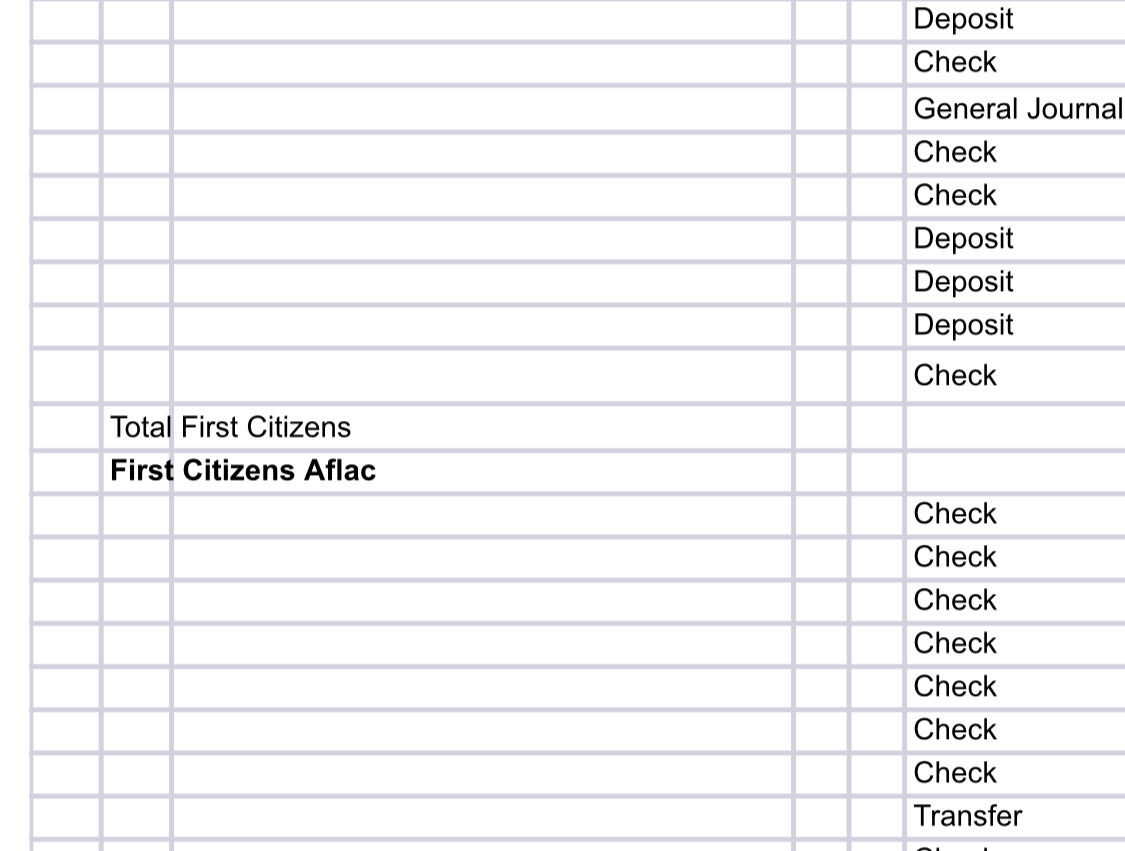
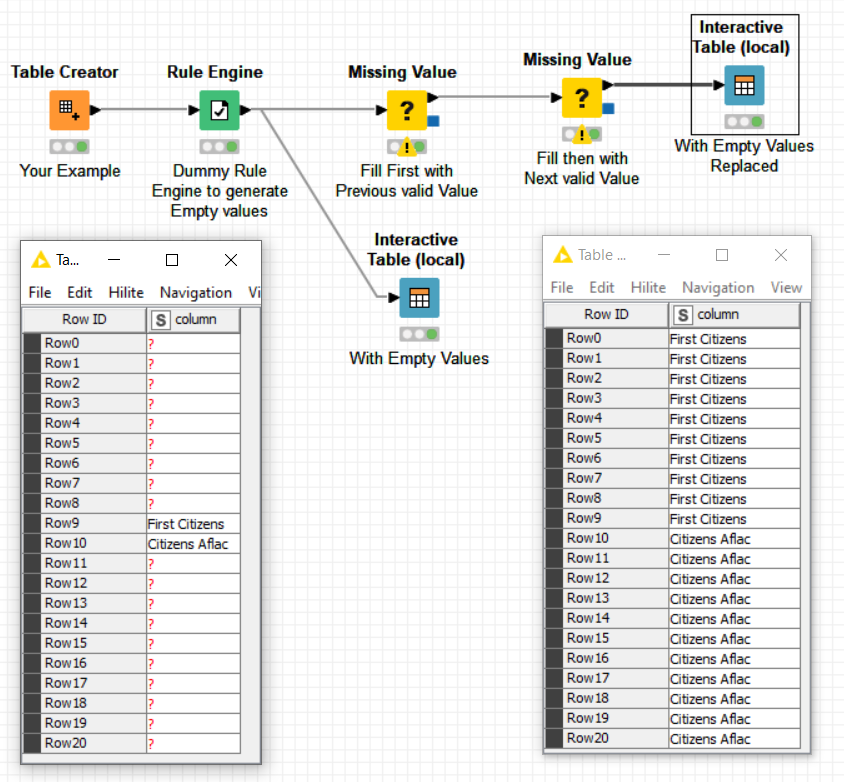
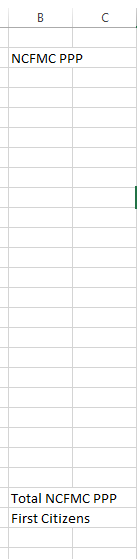
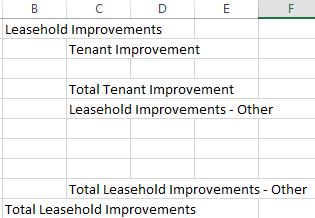
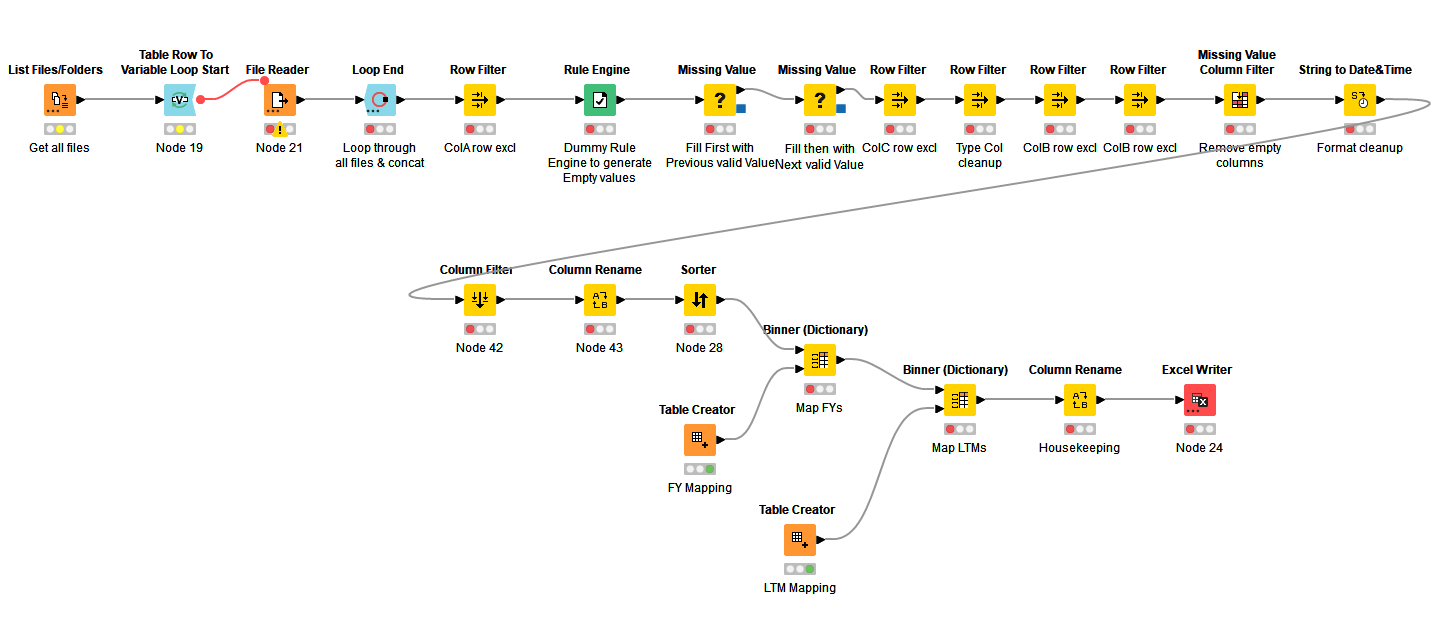
This worked. I’m still investigating, but is it possible that the rule Missing Value node is scanning all columns, or do I have to explicitly declare which columns it should not scan?
Book1.xlsx (15.6 KB)
The solution is very close. I realized that the second column is somewhat a function of the first column, so, ignoring the ‘Total’ lines as I can easily remove this with a filter, but how to this column - subcolumn filldown?
We kind of have two scenarios, with the first being: Simple
NCFMC PPP fills down, Total filtered out (I got this part), then start new with First Citizens and fill down. The second column has nothing to fill and should stay empty.
But then, gets somewhat tricky:
And the rows of actual data are somewhat in between the first and last row of the second column:
I was able to solve this with a minor modification of the above workflow - just required a delicate dance between the Missing Values and Row Filter nodes, as Row Filtering a column too early, removes necessary columns needed downstream for the Missing Values node.