Hello! I am a newbie here doing research on twitter data.
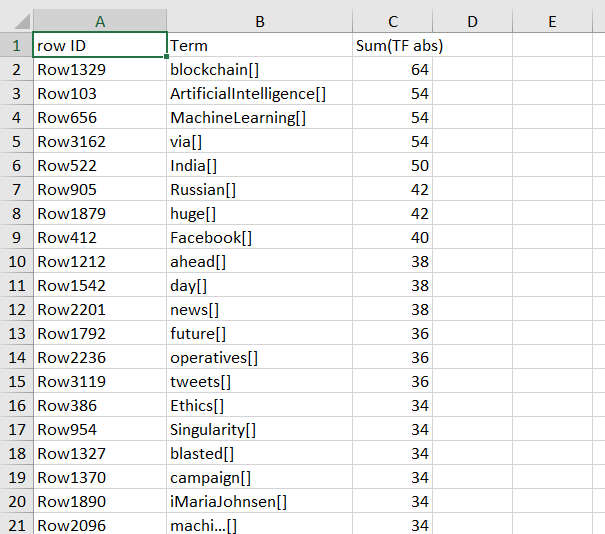
I am using twitter API and using Twitter Search node for several words, but the number of tweets which I am getting in the form of result are limited (in between 65-75). In below picture, I have added word “Technology” in Twitter Search and I get the result (in the form of “Tag cloud” and “Excel Writer XLS”). In sheet, you can see that the SUM (TF abs) is maximum 64. I want this twitter search or my result in thousands of tweets but unable to do that.
Any help would be really appreciated.
Regards,
Rashid
I’m not too sure whether I got you right, but if you want the result in thousands you can simply divide the column by 1000 with a Math Formula node. Or do you just expect higher values for Sum(TF abs)? To get higher values you have to increase the number of rows queried from the Twitter API. Please keep in mind that Twitter limits their API, such that you can only perform a specific amount of queries/query a specific amount of tweets per time frame.
If you meant something different, please elaborate little more about what you want to achieve or what the problem is.
1 Like
Hi Marten,
Thank you for your reply.
Actually I need that numbers (in SUM(TF abs)) bigger than it shown in above screen shot. You can see the higher number is 64 for blockchain (meaning Twitter API searched only 64 tweets regarding Technology (search term is “Technology”) for word “Blockchain” (If I am not wrong). I need that SUM(TF abs) values in more tweets, like number should be in thousands (e.g bloackchain 1521, AI 1200 etc etc).
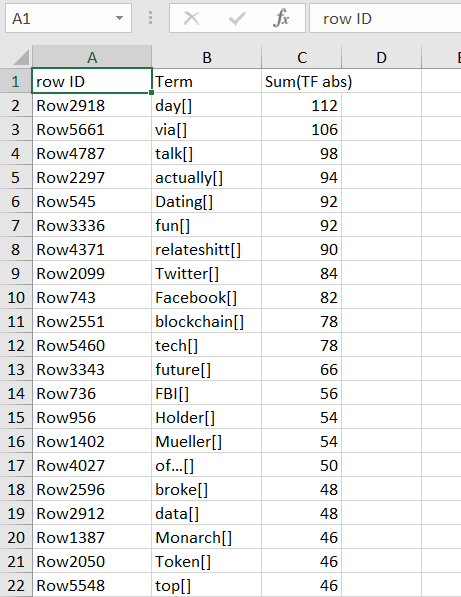
I have tried, as you suggested, to increase the number of rows to 10.000 from 2500, but in attached screen shot, you can see, it still shows the highest number around 100.
Adding in my question, I am working to extract “technological trends” from twitter like Blockchain, A.I, Virtual Reality, 5G etc etc, but still in main question (above attached of nodes) I have used Text preprocessing like stemming and stop words and used TF, but still got common words like days, via, talk etc etc which I don’t need.
I would really appreciate if you can guide me in both problems mentioned above.
Regards,
Rashid
Hi Rashid,
Unfortunately, the standard (free) search API only accesses a sample of recent Tweets published in the past 7 days (see https://developer.twitter.com/en/docs/tweets/search/overview for further details). So there is not just a limit in the number of requests and tweets, but also in the general availability of data. Thinking about the importance of completeness of your data or the openness on how it was sampled, you may want to consider switching to the premium API. If completeness and sampling method does not matter too much, you can simply request the API on a regularly basis during a longer timeframe and save the results in a file or database. This way you should be able to gather a higher number of Tweets related to your search term.
Regarding the filtering of specific words from your documents: If the built-in list is not strict/exhaustive enough for your needs, you could either provide a custom list to the Stop Word Filter or a custom dictionary to the Dictionary Filter node to filter out those words.
I hope this helps.
Cheers,
Marten
1 Like
Hi Martin,
Things are pretty much clear now. Thank you for your help.
Best Regards,
Rashid