I’m trying to filter out columns from a dataset in which all but one instance have the same value. If I have this input
| Atrib 1 | Atrib 2 | Atrib 3 |
| 0 | 1 | 0 |
| 1 | 0 | 2 |
| 2 | 0 | 3 |
I want the Atrib 2 column filtered out
I’m trying to filter out columns from a dataset in which all but one instance have the same value. If I have this input
| Atrib 1 | Atrib 2 | Atrib 3 |
| 0 | 1 | 0 |
| 1 | 0 | 2 |
| 2 | 0 | 3 |
I want the Atrib 2 column filtered out
Welcome to the forum @xandor19.
This is a difficult ask. If the values are all numbers, then I’d start with trying to use the Low Variance Filter node.
I’ll check if that works, thx
Hi @xandor19 , and welcome to the Knime Community.
How many columns and how many records would your dataset have?
EDIT: Also sorry, I’m probably not understanding the rule properly. Can you break down why Atrib 2 would be filtered out? Is it because 1 and 0 exist in other columns?
And if I had let’s say Atrib 4 like this:
0
1
3
Would Atrib 4 be filtered out?
Hi @bruno29a , I think the rule is (and @xandor19 please correct me if I’m wrong) that a column is to be filtered out if the number of distinct values in that column is 2, and one of those two values appears only in a single row. ie all but one of the rows in a column have the same value .
So Attrib 2 is filtered out because all but one row have the value 0.
@xandor19, I have the same questions as @bruno29a over numbers of rows and numbers of columns as I think it’s one of those questions where a solution that could work on relatively small datasets might not be so good for larger data.
I was thinking along the lines that for a given column, containing N rows, if you sort the data, and then inspect the values of the rows 1, 2, N-1 and N, a column should be removed if either of these conditions is met:
row1 <> row2, but row2=rowN
row1=row N-1, but row N-1<>rowN
I think this algorithm would work because it is saying that in a sorted data set where only the first OR final (but not both) rows differ from the immediately adjacent row, then it follows that the entire data set must contain only 2 distinct values and only one row contains one of those values.
I haven’t yet thought of a quick way to write that algorithm though and there may be better approaches. I I’ll have a think on it. Unless of course my understanding is incorrect ![]()
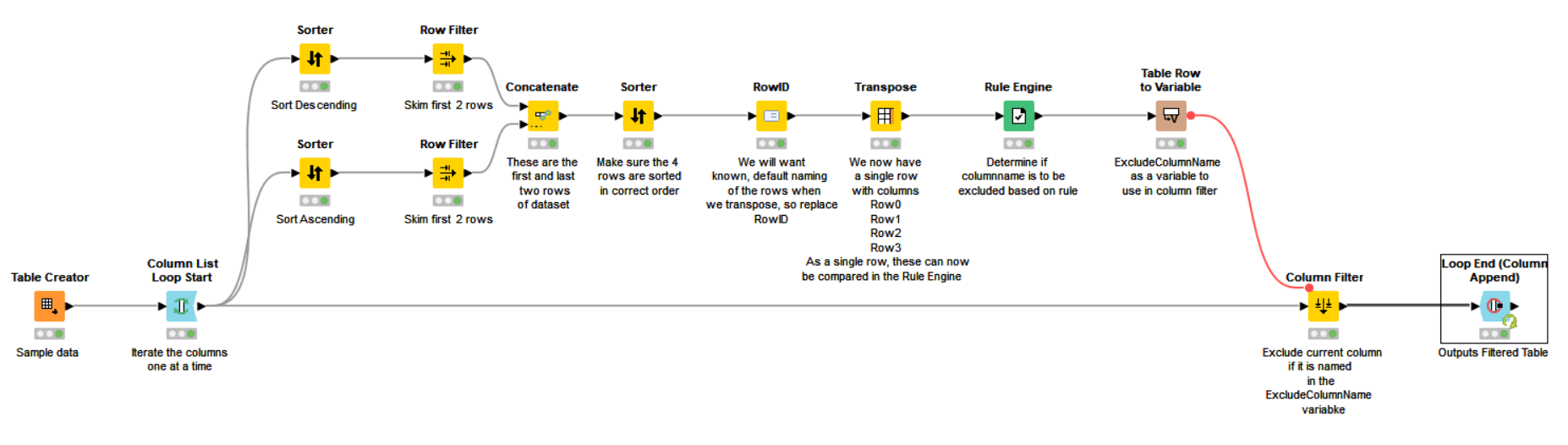
Well, for good or bad, I implemented the algorithm that I mentioned above, and always in my mind is the thought that somebody will say "or you could just use node X . ![]() I’m also thinking there must be alternatives using Group By nodes… but anyway… here is a sample flow.
I’m also thinking there must be alternatives using Group By nodes… but anyway… here is a sample flow.
Because of the way it implements the rule I know of the following limitations:
The main branch simply loops through columns and contains a column filter to decide if a column is to be “allowed through” in which case it is appended by the Loop End node into the final data set.
The upper branch determines for each column if the column should, or shouldn’t be filtered and its purpose is to generate a flow variable which will be passed to the Column Filter.
Filter Cols with single diff value.knwf (36.8 KB)
Sample dataset. (Expecting it to filter out column2 and column4 as they each contain a single row with a different value to all other rows.
Result:
bruno29a the rule the one of the previous answer of @takbb. For both of you, dataset is of 490 instances and 8132 dimensions (it’s the study of asian religious and biblical texts aviable here UCI Machine Learning Repository: A study of Asian Religious and Biblical Texts Data Set
Dataset it’s a word count about asian texts and for a college assignment I have to preprocess it with some intention. So, given its high dimensionality, I decided to analyze “relations” between books, so those words that only appear in one book are not relevant (it’s a bit of an assumption cause I was diving in raw data mining, not much into text-related.
About size of the dataset, I reduced it to 8 rows (grouping directly by book name, cause dataset’s instances are individual chapters)
I was considering the first’s answer solution, using variance, but I haven’t been able to find an appropriate threshold. I’ll check your rules now from previous answer and the flow. Thanks a lot
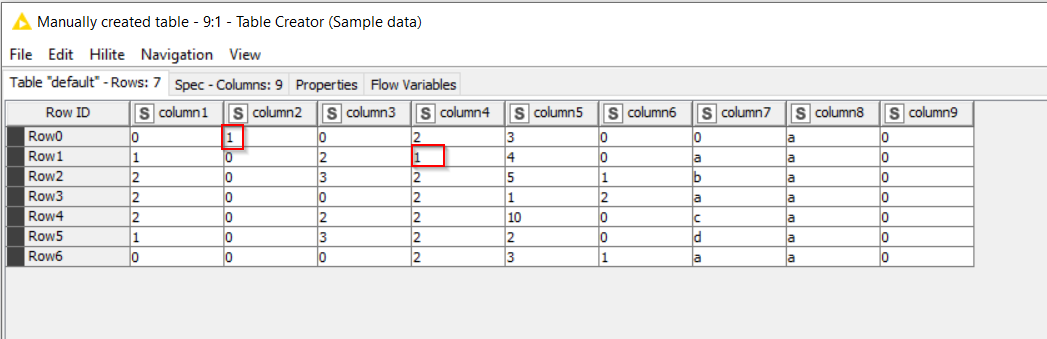
Hi @xandor19 , here’s an alternative solution. Thanks to this thread, I got to use the Reference Column Filter Node for the first time!
Input Table:
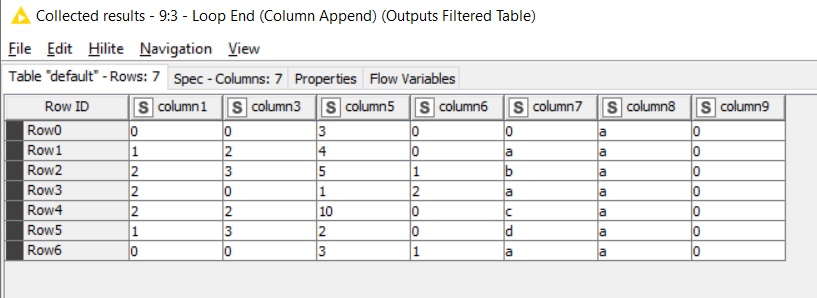
Output Table:
–>>
[Here’s the link to the workflow.] (Filter Out Columns With Only One Different Value – KNIME Hub) <<–
Update: Found a slight bug. Corrected that on the latest version.
@badger101 Nice solution!
I use the reference row splitter all of the time, but never noticed there was a reference column splitter until this post! I definitely have uses for that one… Thanks!
Just to note here that I’ve fixed the bugs twice, just in case everyone downloaded it too early.
Should be fine now. Peace out ![]()
Thanks @iCFO
Hi @takbb @xandor19 thank you both for confirming the rule.
I understand what @takbb wrote:
row1 <> row2, but row2=rowN
row1=row N-1, but row N-1<>rowN
But I still can’t relate it to what @xandor19 wrote ![]()
And I definitely thought of something completely different, sorry about that.
Nice one @badger101. I too had not noticed the Reference Column Filter before. Perfect for this job!
@bruno29a, lol. If you think what I wrote there was bad (and yes maybe I had too much tea this morning!) , have you ever tried “System Specification using Z” ? It’s even worse: a means of writing accurate and mathematically provable formal system specifications that absolutely nobody can understand… ![]()
Hey @takbb , no I think what you wrote there is correct. @xandor19 has also confirm so.
My comment about not being able to relate it to what @xandor19 wrote is on me, not on you. The comment was more about “how the hell did you figure this out??” ![]()
Well many is the time I’ve seen you respond correctly to forum questions too, when I am sitting there wondering what the question meant. It’s funny how one question “clicks” and another doesn’t isn’t it.
But ah yes that was definitely early morning tea that was at play there for me. If anybody is wondering what I meant with my pseudo-equation (lol), I’ll describe it again.
So my cup of tea said to me… ![]() that a list of any length containing only two distinct values X and Y, with X appearing only once will, once sorted look either like this:
that a list of any length containing only two distinct values X and Y, with X appearing only once will, once sorted look either like this:
row value
1 X
2 Y
(any number of repeats of Y)
n-1 Y
n Y
or
row value
1 Y
2 Y
(any number of repeats of Y)
n-1 Y
n X
So I figured “all” we had to do ![]() was sort it and then look at the first two and last two row’s values… and check that either the first or last value differed from the other values. We don’t have to compare all 4 rows because if the list is sorted and row(1) = row (n-1), we know it MUST equal row(2). And that was it. But it wasn’t quite as straightforward as I thought it would be.
was sort it and then look at the first two and last two row’s values… and check that either the first or last value differed from the other values. We don’t have to compare all 4 rows because if the list is sorted and row(1) = row (n-1), we know it MUST equal row(2). And that was it. But it wasn’t quite as straightforward as I thought it would be.
(In the event though, @badger101’s solution I think is better and far more efficient than mine. It was fun though!)
Now coming out of this, one nice feature I’d like to see in the row filter would be to be able to specify something like “last n rows” in the filter. Is there such a thing in KNIME, that I’ve missed?
At the moment the easiest (but not very efficient) way I know is to sort it the opposite direction and then take the first n rows. That’s what I did in the solution. Alternatively I could fetch the row count, then subtract from it into a flow variable and pass that to the row filter but it feels like a lot of work. ![]()
It would be good to be able to specify a row number range in the row filter as, for example, -1 to “end of table” to return just the last two rows, and -2 to end would be the last three rows, and so on.
I love how different everyone approaches these things. KNIME has such a wide variety of users bringing massively different backgrounds / expertise to their workflow methodologies. I love that the platform is so flexible that everyone can really adopt it to how their brain problem solves. I had the same head scratch as @bruno29a on yours. Thanks for the walkthrough.
My first inclination was to do a transform and unique count, then filter the rows that met the criteria, then transform back. Now that I know about the column reference filter / splitter nodes, I would go that way.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.