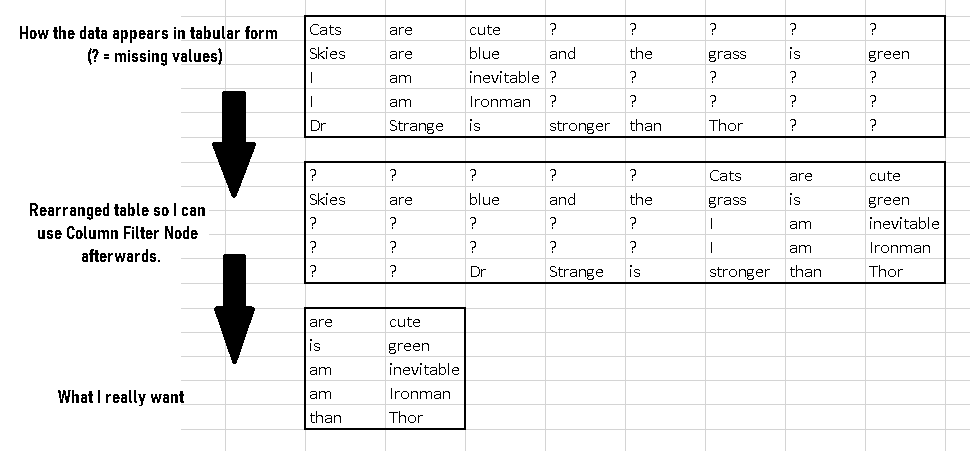
I want to extract the last few words from sentences of varying length.
I have looked at the forum and I found this closed thread (see below), but it only dealt with the last word instead of the last few words. In my case I am looking to extract the last 2 or 3 words. I don’t think the Column Aggregator (as mentioned in that thread) has such configuration.
I am thinking I can use the column filter node, but that would require the table to be rearranged (Please refer to the attached image)
Thanks @gonhaddock , I have read the forum where the workflow originates from. But I don’t know how to connect that issue with mine, and I also don’t understand the issue completely hence I can’t connect how it would be useful to my case. Maybe if you can clarify it in simple ways and help point the connection, it’ll be helpful.
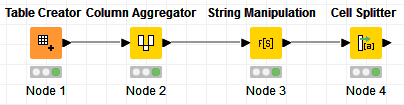
The approach:
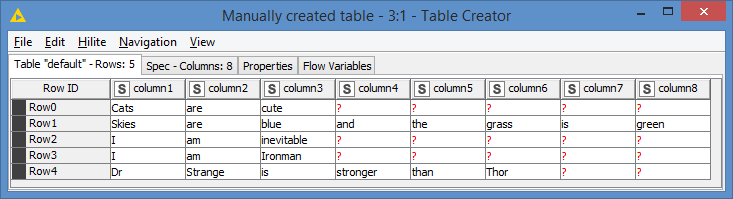
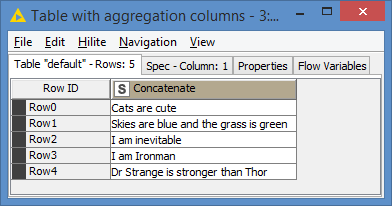
1- Aggregate all columns so that each row becomes a string (Concatenate with a space while ignoring the missing values):
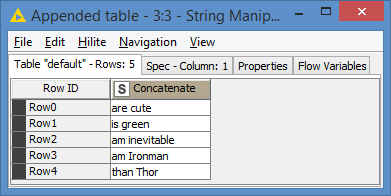
2- Use Regex to extract the last 2 words:
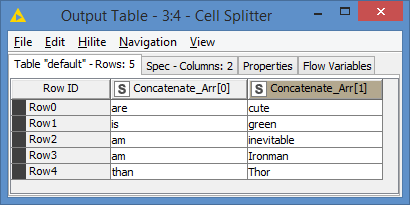
3- Split the 2 words into 2 columns using the Cell Splitter
@bruno29a Thank you again. Your solution works for the dummy data I’ve given. Since I am working with names of servers, the regex formula that you provided in the workflow which is
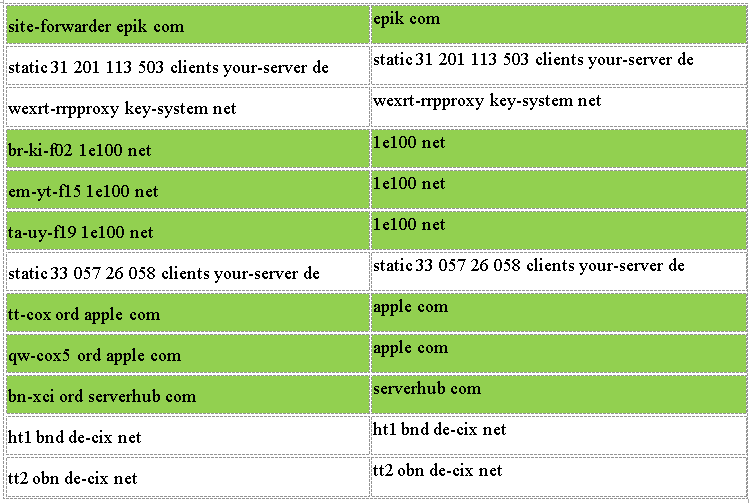
only works for some rows. The image I attach below shows the rows labeled with green colors which gave correct results as I wanted. The non-colored rows gave the incorrect output.
(Note: The server names examples are editted for privacy reasons. I replaced the real alphabets and real numbers with random alphabets and numbers, but the structure and positions are similar to the real raw data.)
Can you help me understand the regex formula you provided, so I can manually edit it to fit my data?
Updated: I think I have found a way to the last question. I just need to use the URL Domain Extractor Node, and add http:// or https:// at the beginning of the server names for the Node to work.
Thank you. I have marked your workflow as Solution since it works on the dummy data. @bruno29a