I am now doing text processing by importing few hundred text documents via flat file reader node and would like to add the filename as one of the columns so as to facilitate tables joining from other output from flat file reader. Can you suggest the way of doing this?
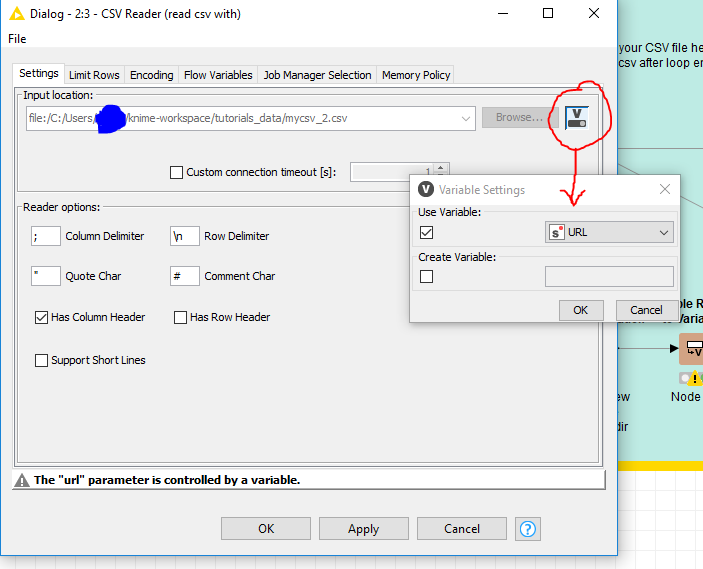
Regarding to the Flow Variable option, is it only applicable to file path, not filename? Or I need to use other node to extract the filename seprately from the file path?
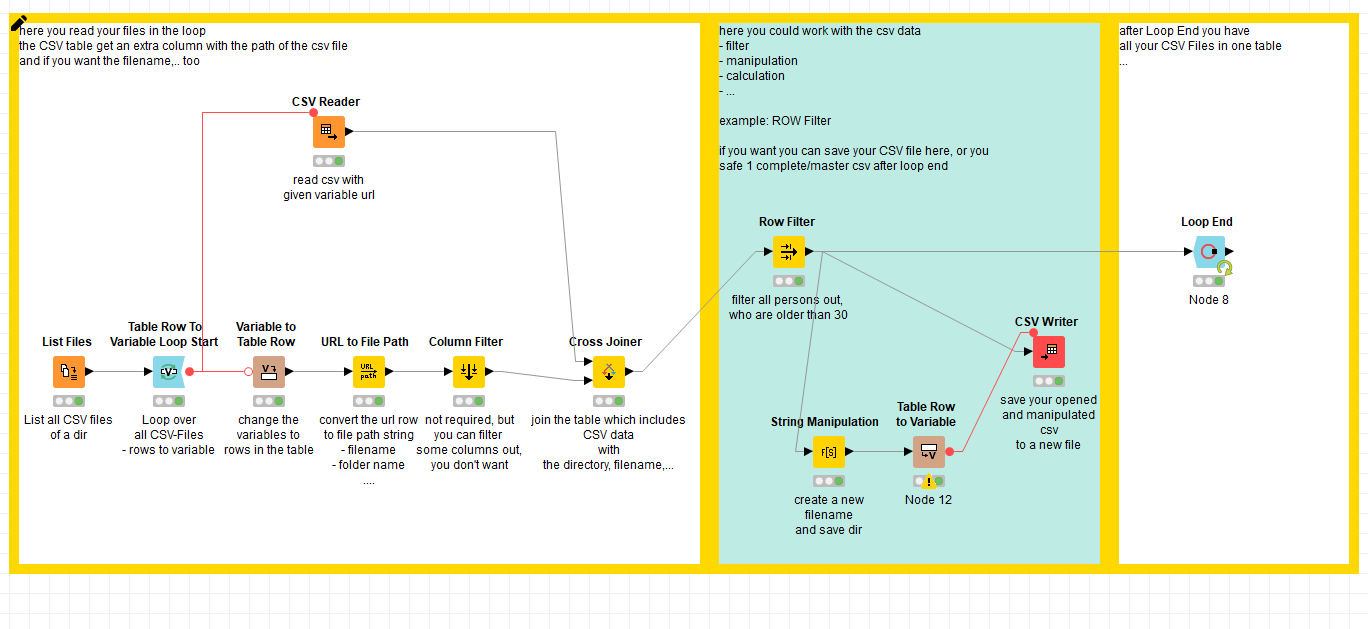
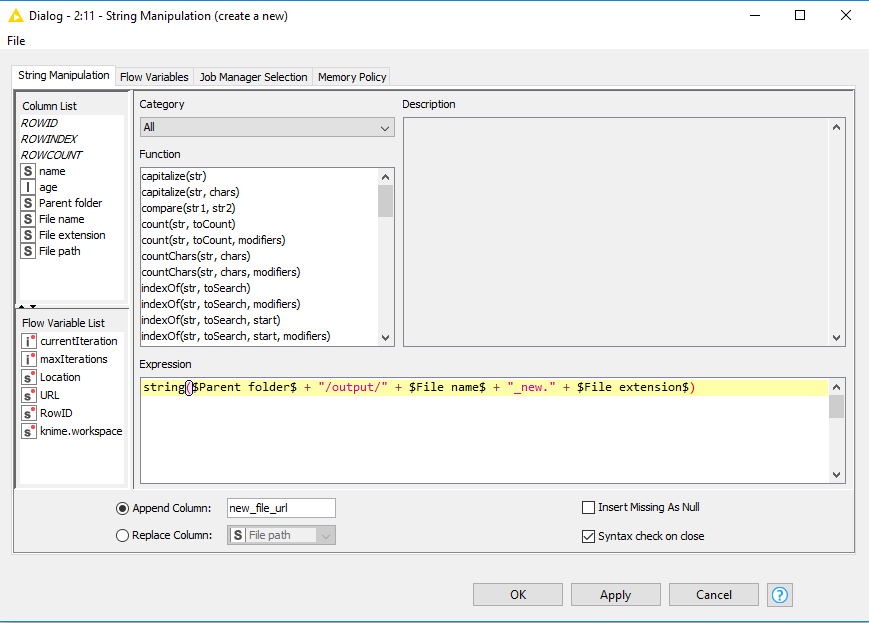
Sorry I didn't pay enough attention earlier, you will need to conver to extract the filename from the path using for example the URL to FIle Path as above or the some regex.
i don't know if this answer your question, but i solve it in this way...
i used variable to table row, to extract only the URL, then i used URL to file Path Node and after this the cross joiner to mege both tables...(all in the loop)
After the END LOOP i got a table with filenames/location for every row...
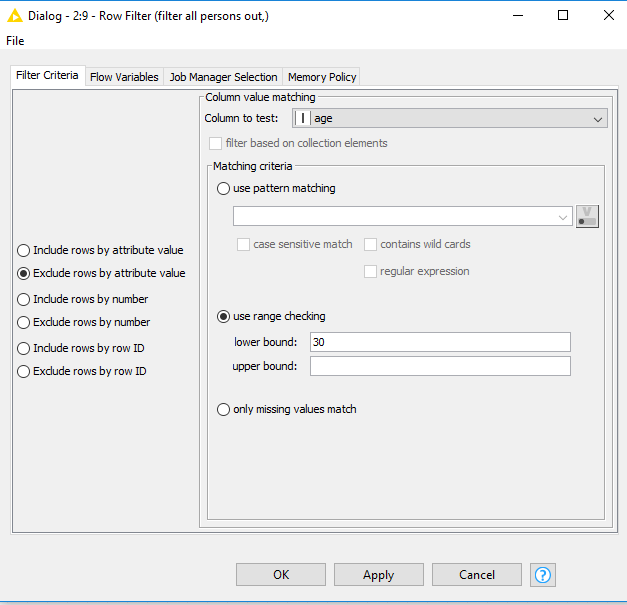
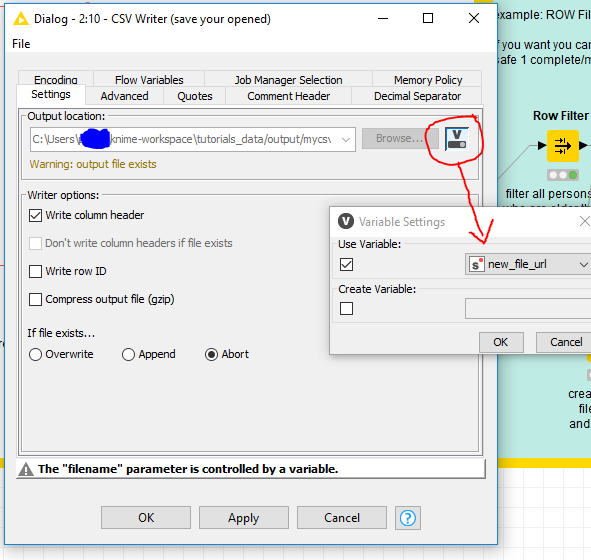
@Andi, I built my workflow based on your image, but I want each file to be saved with the new column or at least appended to a master table that has the file name column. But when I run the loop is just pulls in the next file, adds the column, dumps it an reuns etc.
How are these nodes configured to actually allow me to change the file itself in order to add the filename column and change the actual .CSV file or at least have a master table in my workflow that I can then export?
I have tried to follow your steps, seems like I m missing something in here.
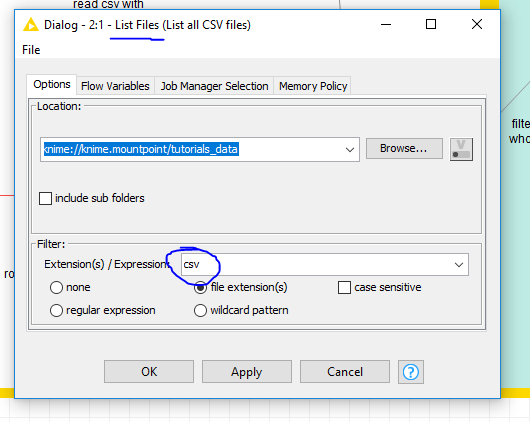
I would like to get files names wo creating new column for each filename
I stuck in URl to File Path
Can you please look at this?
I have to get filename (here month and year from file) for each file new_file.knwf (1.7 MB)