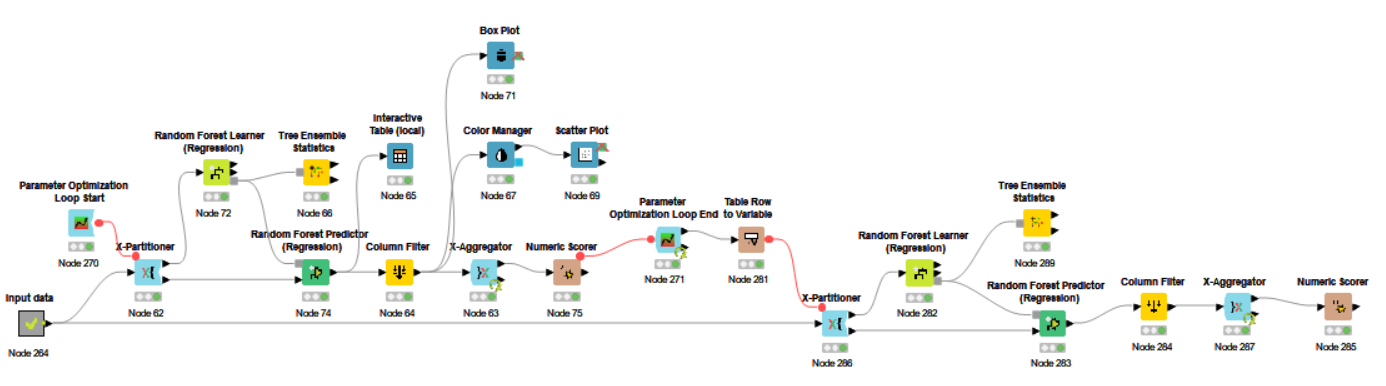
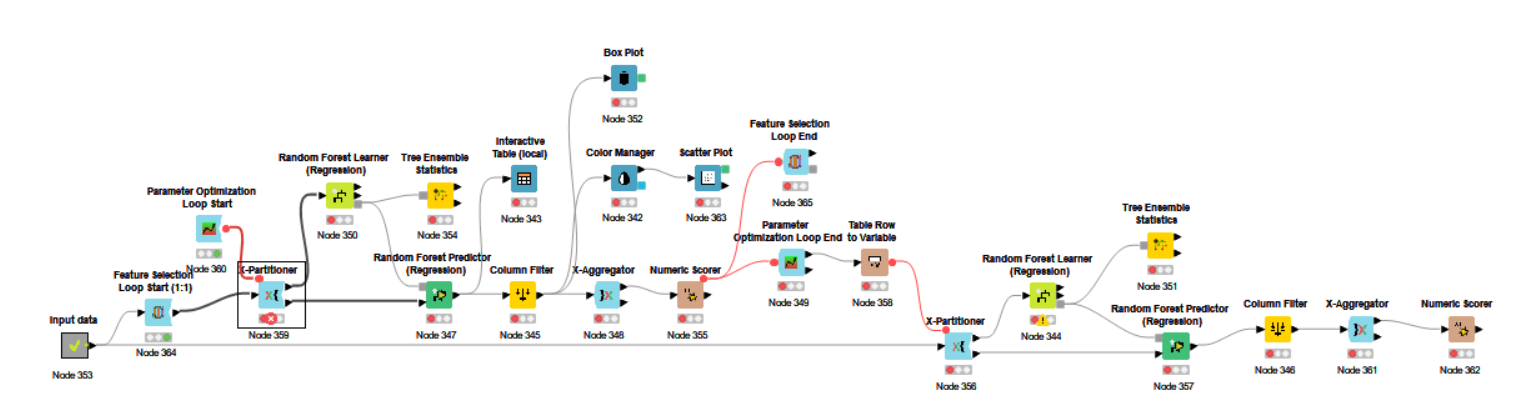
I have built a random forest regression model for prediction. I intended to include feature selection in my current workflow to improve the performance of the model. Can someone assist me?
By the way, please let me know if there are any suggestions or mistakes in my workflow.
I want to do the selection before the k-fold cross-validation but it seems to have some errors. I’m still new to Knime as well as machine learning. I will be glad if someone points out my mistake and give suggestions to me on how I need to improve it.
You have several nested loops here that are going to cause headaches from a troubleshooting perspective. If nothing else than to better understand how each type of loop works, I would approach this in a sequence before trying to nest anything.
Do feature selection to reduce dimensionality of your dataset
Do parameter optimization on your chosen classification algorithm, using the simplified dataset
Once you have your hyperparameters, use K-fold cross-val to evaluate model stability
Here’s some other stuff for you to chew on down the line, since you mentioned you’re new to machine to learning:
What is the static random seed? Is it important to enable when training a model?
I found out that there is a node called " AutoML (Regression)" which contained various models. But I have no idea how and what node should connect to it. Where can I find any examples of the node application?
Do I need to optimize the number of folds in cross-validation to obtain better results?
How to know whether the model is overfitting or good performance?
Lastly, is there any procedure or method that I missed out on or I should include in the workflow? For example, dimensionality reduction. Do I need dimensionality reduction in my workflow?
Many models are stochastic in nature meaning you get different results. In general with a random seed you can fix that and ensure you can reproduce your results when running it again
Daniel has answered several of your others questions. About #1, how large is your dataset? The varying results you are seeing make me wonder if it might not be very large, and therefore the sampling is having a more pronounced impact when you run it multiple times.
I might try a few of the simpler dimensionality reduction strategies mentioned in the blog post I linked prior to running feature selection. Then see if you are able to get more stable results. If you aren’t able to stabilize your predictors then you may want to use most of them just to be on the safe side (20 isn’t that many anyway).
Also, if you have additional questions, it would be best to upload the latest copy of your workflow along with some sample data, assuming it’s not confidential. We can only surmise so much based on screenshots alone.
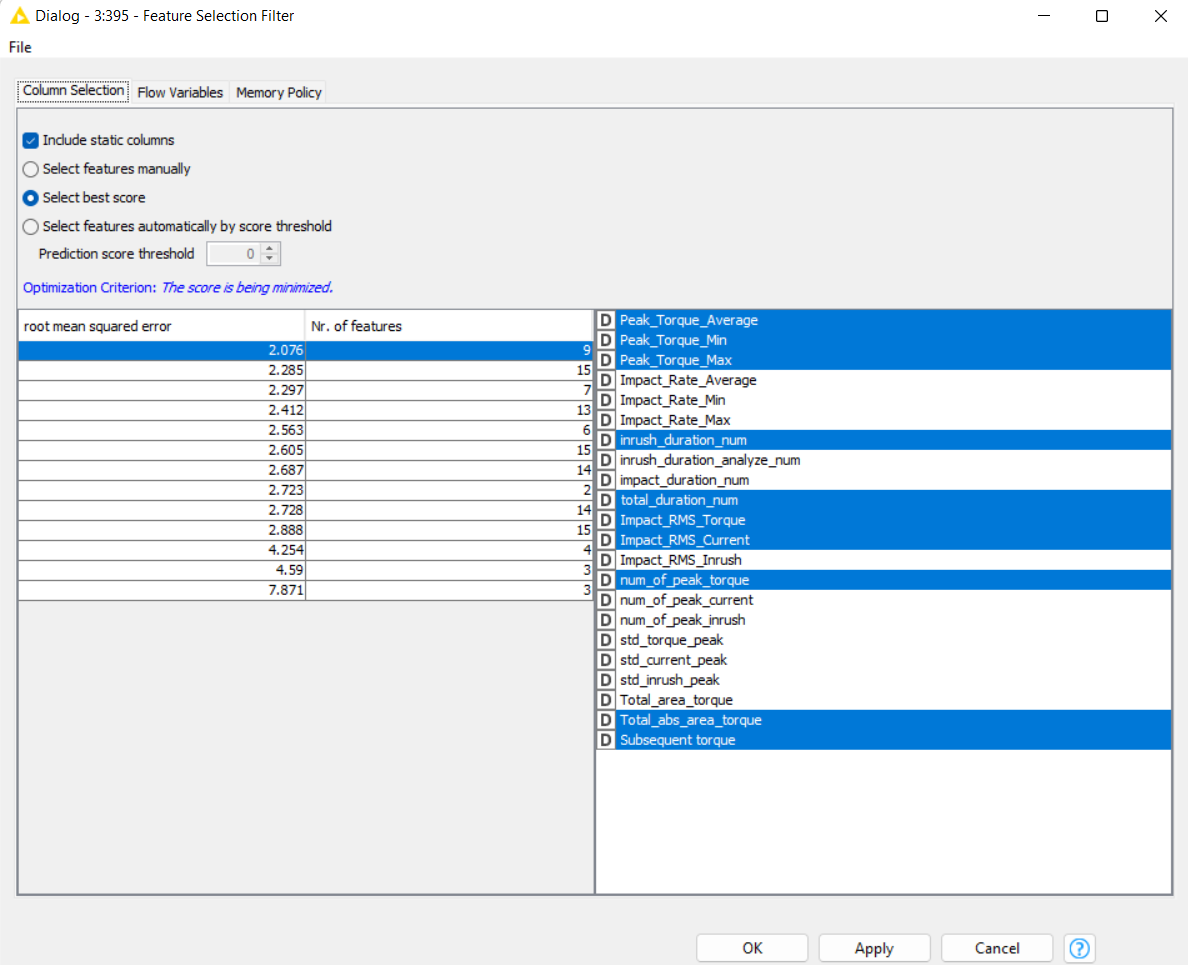
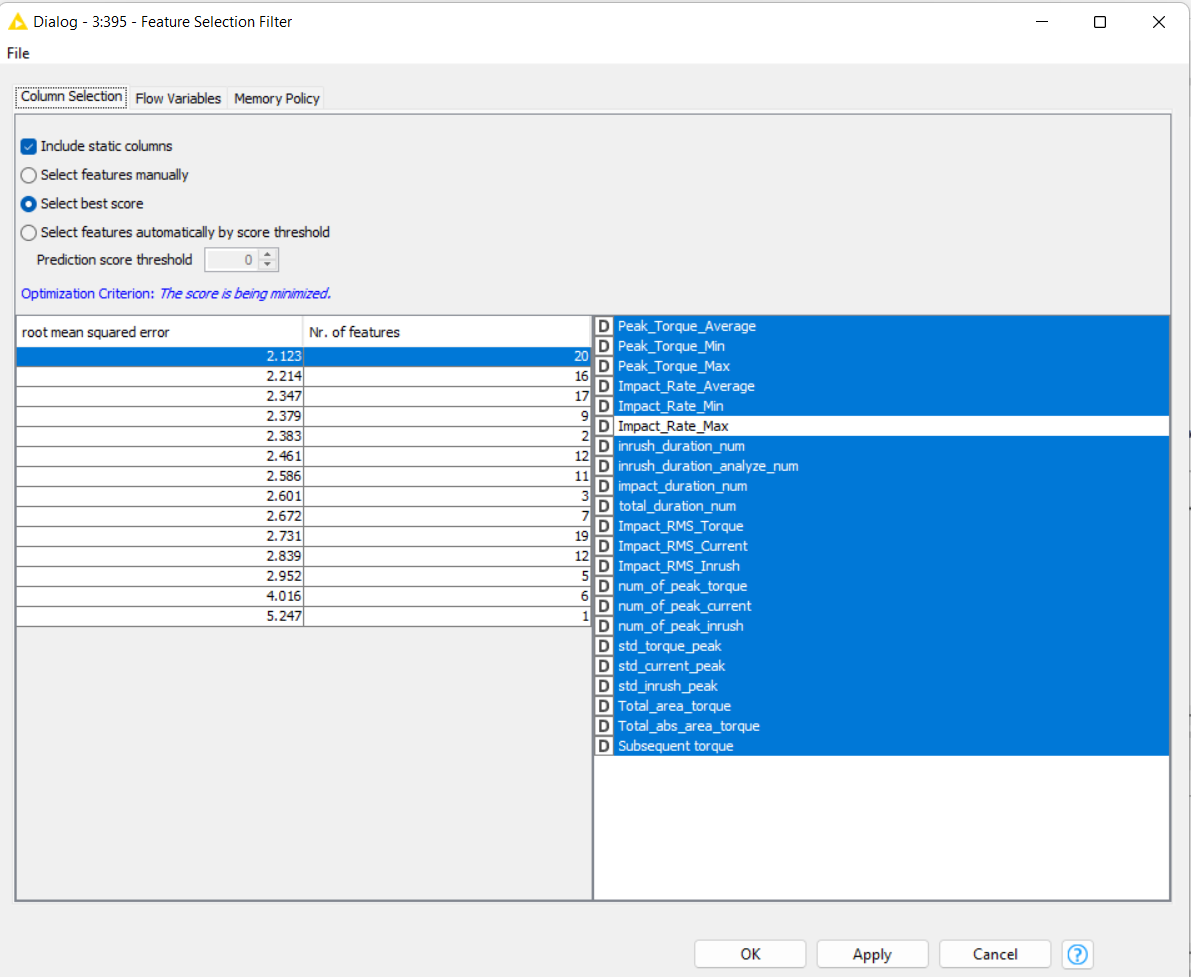
I have a total of 199 datasets. But it only left 150 datasets after filtering out the missing values and outliers. There are various dimensionality reduction methods available. How do I know which one is suitable for me?
I have converted the file from CSV to XLSX as I can’t import CSV files.
As I suspected, your dataset is pretty small (only 150 rows x 22 columns). This explains why each time you run the feature selection, you get such different results.
Usually you are concerned about feature selection when training the model would otherwise take too long, or would be too expensive. In that case you are trying to find a simpler version of a model that still retains as much as the explanatory power as possible, compared to the full set of input features. There’s not a need for that with your dataset.
The motivation for parameter optimization is finding the best combination of model parameters to give you the most accurate results. Here you still usually have a tradeoff to make in terms of searching for best parameters vs accuracy - but again you don’t really need that approach, since everything runs so quickly anyway. Even the Brute Force method of parameters optimization that you’ve chosen, with ~3000 combinations, still runs in a minute or so.
Long story short, you would see more realistic things happening here if you had a larger dataset. Since this sounds like it is for an academic exercise anyway, you’ve put the workflow together nicely to see how the various approaches work. But given the tiny input data, what you’re seeing is expected and nothing to be concerned about.
The reason why I’m including the feature selection in my workflow is that I worry that there will be some features that are not so related to output prediction that are present in the dataset that might affect the result.
The advice that you gave me is to remove both feature selection and parameter optimization. Am I right?
May I know the size the dataset that can consider as larger dataset? Should I increase the number of rows or the number of features?
How should I deploy the model after satisfied with the result?
As far as I know Random Forest as a tree based algorithm is normally using entropy for splits and therefore should be able to select the best features (highest feature importance) by default without an additional selection.
But maybe some data scientists can add /comment here.
br