I’m wondering how to split the rows in the two groups: with and without missing values? I’ve tried with the row splitter node, but it seems like that a predefined column is needed… Is there some way to find out the rows that contain missing values, without searching on defined column? Perhaps with Java snippet Row splitter? But I’m not good at programming…
Thanks.
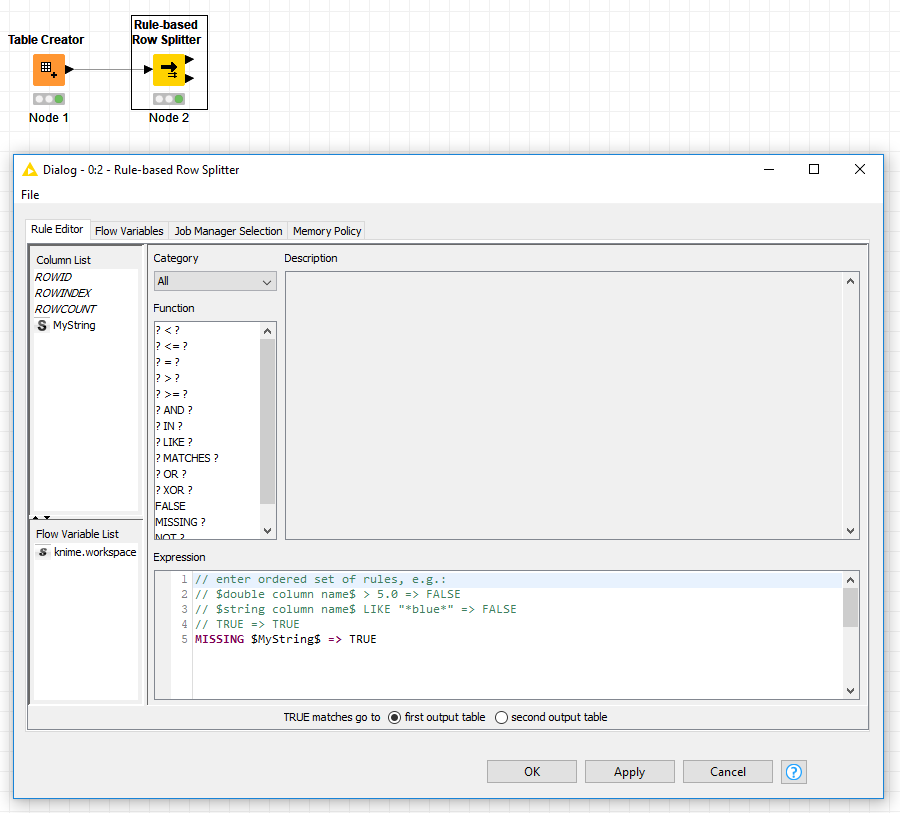
Here’s a simple workflow that uses the Rule-based Row Splitter node on a string input. Rows with missing values get routed to the top port, while everything else goes to the bottom port. The trick here is the use of the MISSING keyword before the variable in the rule expression.
Not so sure. In my case you need to delete columns from Extract Missing Value Cause node output… Here just add as many rules as columns and syntax is the same for each.
Thanks Scott. But in your case there’s only one column. Can I also with this node the rows with missing values filter when there’s many columns containing missing values?
Thanks for the tip. It works I need only add a “reference column filter” after using the “extract missing value cause” node, to make sure the columns are the same with the original data set.
I’m thinking we have some base classes at Vernalis which might make a missing value row filter node possible with relatively little effort, and would possibly allow some other behaviour (e.g. Should a collection column containing a missing value as a cell within the collection be removed?)
If anyone thinks that sounds useful then I will investigate how easy it would be to do in reality.
I think that would be very helpful.
If it is possible, perhaps also some functions of dealing with missing values like mutiple imputation or allow to extract the cells containing missing values, replace them with the values that are imputed with a predictive model or something like that…
I think you could use the solution from @ScottF in combination with the Column List Loop Nodes to achieve your goal for an arbitary amount of data columns.
Another solution might be to use the Column Aggregator Node on all the columns and use the Missing Value Count option in order to find the rows containing one or multiple missing values.
I’m sorry. I thought about it and realized it would not work with a column list loop. It would split each column differently then join it back again, creating something…probably ugly. I was playing around, coming up with another solution with a chunk loop node. But i think the solution Iris summarized is probably the best and most efficient.
yes the solution by Iris works well.
However, it seems that you need to have a concrete number - at how many missing values you like to filter rows.
In my case using percentage would be preferable.
I thought using the Rule based Row filter might work, but I wasn´t able to do it.
The precise scenario is such that I have a number of columns having the same strings at th end “XY”.
My idea was:
MISSING $*Xy$ >20% => TRUE
Neither the RegEx works nor the filter >20%.
Any help of a more advanced user would be highly appreciated.
Rule-Based Row Filter can not provide you with percentages like that. Column Expressions node that is based on JavaScript syntax can help you with that approach.
Also you can transpose data using Transpose node and then use Missing Value Column Filter node where you can define above which percentage of missing values column should be dropped. After that transpose your data again
thank you for helping me!
The Transpose Missing Value Column Filter node idea worked for me.
With the column expressions node I had no clue how get an automatic column selection based on something like *XY. Also the selection of lets say remove rows with > 20% missing values - no idea.
Possibly this node is too advanced for me?!

 I need only add a “reference column filter” after using the “extract missing value cause” node, to make sure the columns are the same with the original data set.
I need only add a “reference column filter” after using the “extract missing value cause” node, to make sure the columns are the same with the original data set.