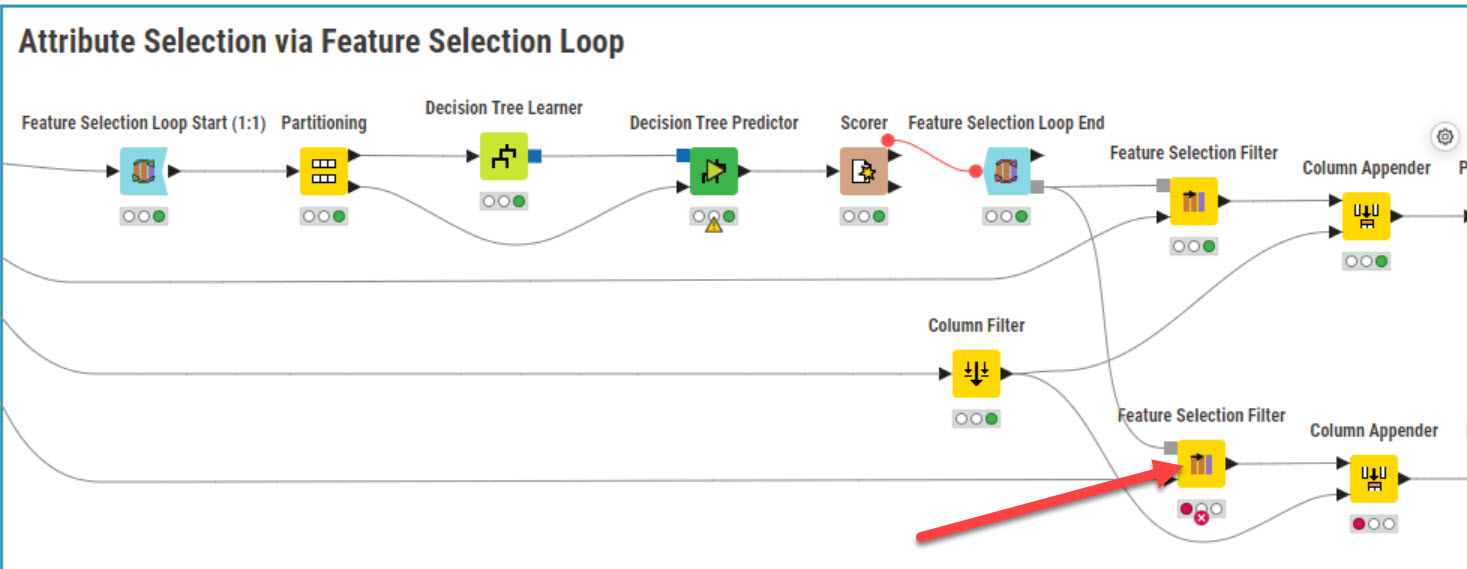
Too many features slowing your #ML model? @nilotpalc shows how to use #KNIME & its #Weka integration to perform #FeatureReduction in a loan approval dataset and streamline modeling, improve performance, and reduce storage needs. Enjoy the data story!
PS: #HELPLINE . Want to discuss your article? Need help structuring your story? Make a date with the editors of Low Code for Data Science via Calendly → Calendly - Blog Writer
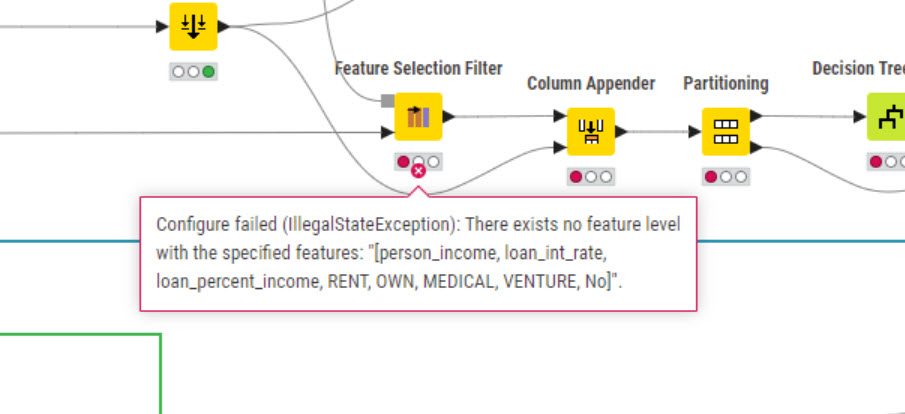
Hi @rfeigel, that’s expected since the input ports of the failing node are passing data columns that are likely to change a bit at each execution (e.g., there’s no seed set in the Partitioning node).
Additionally, the author decided to select manually the features to filter out for higher control on the process (check the configuration of the failing Feature Selection Filter node). This is just a workflow design choice.
How can you fix the problem? Either set seeds for reproducibility and then manually select the features to filter out, or simply select some other filtering condition in the failing node (e.g., “Select best score” ).