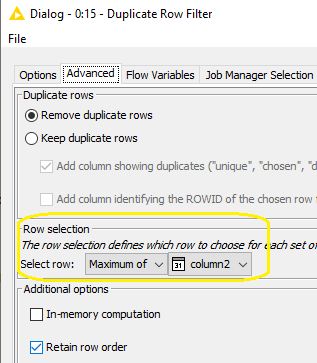
If you sort first by date so that “maximimum sprintenddate per issueid” is the first one appearing among the rows which are in some how “duplicated”, then you could filter duplicates based on the columns that are key for you to filter same rows.
The -Duplicate Row Filter- should keep the first row among the several ones for which you need eventually just to keep only one.
Interesting, for these questions I always think about groupby node first. Thanks for reminding me about the duplicate row filer and it’s options @aworker@ipazin
@Daniel_Weikert and you can always use a local database and window functions to deal with duplicates in a controlled way (rank, first, last). But for most purposes the new duplicate row filter should do the job