I am at the very beginning of using KNIME and hope you can help me on the following issue.
I created a new workflow and applied already different row filters. The last filter I need to apply now is a filter based on a due date that is already contained within the affected Excel spreadsheet in a separate column. Only the rows with a due date less than or equal the first business day of the following month should be included in the output. This means in my case weekends and german holidays should not be considered when the first business day of the following month is determined. The idea is to have a dynamic solution, i. e. first business day of the following month should always be determined from the respective current date as calculation basis.
Any ideas how to implement such logic in an (hopefully) easy way and what the best way is to dynamically read the weekend and holiday dates as described above?
One thing is missing now. The public holidays for this, the easiest is to have a list. Or if someone finds a rest service with which you can get them. Than we could filter those in addition.
thanks for bringing up this example. Would it be possible to get the .knwf-file of this without violating your copyright: ? Then I could see how the nodes are configured in detail and would be easier for me to follow through.
I have a file of 60.000+ rows, but this would be a simplified input table:
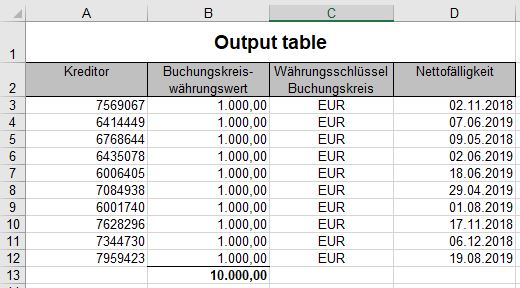
And this is how the output table should look like:
The first business of the following month from today onwards is the 02nd of September 2019. Therefore the rows with a due date (“Nettofälligkeit”) after this date should be excluded and the sum of all remaining rows should be calculated as shown in the sample output table. In addition it would be nice to know how this value could be written in a continuous data row within a separate excel file on a shared drive. The calculation should be done on each business and the calculated sum needs to be written in a new cell of the respectively next column with the date of the business day in the header. Ok - dreamed enough now for the time being
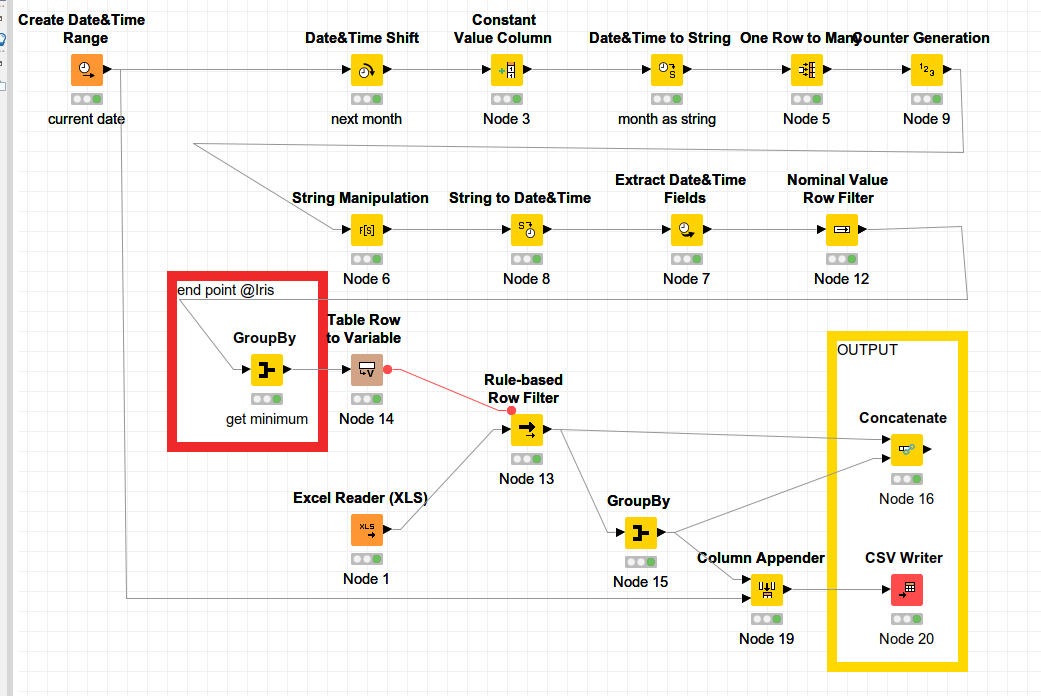
The created first business Monday of the month is used as a filter on the excel you provided. The 2 outputs are created, a table with a Total Row and a csv file that appends every time you execute the flow a new row with the date of execution and the sum of “Buchungskreis-wahrungswert”. first_business_day.knwf (75.6 KB)
NB: Not included are the German hollidays
thanks, this helped already a lot. However I have the following questions:
The workflow of @Iris does already determine the 2nd of September 2019 as first business day of the following month correctly, but in the following steps the selection of the rows with a due date less than or equal the first business day of the following month does currently not include the first business day of the next month. I tested this with this sample file: Sample input table 19.08.19.xlsx (8.8 KB) . The outcome is a sum of 10.000,00 € although it should be 11.000,00€ as the 2nd of September 2019 needs to be included. I checked the Rule-based row filter and it seems to be set up correctly with $Nettofälligkeit$ > $${SMin(Date&Time)}$$. Do you have any idea what goes wrong here? I wonder if it has something to do with the formats of the dates…
I prepared an excel spreadsheet with all business days of 2019 and 2020: Liste Daten ohne Wochenenden und ohne Feiertage 2019 & 2020.xlsx (24.1 KB). What is the easiest way to have this list considered within the workflow when the first business day of the following month is determined?
Interesting point; what goes wrong is the row filter (node 13…) does not handle the date-format from the excel file as expected. The format in the EXCEL is 2018-11-02T00:00 the format from the flow variable is 2019-09-02. If the format from the EXCEL input file changes to 2019-09-02, the row filter works as expected.
Join this file with node 7 and before node 12 (nominal value row filter). Join it on date (be careful with the different formats…), and a a filter node to select only the rows that matches. The Wochenden und Feiertagen are not influenced.
I had a look into this and made several attempts:
Yes if you check in the file preview of the Excel Reader (node 1) it looks like the format was like 2018-11-02T00:00. However if you check the date format directly within the input excel file it is *TT.MM.JJJJ (Gebietsschema: Deutsch/Deutschland). I tried it by changing that to JJJJ-MM-DD (Gebietsschema: Englisch/UK) and JJJJ-MM-TT hh:mm (user defined format). For all this constellations it was still the same outcome of 10.000,00€ without considering the 2nd of September 2019. It seems KNIME is always interpreting the date as in your example “2018-11-02T00:00” because the format of the column “Nettofälligkeit” does always look that way in the file preview no matter which date format I had in my input excel file. Is there any other way to tackle this?
I put in a Joiner node with node 7 and before node 12. The output format of the dates from node 7 is like JJJJ-MM-TT (checked that with a CSV writer node). I adjusted also the formats of the dates in my input file with all business days of 2019 and 2020. Nevertheless the joiner node still finds a type mismatch of joining the columns with the dates…
Overall the formating of dates seems not to be an easy one. Therefore your help would be very appreciated.
determine the first business day of following month based on today’s date (i.e. execution time)
filter your input file according to that
My approach to this would be to keep things as simple as possible. That means that you take 10-15 minutes of your time, take calendar and write down first business days for next 2 years in a txt file. This makes sense as it does not require hours of work, you are not doing this for 100 countries (rather only one) and it simplifies workflow a lot. All you need is to check that this file is up to date if calendar changes in terms of holidays Then you take this file as an input, filter it so it includes first business days of following month and create a flow variable from it. Part two is then simply filtering your input file depending on that flow variable using Rule-base Row Filter node.
Here is example workflow:
Input files are inside data folder within workflow directory and workflow relative paths are used so you can test it.
I was just curious if it is possible to create a dynamic approach to get the desired date. However in course of the analysis and this discussion it turned out, that it will not work without some external source in order to consider not only weekend but also public holidays . Hence of course your approach is much easier and helps to save time.
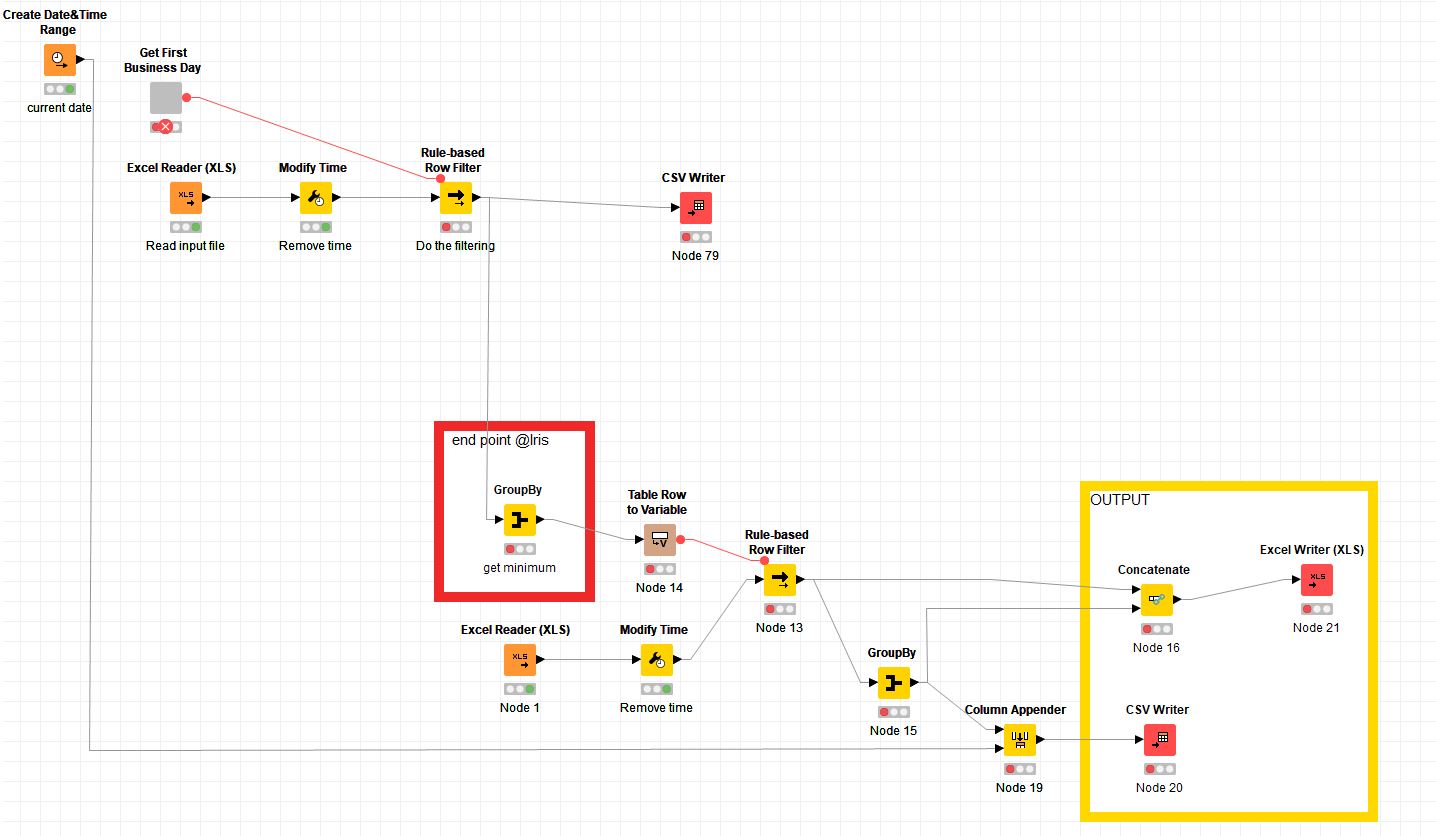
Furthermore it helped me to solve the issues with the formats of the dates I had before. I just had to add a modify time node after every table that include dates. So the “complicated” workflow version does now also deliver the correct outcome . So thanks a lot for that in every respect . This is how it looks like:
I wanted to upload also the workflow, but unfortunately I get an error message when trying to export it.
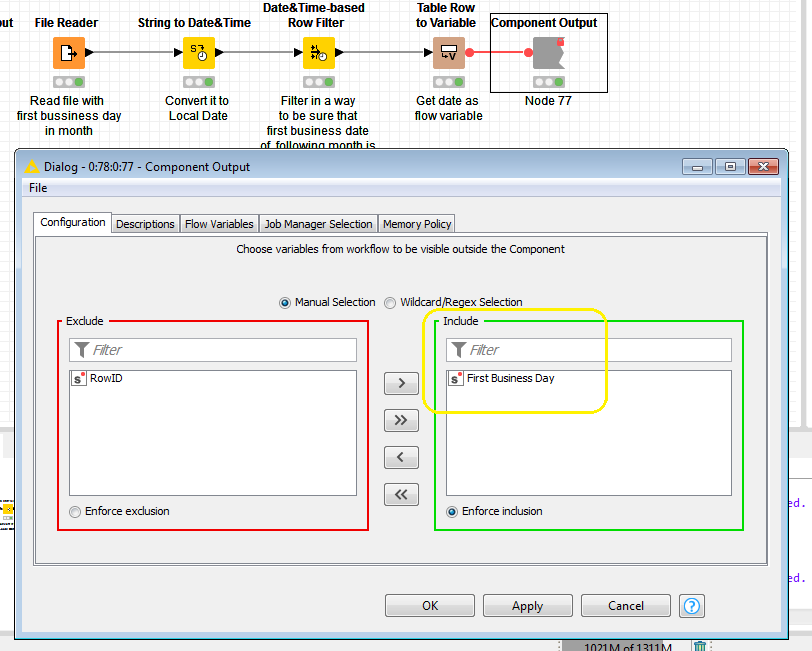
Then I tried to adopt your approach to my workflow. However I cannot configure your flow variable and if I copy the nodes, the flow variable is not there anymore… Can you please tell me how you set up this one? Did you do this with a quickform inside the workflow and if yes which one did you select?
 ? Then I could see how the nodes are configured in detail and would be easier for me to follow through.
? Then I could see how the nodes are configured in detail and would be easier for me to follow through.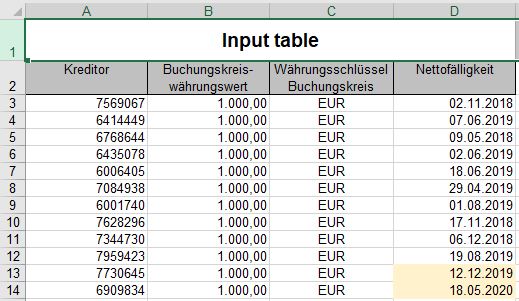



 Then you take this file as an input, filter it so it includes first business days of following month and create a flow variable from it. Part two is then simply filtering your input file depending on that flow variable using Rule-base Row Filter node.
Then you take this file as an input, filter it so it includes first business days of following month and create a flow variable from it. Part two is then simply filtering your input file depending on that flow variable using Rule-base Row Filter node.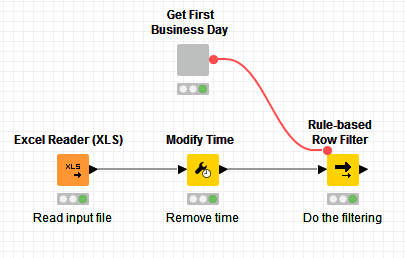
 . Hence of course your approach is much easier and helps to save time.
. Hence of course your approach is much easier and helps to save time. . This is how it looks like:
. This is how it looks like: