KNIME Community Forum
Extrakt two variables from .txt files in a folder and combine with a third variable (time) given in the file name
KNIME Analytics Platform
mlauber71
March 24, 2020, 3:56pm
8
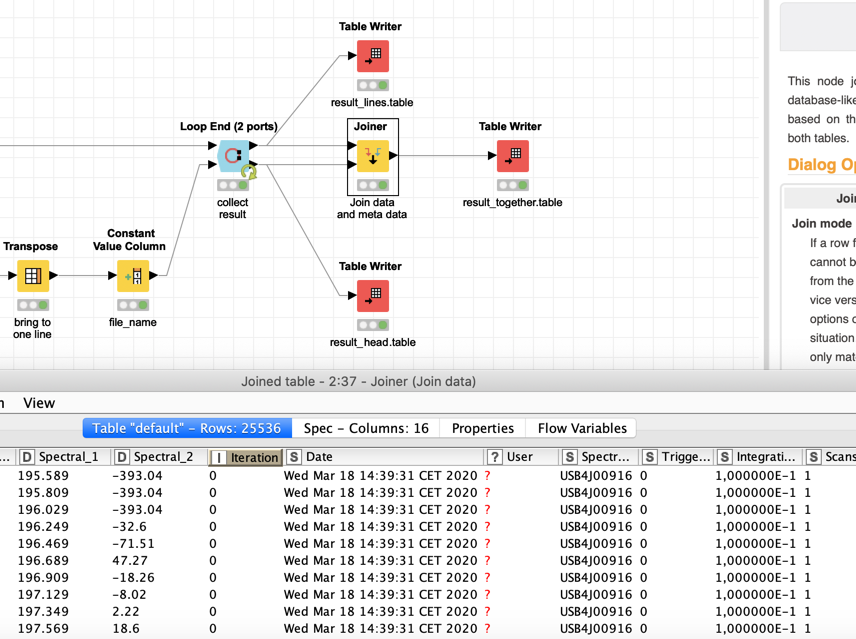
I built a workflow that demonstrates how to import the data and does bring the results together.
image
856×639 161 KB
image
1894×1188 354 KB
Parsing EDIFACT files
Rearrange csv columns and rows
show post in topic