I’m facing an apparent bug using Knime 4.4.2. I’m trying to load the dataset adult.csv (available within Knime core datasets), but the node File Reader (and CSV reader as well) is unable of handling the missing values.
The older nodes (which are deprecated now) could handle automatically the missing values of this dataset. Why does it happen? I’m missing some new configuration?
When I say about the node being “unable of handling the missing values”, it is due respect of detecting missing values when the file is loaded. I tried both File Reader and CSV Reader to load the adults.csv file, but neither could detect the missing values. All the missing values were loaded as question mark (?) string.
To help you to understand my problem, I’m uploading a MWE with the deprecated and new File Reader, so you can check the issue as well.
Hi @Kamusett , thanks for the workflow, but you did not include the file.
Regardless, missing values are usually marked as “?” in Knime, but not as “string”. A string “?” is usually black, as any data. A missing value is marked as a red ? in Knime. That’s how you differentiate between a string ? (black) and a missing value.
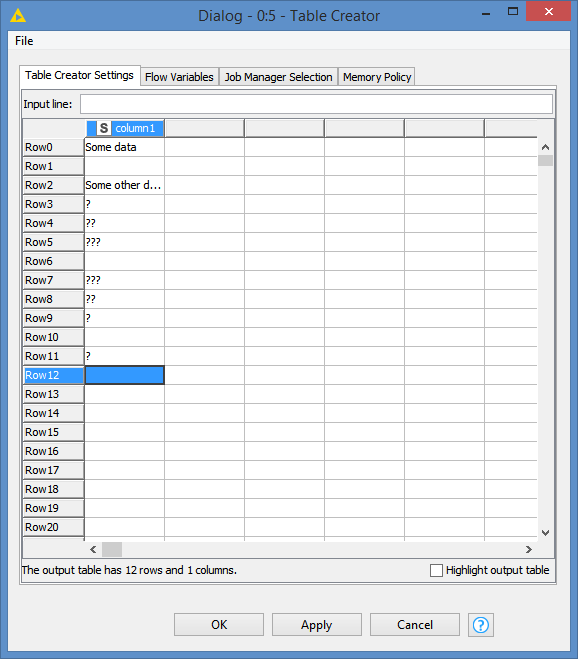
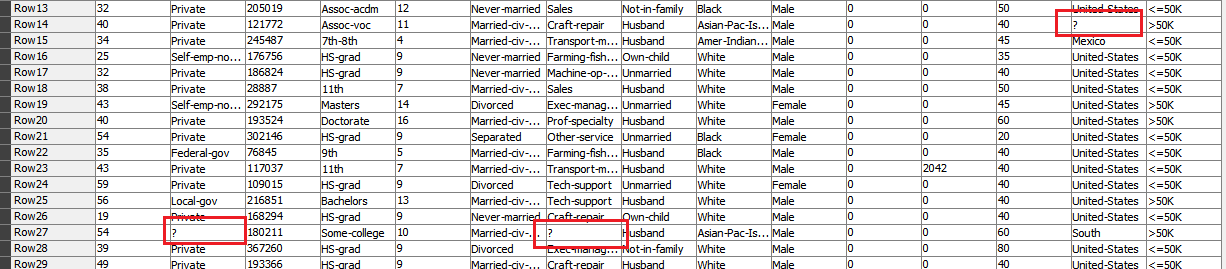
If you look at the following table I created. Here’s the input window:
I’ve mixed some missing values and some string “?”. As you can see, we should see Row1, Row6 and Row10 as missing values marked as a red ?, while all other rows should have data in black.
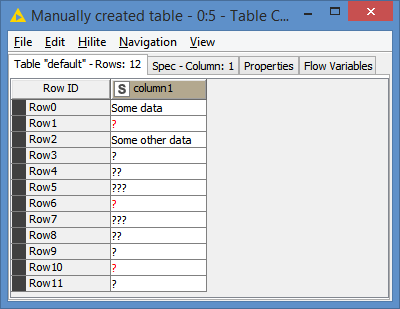
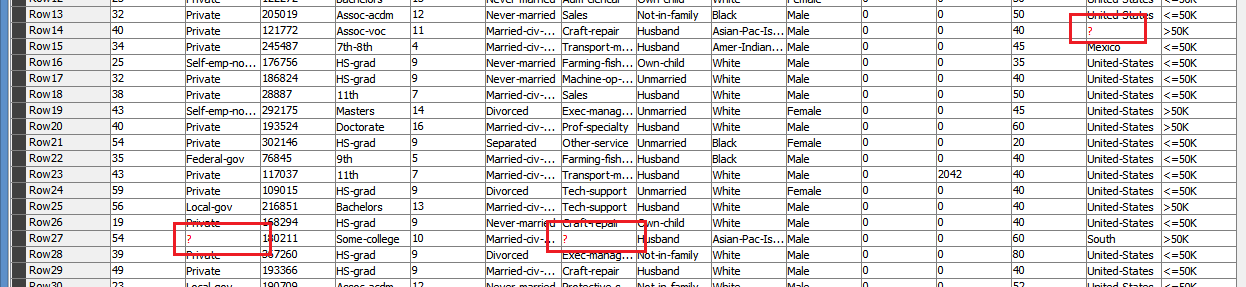
After executing the table:
As expected, Row1, Row6 and Row10 have a red ? as they have missing data, while all of the rest of the rows have data in black, including string ? or ?? or ???.
This has always been the behaviour in Knime as far as I know.
I thought the workflow kept the data loaded. I’m attaching the dataset right now. Please rename it back to CSV as I have to switch the extension to attach the file here.
Checking the file I noticed, the dataset has the question marks in it where the data is supposed to be missing. Considering that, I believe the better way to handle this is adding another node to filter the questions and replace with the missing value.
However that step wasn’t necessary Using Knime 4.3.x as you can check now with the data I’m sending to you. Is the new File Reader bugged, or it is just downgraded? adult.txt (3.8 MB)
Hi @Kamusett , thank you for sharing the data file.
The data is being separated by comma+space (like in punctuation), not just comma, which is inconsistent because the header is correctly separated.
Regardless, there does not seem to be any missing data from what I can see. There are literally " ?" as value for some cells, but they would be parsed as a string, and that’s what Knime shows, black “?”.
Hi @Kamusett , I re-read what you wrote. I would not say that it’s a bug, it’s how it’s supposed to work. At least that’s how the other nodes work.
I thought the File Reader always worked like that too, but from the deprecated version, it actually recognizes string “?” as empty, which it should not. Empty is empty, and string “?” is data.
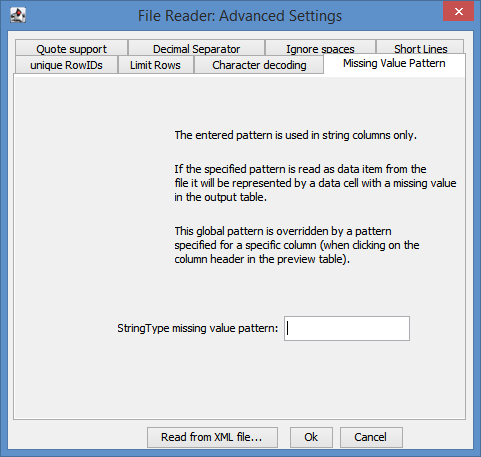
The deprecated version had an advanced setting where you could actually define any string pattern as empty:
So you could define string “?” as empty (which it seems to do by default).
This setting does not seem to exist in the new version.
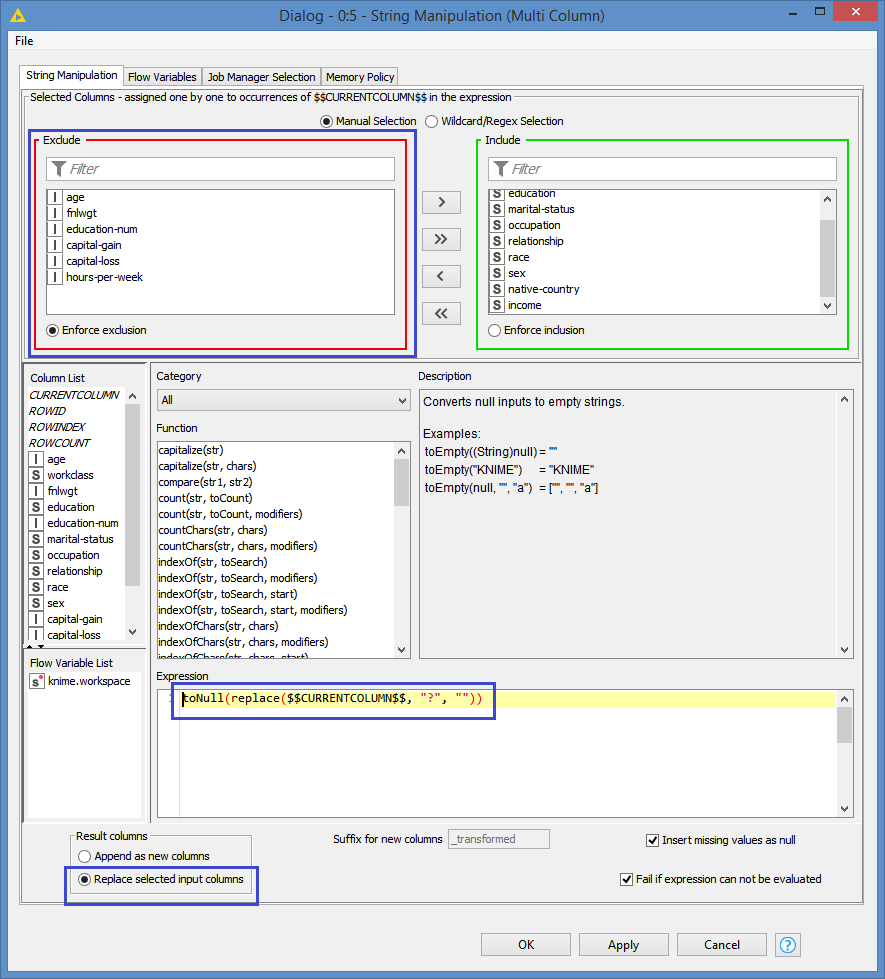
As an alternative for the new version, you can replace the string “?” to missing with a String Manipulation (Multi Column) with this expression: toNull(replace($$CURRENTCOLUMN$$, "?", ""))
Here are the 3 things you need to configure (highlighted in blue):
The explanation you gave me was perfect. Although I believe the new File Reader is more hard-working than the old one, it is, indeed, the right way to do.
Thank you for the solution. Fits perfectly in my dataset. Sincerely,