I have recorded spectral data (wavelenght, intensity) as .txt files (see below). In the name of the text files is a time stamp (e. g. USB4J009161__0__14-39-30-858.txt, USB4J009161__1__14-39-30-969.txt) . I want to display the respective spectral data in the txt-files (several thousands) as a function of time. Can anybody help me here?
Many thanks and best regards
Jürgen
Data from USB4J009161__0__14-39-30-858.txt Node
Date: Wed Mar 18 14:39:30 CET 2020
User:
Spectrometer: USB4J00916
Trigger mode: 0
Integration Time (sec): 1,000000E-1
Scans to average: 1
Electric dark correction enabled: true
Nonlinearity correction enabled: false
Boxcar width: 0
XAxis mode: Wavelengths
Number of Pixels in Spectrum: 3648
Would a looping mechanism help here, to read your files sequentially and append them to a single table? You could then use that table to generate a line plot. Maybe something like this?
It sounds like you have three elements to consider
the file name (you can extract that by using a list file node (and manipulate it later)
the ‘header’ if indeed you file contains the information you mentioned above. The question is: can you separate the header lines from the rest of the data by splitting the file in half. You would initially load the file with File Reader as one single line, drop the data and split the header lines by “:” to get the data into columns
the data itself. You would have to determine where the data starts and read the txt file starting with the respective line (leaving out the header)
Then you would have to combine the three elements back together. Do this with a loop and you can easily process a lot of files.
Sounds complicated but is actually quite doable thanks to KNIME. Maybe you upload some examples and tell us how your output would look like.
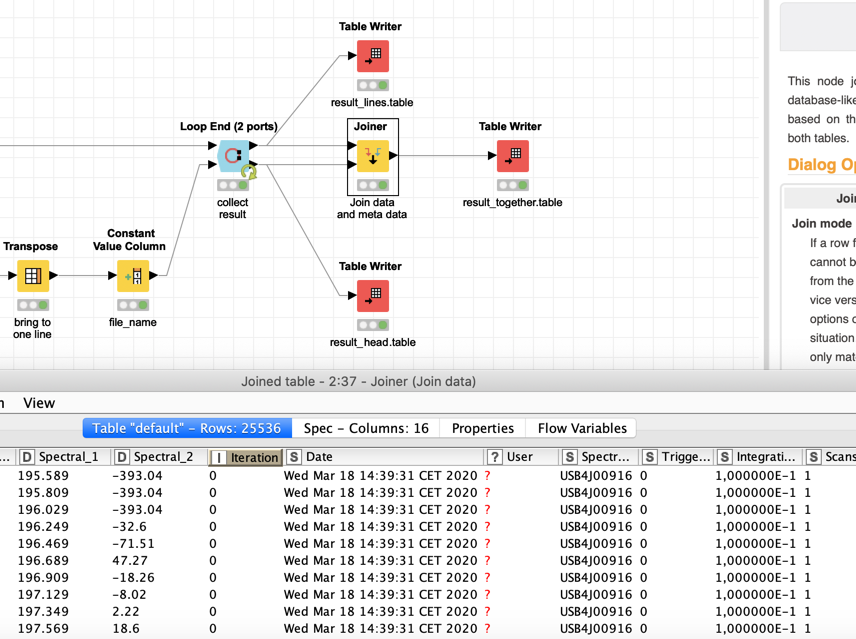
the hints are correct. You should iterate the files like @ScottF mentioned and define where to start the reading process like @mlauber71 explained. As your files start with meta data before listing the values, you should split this part and assign afterwards the important information (date). Please find the workflow attached, which should help… Z_022_txt-files.knwf (30.5 KB)
Dear malauber71 and elsamuel,
I have some difficulties to implement your suggestions, I think mostly due to my inexpertnes up until now in knime. @mlauber71: I get error reports: “ERROR Loop End (2 ports) 0:32 Execute failed: Input table’s structure differs from reference (first iteration) table: Column 1 [User (String)] vs. [User (MissingCell)]” @elsamuel:I think for your approach Palladian nodes are needed, but how to install? I already searched in trusted extensions with no results.
Thanks
As for your your Loop End problem, the error means that one (or both) of your tables is changing throughout the loop, perhaps the name/number of columns is changing during each iteration. It is possible to configure the Loop End node to allow changing table specifications, but you’ll need to investigate what’s going on.