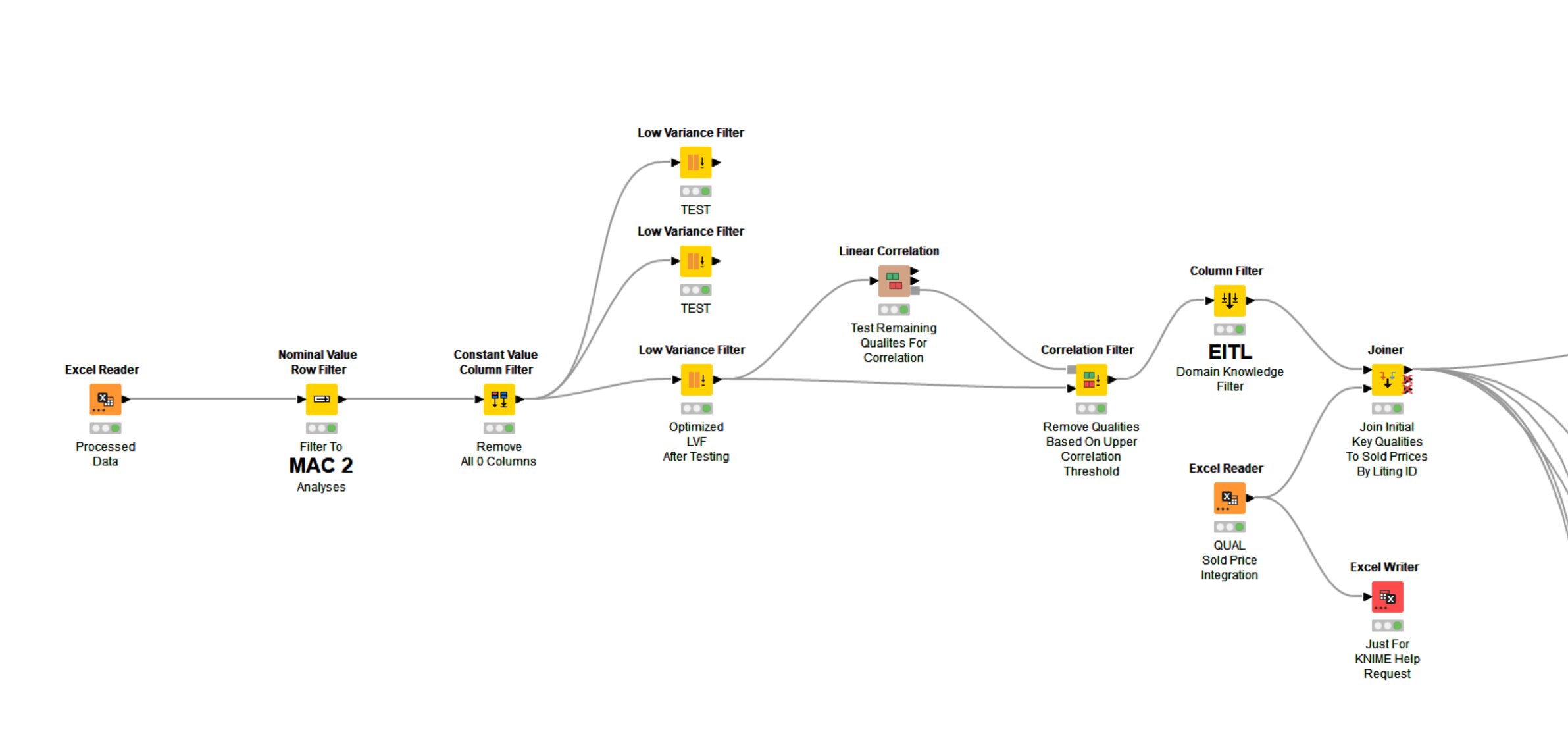
I’m trying to solve for the qualitative features with the highest impact on values of homes, based on feature analyses of past sales. I will do this sort of analysis separately with quantitative features (square feet, etc.) and then once more with location features (named geocoding + additional location features). In the end pulling all of this together for the final model.
Please take a look at what I’ve done with each of five models and tell me where I went wrong. My biggest questions are in red near the end of each model.
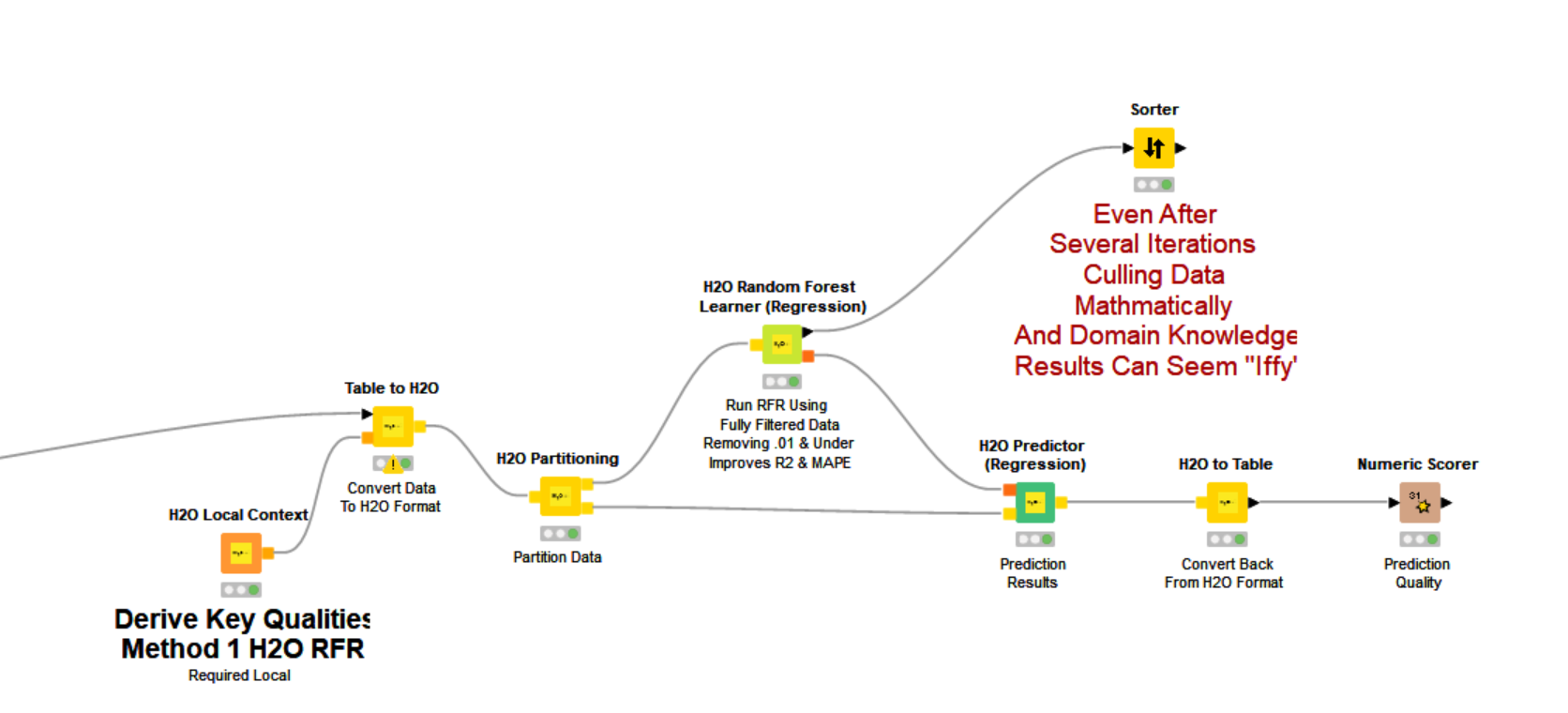
Because the current models have only a portion of the final model data (qualitative), the R2 is low for the time being.
Oh, while each feature has been assigned a unique token identifier, I converted each to either a “1” if present for a house or a “0” if not present. I was trying to avoid skewing the potential feature importance with an arbitrary numbering system. Tell me if that was a stupid idea. Each individual house is identified with a “ListingId” in the data.
I used and attached here the five feature importance models after spending days reading on the topic and staring at KNIME WFs online.
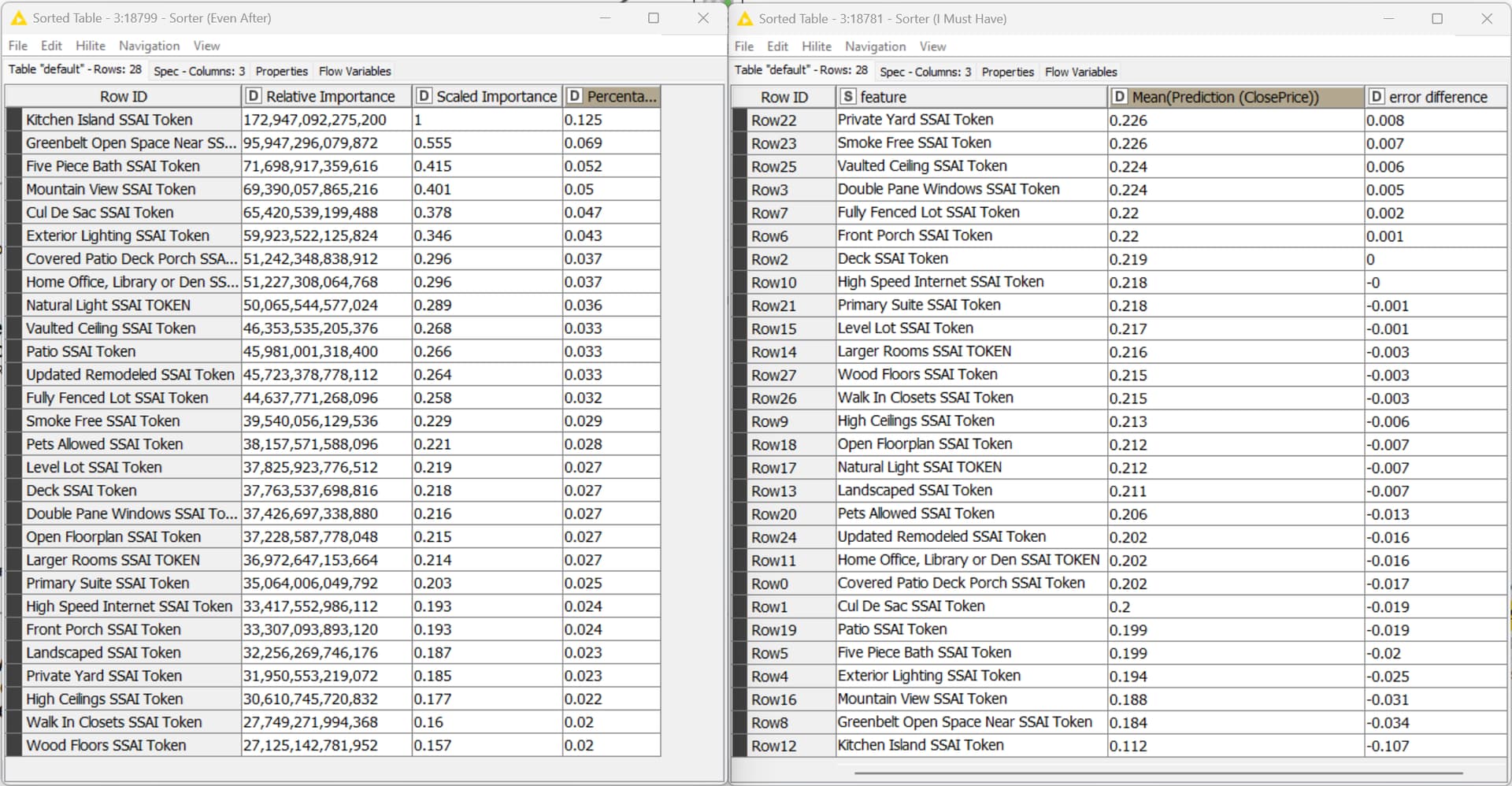
As I read would happen, all of the methods came up with often substantially different answers to feature importance based on the exact same data.
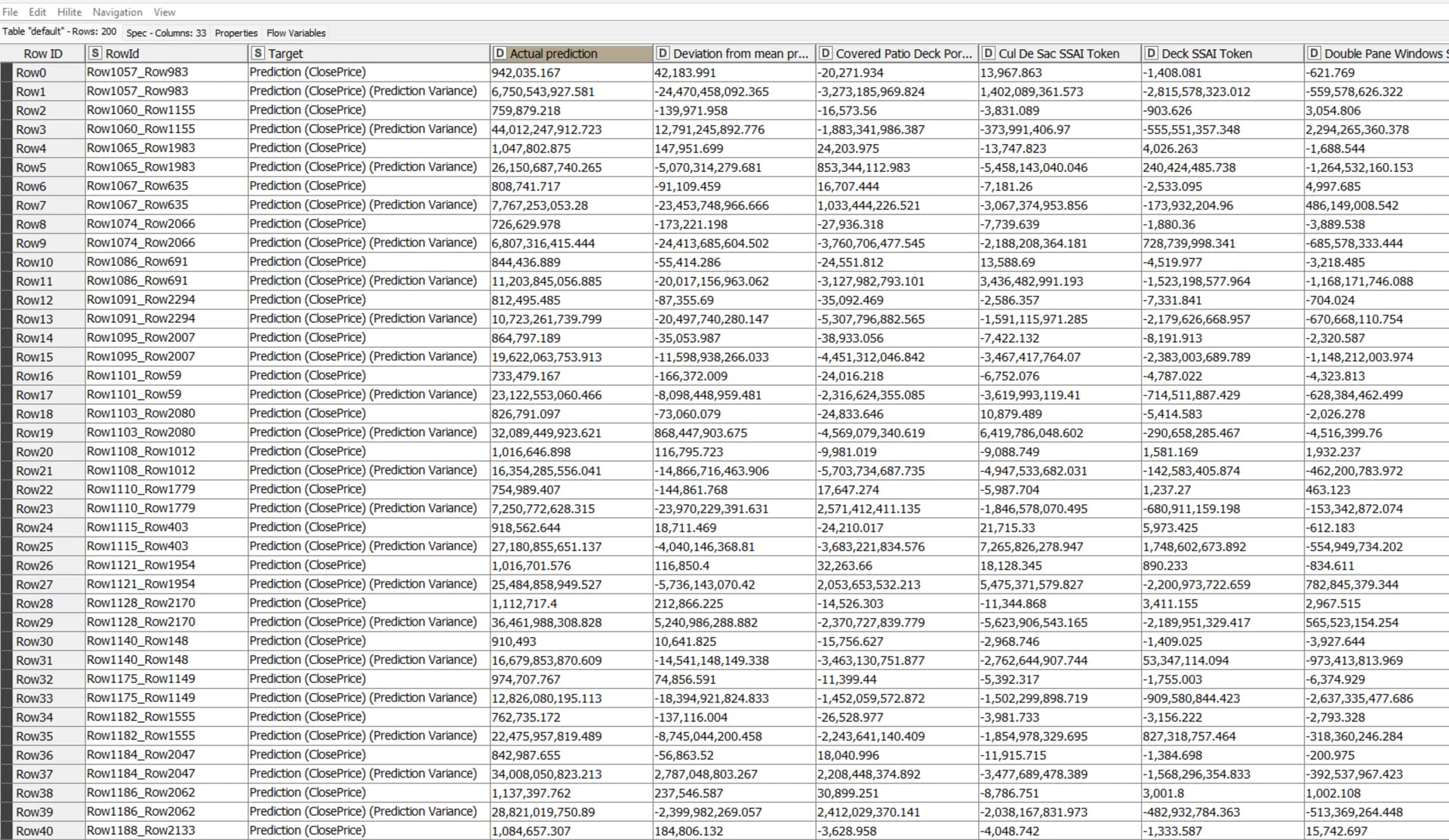
The final research stated that SHAP was the magic bullet to the faults of all other methods. I tried it, but cannot figure out what to do with the results which seem to fly in all directions.
Thank you–I think this discussion may help many of us out here doing real-live feature importance analysis in the marketplace.
I’m attaching WF and Data.
The working data has been split into three groups (you have only one) based on a Clustering Algorithm prior to any of these analyses.
I’m using 5.4.0
Sold Prices by ListingID.xlsx (60.5 KB)
temp for shap testing.xlsx (1016.9 KB)
Feature Importance.knwf (194.8 KB)