Am using the Feature Selection node in a linear regression model where the model includes dummy variables. I want to validate my understanding regarding the inclusion/exclusion of dummies with p-values indicating insignificance.
I believe that regardless of whether a specific dummy is significant or not, if one dummy is significant then they must all be included i.e. the (k-1) dummies actually included in the model as well as the reference dummy.
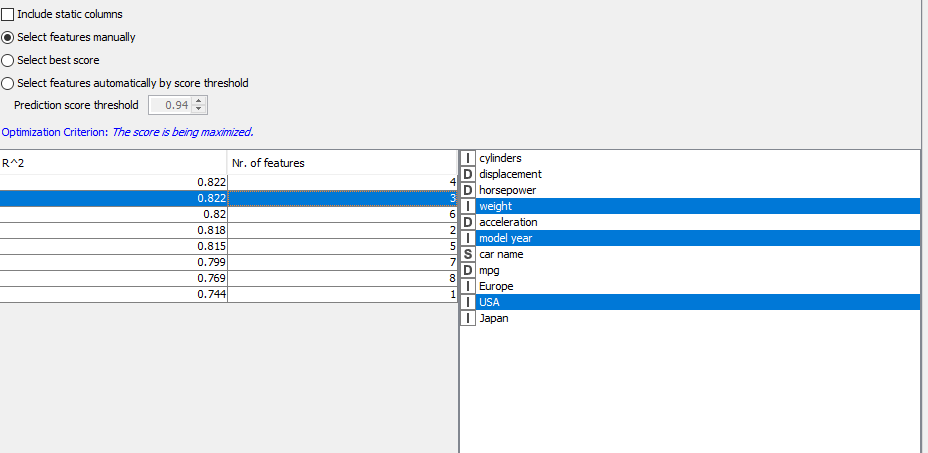
The KNIME Feature Selection Filter node will actually identify models where only one of the dummy variables is included in a referenced model. I believe this is misleading. How should I interpret the output of the Feature Selection Filter node in this case. Thanks in advance for any guidance!
Thanks Kathrin - Yes, “Europe”, “USA”, and “Japan” are the dummy variables. My point is that the feature selection node identifies models with only a single dummy variable included. As a practical matter, you would never deploy such a model i.e. if one dummy is important, then they must all be included in the model, otherwise, there is no way to interpret the regression coefficients.
In that case KNIME doesn’t know which of your columns are dummy variables and therefore can’t take this information into account in the Feature Selection Filter node.
On the other hand if you don’t create your dummy variables in advance and let the Linear Regression Learner node create the dummy variables in the background you will get the expected behavior.