I am trying to make a workflow that reads lots of big xlsx files from a folder. The reading times are not ok.
One file can have around 20-25 sheets with 3000 each file. By now I have 50 files and growing each day.
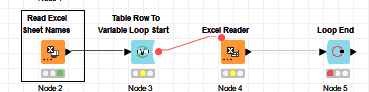
I tried with this workflow, without success:
Problems:
Mediocre pc.
I have to work via vpn which makes the proccessing slower than normal.
There would not be any problem with this. I could convert to .csv. The files only have text and numbers.
But I think I need the loop. I am not fully sure that every file contains the same number of sheets.
do you have the option working with remote a connection to computer which is located within the company network environment and running Knime on this compouter? I guess this is the fasted option.
I’m working with this setup without any performance issues.
Good idea!
As far as I know, I am the only person using Knime that I can reach within the company, so I would have to ask for it.
As a matter of fact, I would like to try and teach this software, but projects like this usually die fast.
Maybe I can implement this. Thank you!
Yes. You might also try to ZIP your file, download it and then try to import it. Depening on the version of Excel there might already be an internal compression.
The question would be where the bottleneck is. Is it in the import or is it the VPN connection. You might have to try.
Downloading improves the speed but it is not enough.
I have to make other imports daily with files that can be bigger than each unique sheet within the file. It is the combination of several sheets inside each file which makes the loading painfully slow, I think. The reader has to read 20 sheets per file.
Could I improve the speed extracting each sheet from every file, converting it to .csv and then reading every file (which would have only 1 sheet inside)?
I.e: Which one is the fastest strategy? Reading every sheet inside the files or reading one sheet per file? Knowing that, if I implement the last option I could have around 20 files per 1 original file.
With the number of files I manage right now, almost 1000 files with 3000 rows each.
I have been through this problem before too and one of the bottlenecks I experienced was not only when reading the excel sheets one by one but specially with the -Read Excel Sheet Names- node.
As far as I understood, the java library used by the -Read Excel Sheet Names- node reads the whole Excel document just to figure out the names of the Excel Sheets, which eventually turns out to be quite inefficient.
Have you measured the time every node takes to execute in your example ? Is it also the case for you (the Read Excel Sheet Names- node takes as long as the execution of the loop) ?
Yep, the Read Excel Sheet Names node takes a little time but since it is outside the loop it is not a big deal. Maybe 60 seconds. In contrast with the Excel reader… around six minutes per load. I.e: 5 hours when I get to the 50 files mark.
This is the reason why I wanted a simple loop. As minimal as possible. Only reading inside the loop.
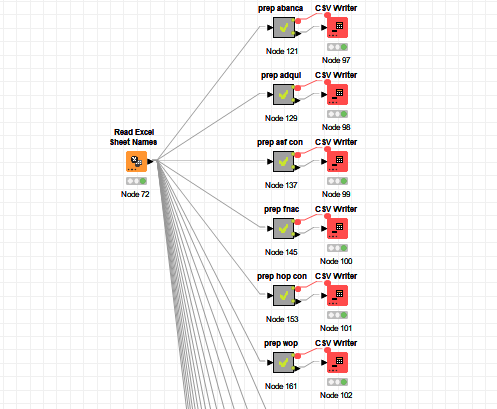
I think I will try making one csv per sheet and downloading to local.
Keep you posted?
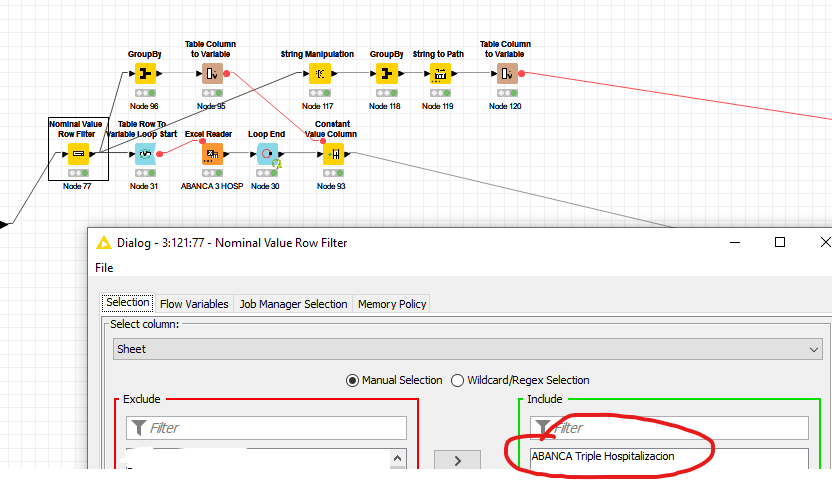
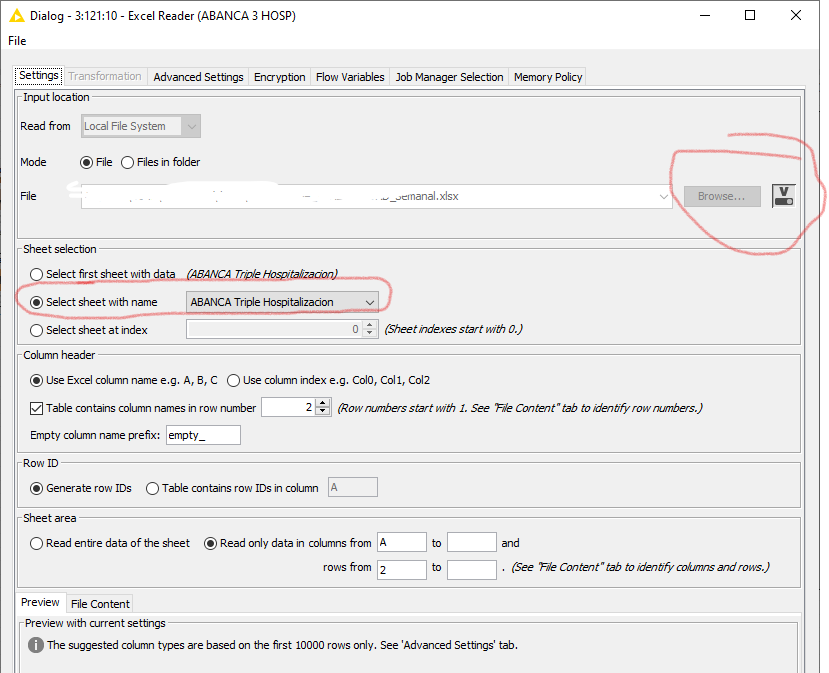
2º I give the indication via the loop to the Excel reader of what I need it to read. I find this step to be highly important. It has to read “file”, not “files in folder” via the flow variable.
After that, the rest of the workflow is prepping. As you can see, the tedious part is the set up. I have to make one per sheet, whis is slow and manual, but once I have it ready, it is so much faster.