Suggestion
I’d like to propose, which would also enable reading a file w/o any row delimiter (just a single line), to accept an empty value too.
Explanation
Data, especially created, maintained or altered, is likely to face inconsistencies sooner or later. On several occasions I was required, in particular when semi formatted data was handed over, to pre-process it.
Addition
This very likely applies to any other reader node type as well.
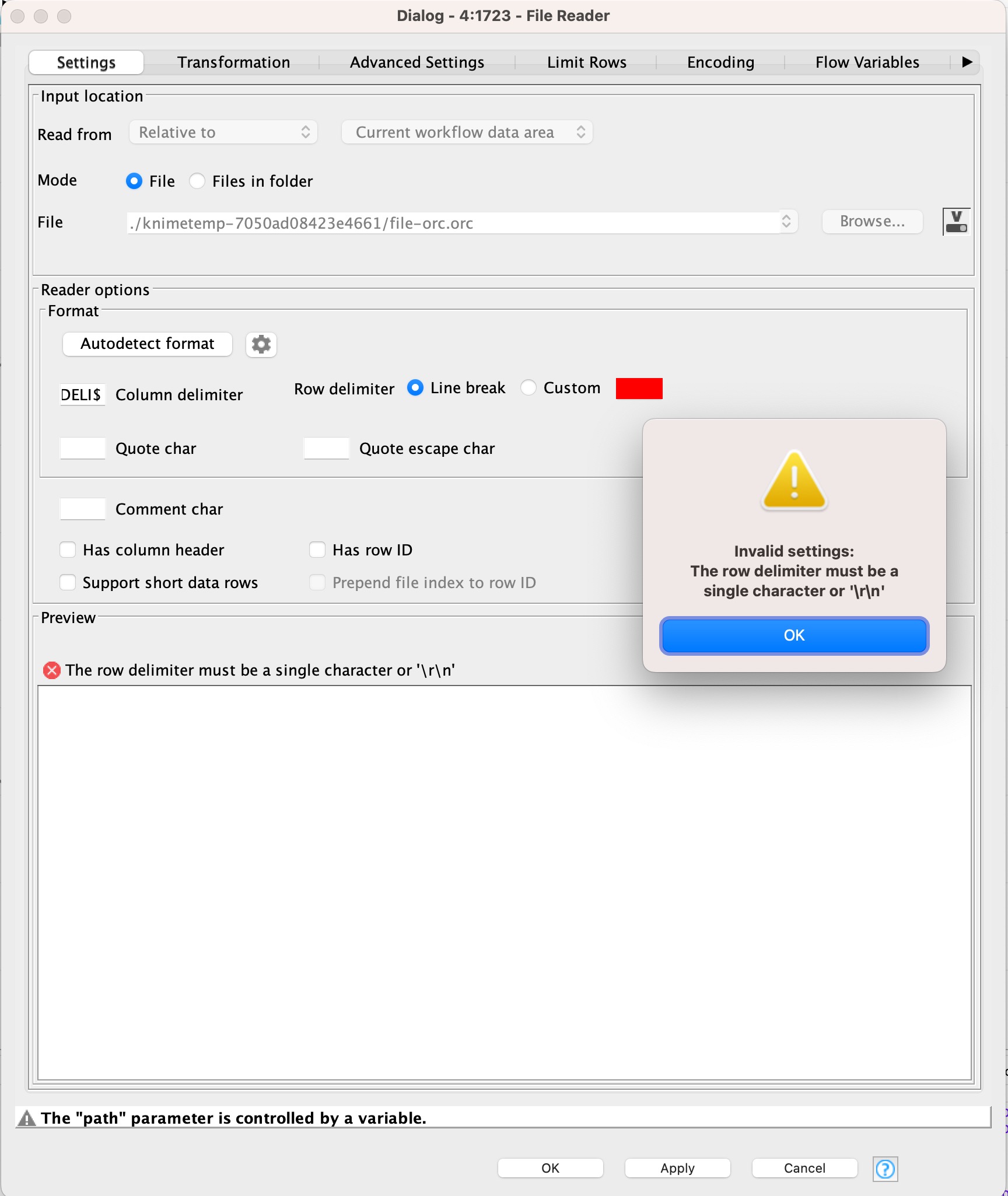
hi @mwiegand ,
the error message that you get is due to the fact that the custom input value does not get repopulated with the default value upon deselection. Seems like that KNIME complains even if the “Custom” option is not selected.
It looks like a minor bug, I will report that internally.
About your suggestion of reading the file in a single line, I did a quick experiment trying to read a whole file without delimiters (I put a special character as custom row delimiter). The first issue I can see is that the column quickly exceeded the max memory. Do you have a use case when this would be a crucial requirement?
many thanks for raising the ticket. About your question of use case to read an entire file as a single line.
Imagine you have semi-structured data or data which contains (caused by human error / copy & paste), line breaks in a data cell i.e. when reading Excel. You might want to, as I did frequently:
Read the data “raw” w/o line breaks, quotes etc.
Pre-Process i.e. by removing all line breaks and inserting special markers like $DELI$ based on pattern match (i.e. if every line starts with a date)
Use Cell Split Node to split into list based on custom defined marker (see above)
If necessary, I could generate a test workflow to display the explained scenario.