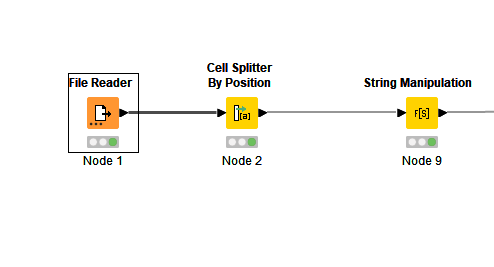
Hi all,
I need to load a .dat file and then assign it headers based on position.
I have 3 columns to assign. I did that and it worked well until I wanted to test in case a row would be empty for one column (I tested for column 1 empty in original .dat file). If a row is empty, the flow skews to the left. I believe Somewhere the nodes trim the spaces delivered in col 1? Would you know how to prevent that?
Splitting by position is only going to work if the character positions are always the same, so it might be that a different approach is necessary.
Would you be able to upload a sample workflow (with the pictured nodes) along with a copy of a small example datafile so we can try to see what is occurring in this case, and then we can make suggestions.
edit: Actually I just tried it with a file of my own using File Reader and I see it loses the whitespace at the beginning, even with the “remove quotes and trim white space” option not selected.