My goal is to tag hundrets of documents with tags from a predefined tag list, so I can later assign the tags in a Literature database.
Everything up until the Tagging of the document works fine, I have a list of Tags with multiple keywords each, which then are assigned if the keyword appears in the text.
I then plan to count the number of times keywords for a specific Tag occur, and then assign the tags based on the count of occurences.
However, I cannot find a suitable method for counting the amount of keywords in a tagged document. From my searching Tag filter → Bag of words creator → Group by seems to be the way, but I cannot find any references working with an own set of tags.
Any chance you can upload the workflow itself with some sample input files (assuming they are not proprietary)? Then maybe community members would be able to provide better assistance.
first of all, thanks a lot for your replies! And sorry for my late reply, i was struggeling around with the whitescreen/workspace issue from the latest patch.
Attached is the workflow + 1 example paper + an excel with tags (row 1) and keywords (below the according tag), to get it running i reduced it down to 3 tags + keywords. They do not necessarily make sense, but are appearing frequently in the paper.
Hello @M_FL
I’m taking a look into it.
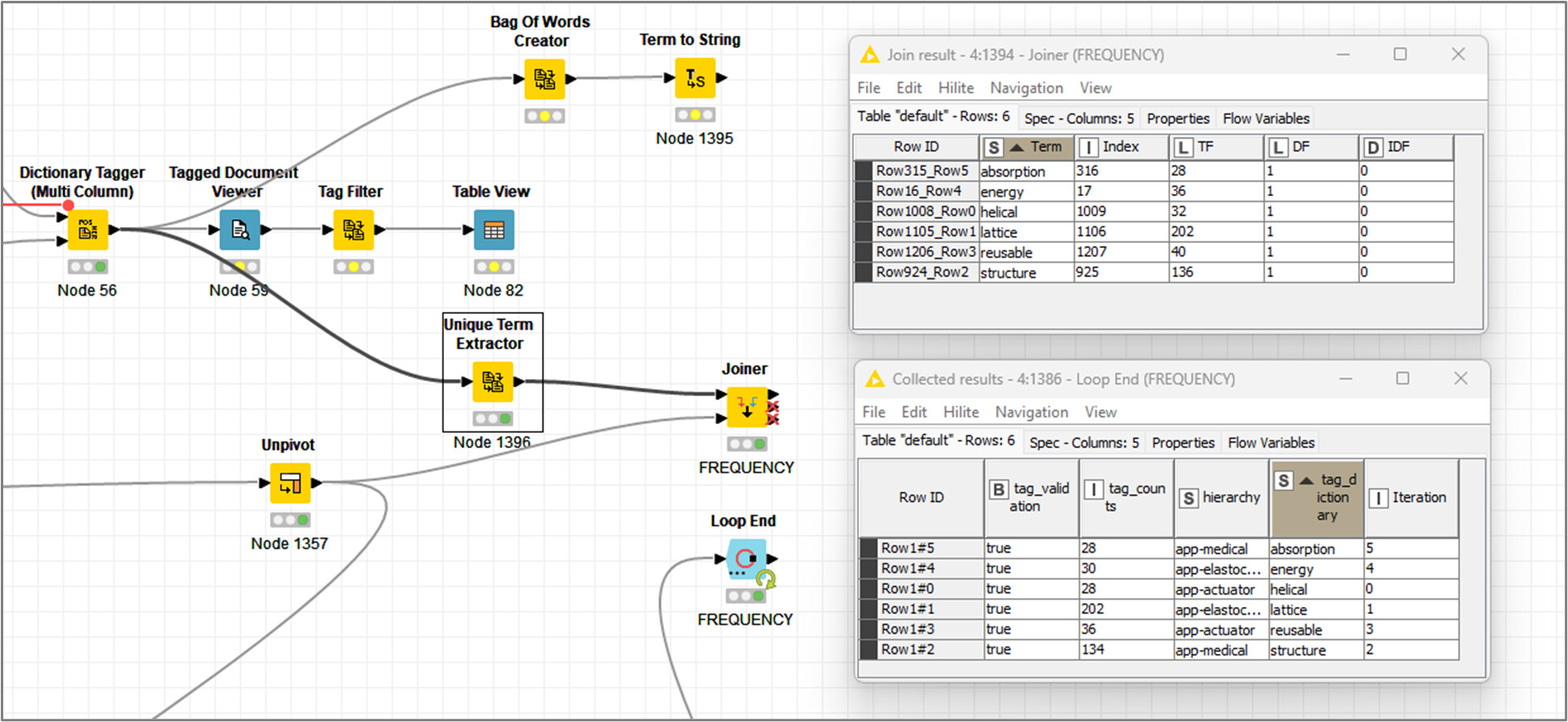
Be aware that some functions in the example workflow are not necessary for your use case. As the workflow extracts #heading and #trailing words, not needed in your challenge. As the target is just the tagged word…
I will test different approaches out from regex coding.
Hello @M_FL
I’ve tested to count tagging from two approaches, getting back slight differences in the results. The source text is a complex pdf document. Then for simplicity, I would rely on ‘Unique Term Extractor’ node.