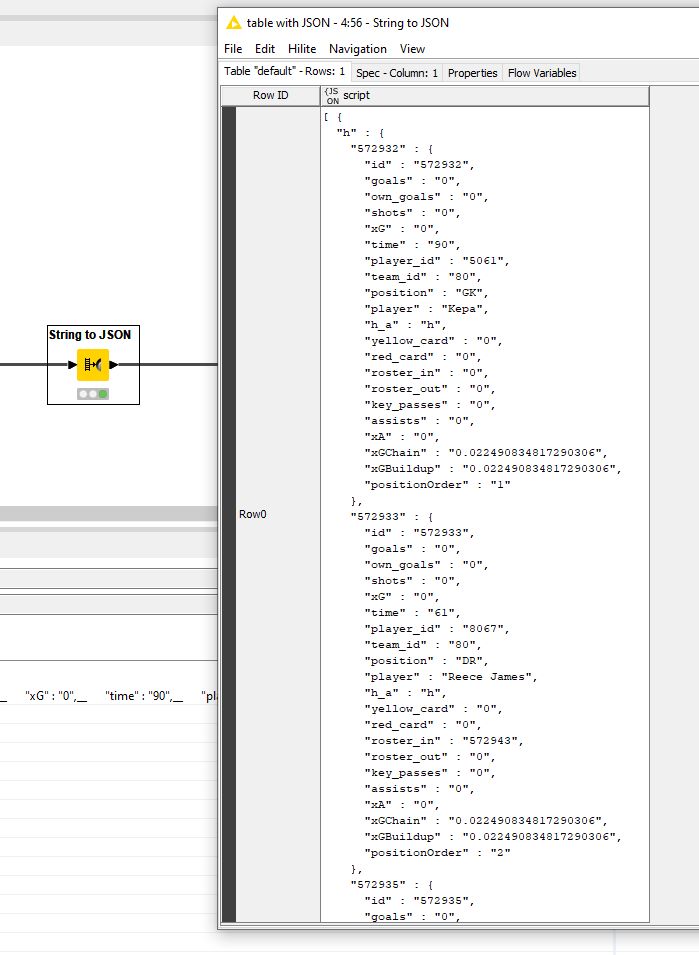
After the webpage retriever, I opt for a Xpath node to extract the script section which contains the data via the query /html/body/div/div[3]/div[4]/div/script. It’s usually a bit more solid than Regex extraction. It will output that JSON.parse string as well
In order to use it though, I found out the hard way that there is a lot of cleansing to be done before it can actually be used. I put this cleanup in a Column Expression using function
join("[",replace(substr(column("script"),32,toInt(length(column("script"))-36)),"\\x","0x"),"]")
One of the actions it does is to capture it in an array so that you can perform collection queries later on.
Next is the replacement of the hex character codes. There is probably a more efficient way to do this, probably in Python, but given the time I went for the manual route with a nested replace() function.
String to JSON node will now give you a properly formatted JSON back which you can subsequently query.
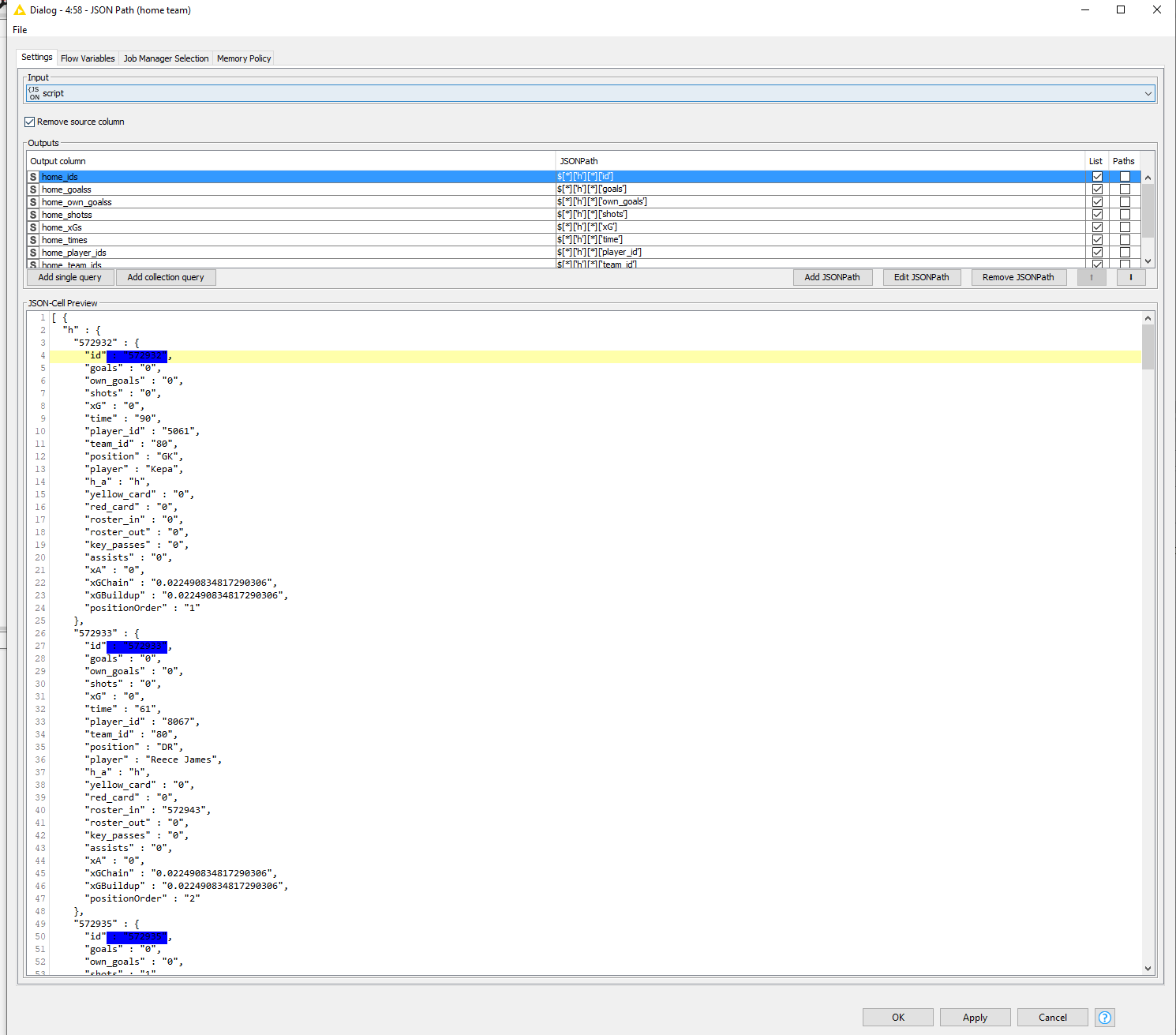
This is done with a JSON Path node. Here you can extract all data fields with their corresponding values by using collection queries, outputted as Lists. For the ids for example, if you use $[*]['h'][*]['id'] it will extract all ids for the home team. You will notice in the JSON that there is an h group and a group. If you want to extract everything for the away team, you change the query to $[*]['a'][*]['id'] or convert it to a wildcard to retrieve both at the same time. This applies to all queries off course.
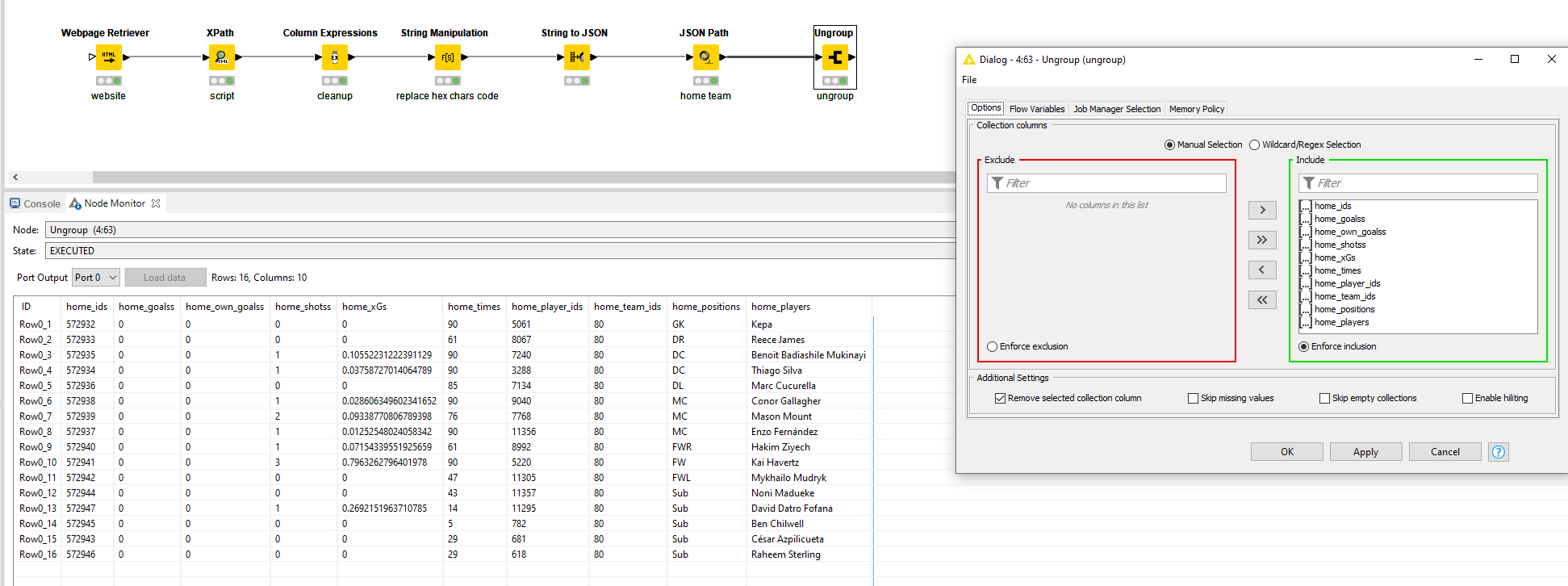
Next ungroup all created lists and you’ll have the stats in a table format.
See WF:
extract JSON data from football website.knwf (62.7 KB)
Hope this helps!