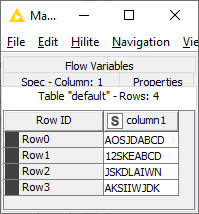
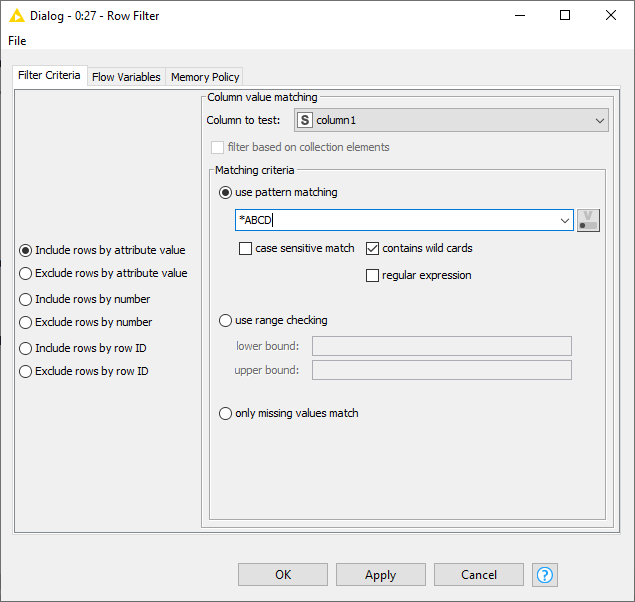
I’m new to knime because I’m trying to consolidate into one environment so I can stop bouncing back and forth between R and Python. I’m trying to merge data together from a dozen different data reports and I need a node that allows me to quickly filter rows by substring to see if a value exists so I can figure out why I’m end up with missing values after a series of joins.
For example,
If I have strings that look like: “*****ABCD”.
I need to filter a table down rows that match “ABCD”.
How do I set up a node to run a quick match on each data source to see if it’s really missing or if I have some more data cleaning to do?
I can’t seem to make any regex work in Knime, so I’m assuming there’s some syntax that I’m missing.
Is there a regex guide specific to Knime floating around out there?
Got it thanks! I kept thinking an asterisk would be interpreted literally. It didn’t occur to me that’s what the checkbox for wildcards was referring to.