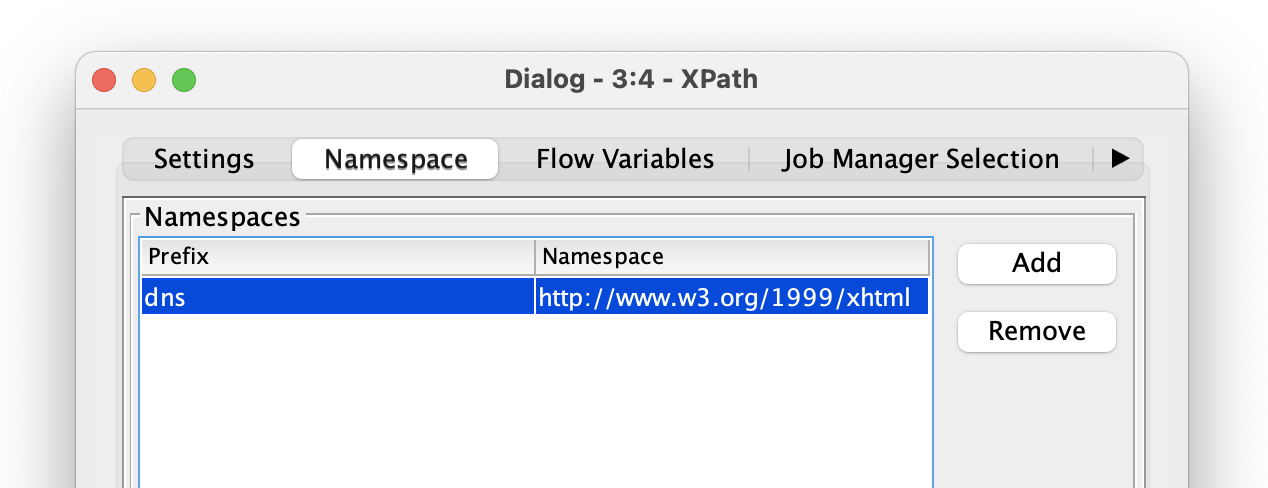
Hi @yxlyxl8,
I think the problem is that the document declares a default namespace at the top: xmlns="http://www.w3.org/1999/xhtml". In the XPath node you see that in the second tab:
and you can get the times in a similar fashion. Instead of explicitly descending into every element along the path (/div/div/div/div/ul/li/span[1]/span/) it is usually more robust to use the // operator, which searches in all descendants, and couple it with a stable filter by element attributes, like I did above with the @class attribute.
Kind regards,
Alexander