I am building a deep learning network (using DL4J nodes) and am reading data from files with over 60K rows. I would like to only include every third row. I.e., I would like to filter out 2 out of every three rows. I transpose the table (so the rows become columns) so I could also filter on the columns if that was easier. Random selection of rows or columns would also be acceptable as long as I wind up with about 20K. I appreciate any suggestions on how to do this.
Hi @jeffreysdelong,
take your table, append a new column with Math Formula and value $$ROWINDEX % 3 and Filter by 0,1 or 2 with a Row Filter.
Best regards
Andreas
2 Likes
You could also use the Partitioning node if random is ok
Steve
Great suggestions. I will check them both out.
Thanks, Jeff
1 Like
Or Row Sampling Node.
And the Sampling in these doesn’t need to be random. Just select linear sampling.

2 Likes
@beginner - thanks - that looks like the Row Filter analogue of the Partitioning node, which also on close inspection has the same options.
I guess the final choice depends whether @jeffreysdelong wants the remainder of his dataset as a test set.
Steve
Thanks for all the suggestions. I wound up using Andrew’s suggestion.
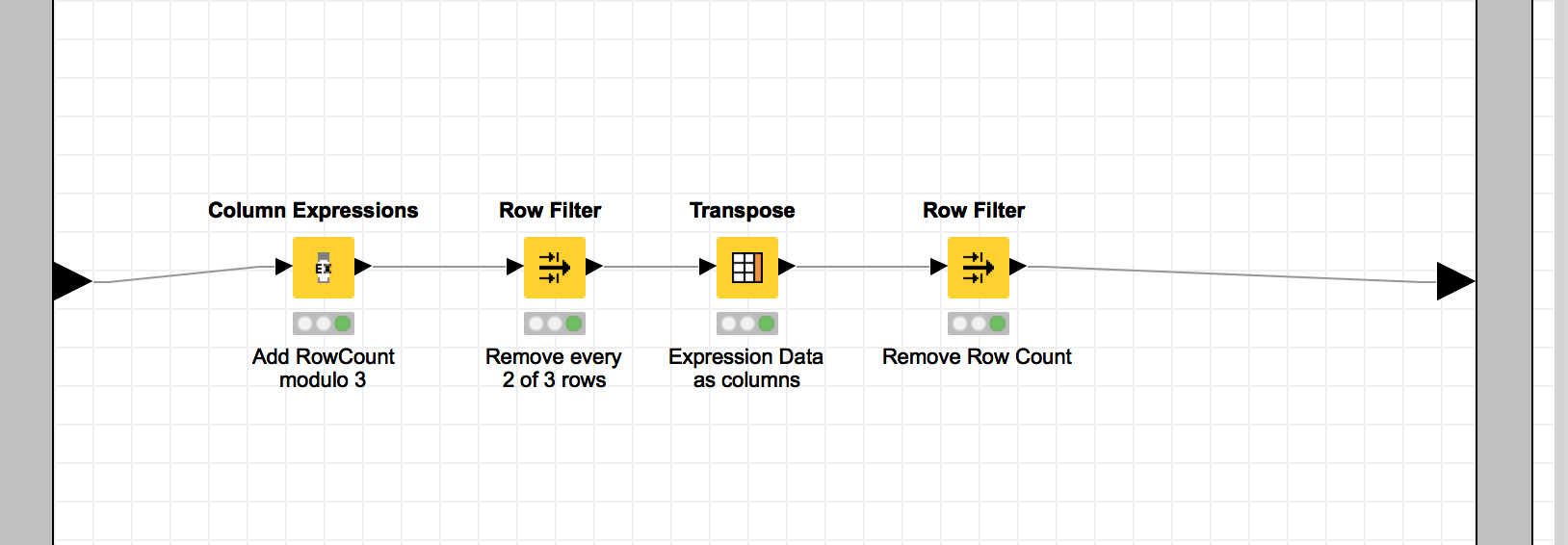
The input files have gene expression data in a column. I wanted to reduce the amount of data from 60K to 20K to make it more manageable. I then transpose the column to a row so I can add additional patients data.
Fine if it works for you but column expressions is very slow. Using partitioning or row sampling will be faster.