I have a table with column containing IDs. Not all rows are filled with IDs. I need to filter table starting from the first filled ID down. Is there a fast way to do this?
So, just to be clear, you’re looking for this result:
Starting Data:
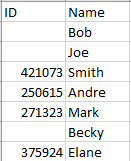
Filtered Data:
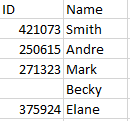
Is this correct?
1 Like
Yes. This is what I need.
Hi @izaychik63
This workflow contains several ways of doing this
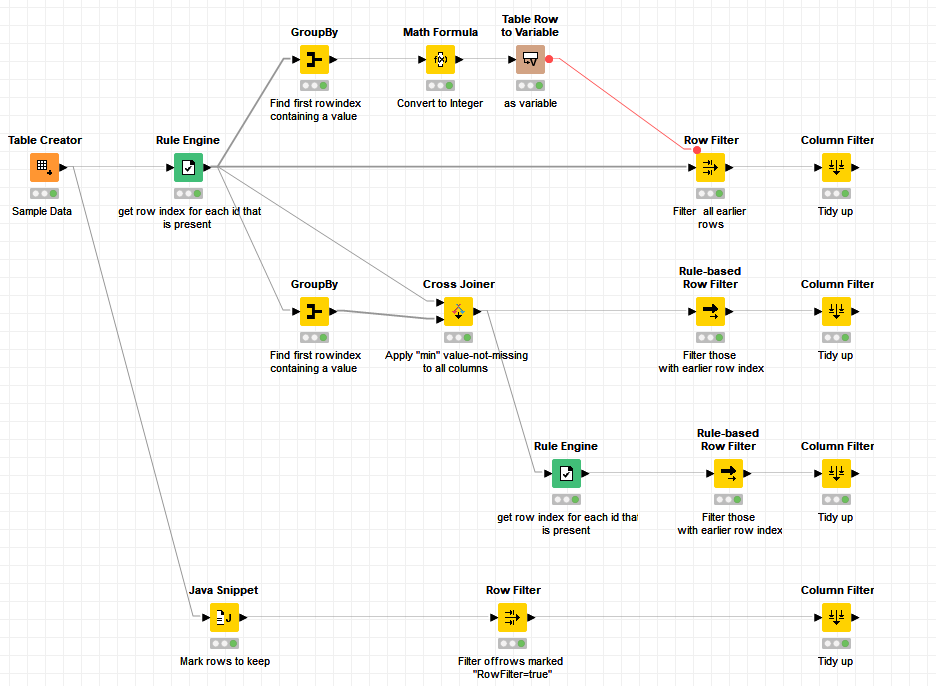
Find first non missing and filter rows.knwf (37.4 KB)
I used the following sample data:
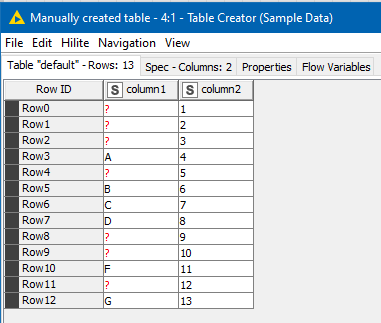
and produce the following output:
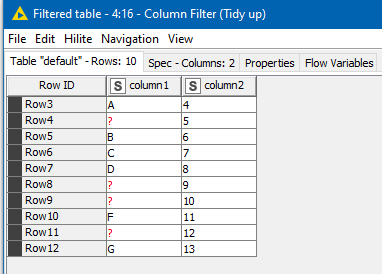
The first three all use a similar method. It is to mark every row where a value is NOT missing in column1 with its ROWINDEX. It stores this in a new column “value-not-missing”
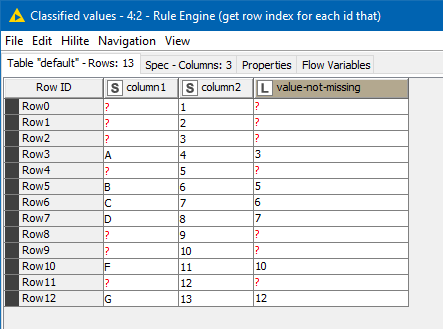
A GroupBy is then used to find the minimum “value-not-missing” and then this is used in different ways to filter off the earlier rows.
(1) By turning it into a flow variable that is then used as the lower bound in a Row Filter
(2) By cross-joining the value and then using a Rule-based Row Filter to skim off the “earlier” rows
(3) By cross-joing and then using a Rule Engine and a Rule-based Row Filter to skim off the rows.
I did both (2) and (3) to demonstrate one of KNIME’s “less than finest moments”, and more importantly warn that the value of $$ROWINDEX$$ returned by the Rule Engine is different to the value of $$ROWINDEX$$ returned by Rule-based Row Filter. One of them is zero for the first row, and the other is one for the first row, which is not great, and easily a source of confusion and error.
The final option uses a totally different approach and is “low-code” rather than “no-code”. It uses a feature of java snippets to determine which rows to keep.
It creates a boolean column called RowFilter which will be set to false until the first row containing a value in Column1, at which point it will be set to true.
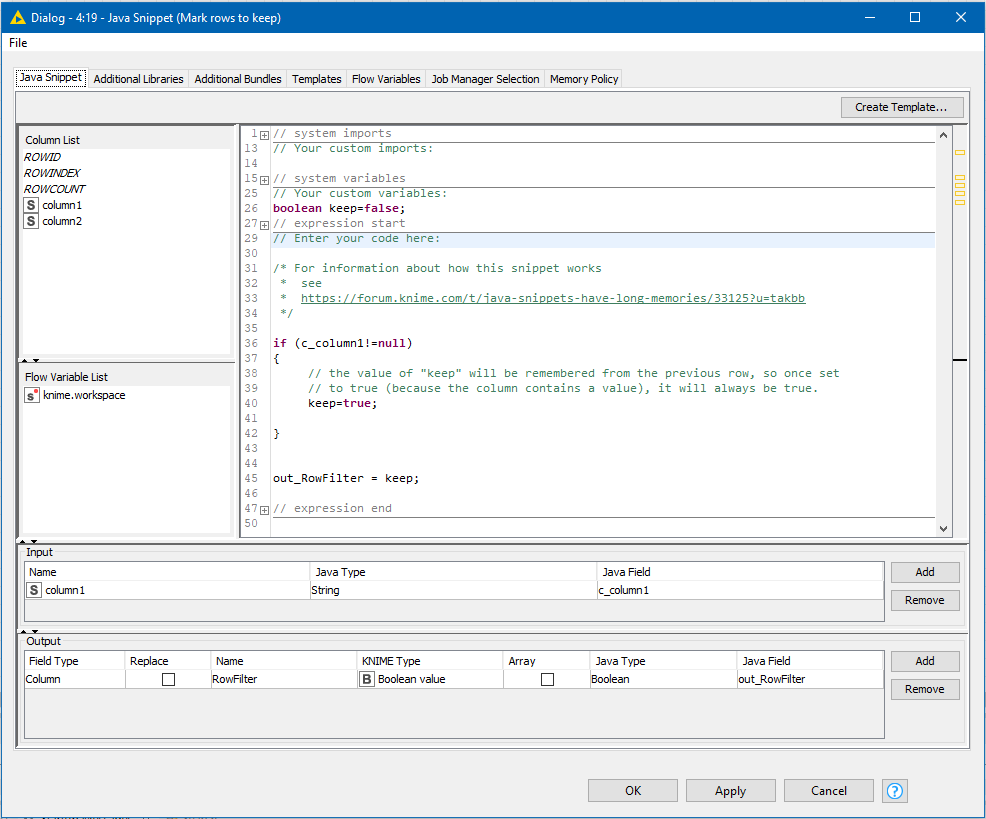
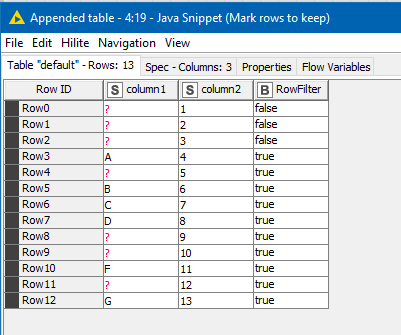
This can then be filtered with a Row Filter.
Hope that helps.
5 Likes
Thank you @takbb . That’s impressive.
2 Likes
Hey @takbb , I’m surprised by the Java Snippet’s behaviour. Usually, I would expect any node that’s attached to a table would completely apply to each of the rows of the table, so I would have expected all the lines in the Java Snippet to be applied to each row, including the initialization of the boolean variable keep to false (line 26).
As per your comments, and confirmation from a test I did (basically the same data and code you used), why would the variable keep not initialize to false for each row?
Thanks again @takbb. I made little optimization to your first line solution.
- Replaced Rule Engine with Column Expression.
- As far as result from Column Expression is Int, I excluded Math Formula.
1 Like
Hi @bruno29a , I agree that on the face of it, it is counter-intuitive but it is also quite a useful feature if used with care.The link to my post “Java snippets have long memories” that I put in the previous comment gives more examples, but essentially, there are two places in a Java Snippet that you can initialise variables:
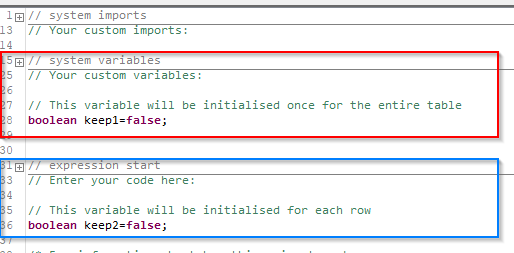
A variable defined in the “Your custom variables” (red box) section is initialised only once when the java class representing the node is instantiated which occurs only once for the entire table during this invocation of the workflow.
A variable defined in the “expression start” (blue box) section is in the piece of code that is invoked for each row, and so will be initialised for each row processed.
In effect, therefore, a variable from the red section “retains memory” from the previous row invocation (i.e. the previous row). You cannot directly reference anything from the previous row, but it is useful to know that you can retain some information. (And of course also useful to know that this is how it works if you don’t want to retain previous information either as you could fall foul of this if you don’t realise it!)
2 Likes
Thanks for the explanation @takbb , so it does matter where the variable is declared then, I did not know that.
EDIT: Ahhhh, now I understand why, there is actually code in between, which I did not see until I expanded the [+]. Now it all makes sense why.
2 Likes
Exactly! It surprised me when I first “discovered” the behaviour quite by accident. It’s not clear from the documentation that it behaves this way, but just like you, once I looked at the underlying mechanism by which the snippet is built, it makes sense!
1 Like
Awesome explanation (as always @takbb ) and highly appreciated.
My idea (borrowing Brians solution) is using the moving aggregation as cummulative and return the MAX value
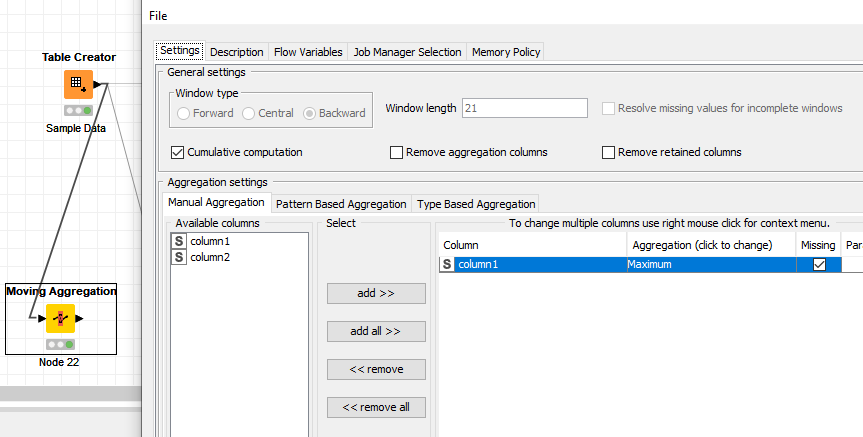
Then I could add a row filter node afterwards
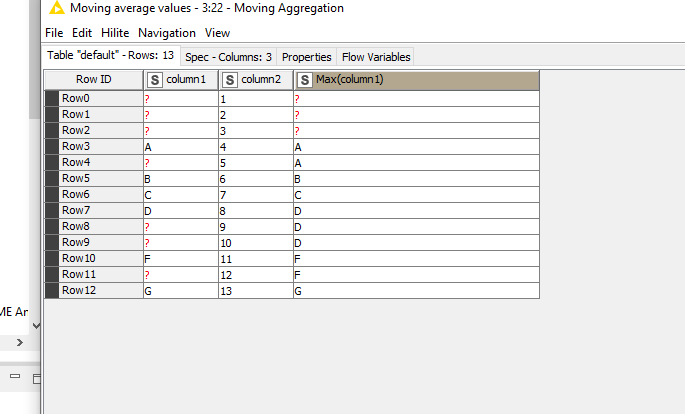
Maybe that could be applied as well
br and enjoy your evening (depending where you live 
6 Likes
Hi @Daniel_Weikert , Thank you for your kind words as always. And I really like your solution! It is better than mine: straight forward and without all the fuss of my proposals
I think @izaychik63 should now mark yours as the solution!  (and enjoy your evening too!)
(and enjoy your evening too!)
1 Like
Thank you, @Daniel_Weikert. It is very elegant solution. Now I just need to filter not empty.
3 Likes
Nice alternative @Daniel_Weikert , would not have thought of this one. 
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.