Below is a partial sample of data - I have various channels with associated spend, engagement, revenue data that comes out of System A. I want to join to the various media platforms in Systems B, C, D, E… etc. Probably not the cleanest way, but I want to split the rows of data in System A by their channel grouping and have each channel grouping branch out and join to each respective system (B,C,D,E, etc.).
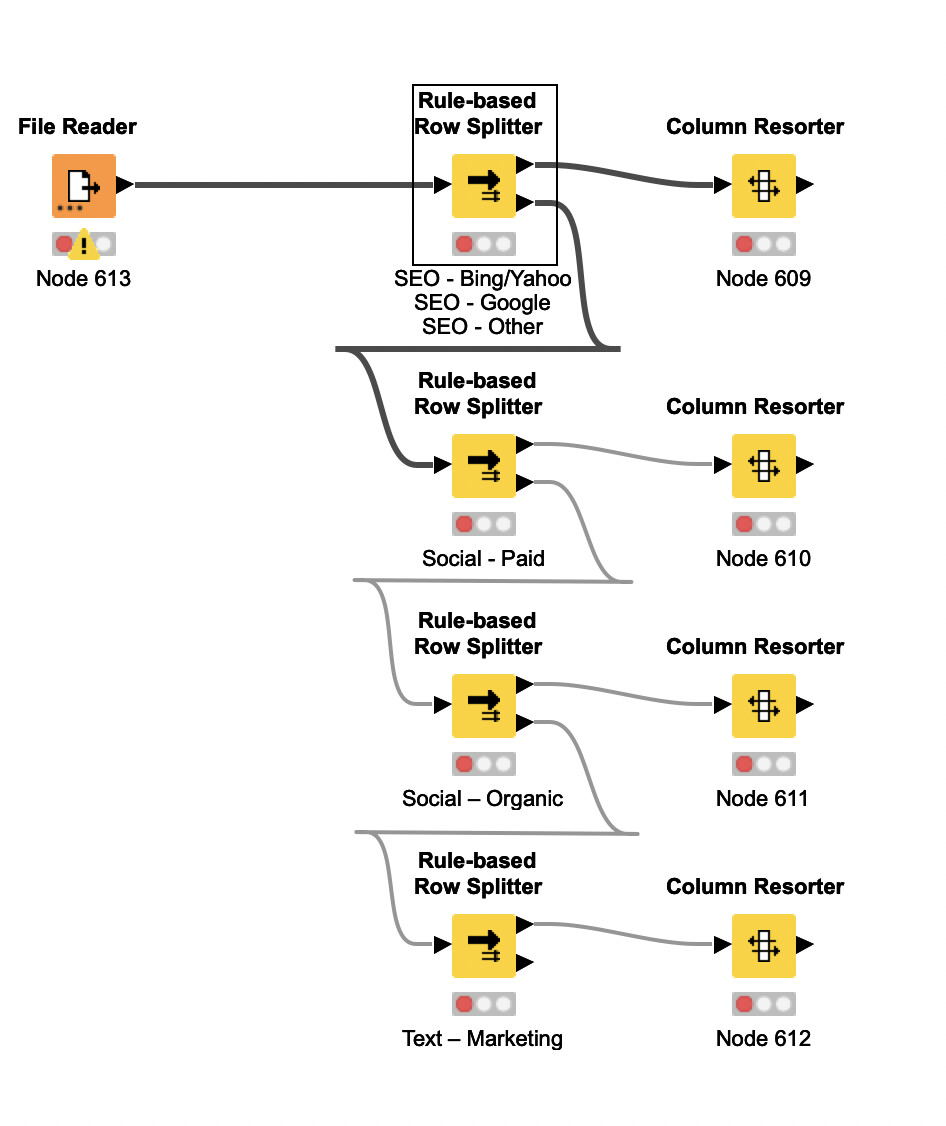
I started by building out each filter using a rule filter. When the rule is satisfied, I push the data out of the top output and can join to the data input of the corresponding media platform (see image below). However, I was wondering if a loop could be used? My thought was a loop start, pass into ‘groupby’ that groups all of the values in the field I want to filter by, then pass into each stream.
This image reflects my file input - then each rule-based row splitter passes the data that is satisfied into a workstream, and the data that doesn’t satisfy moves to the next filter where a new rule is created, and so forth. IN this example, I used a column resorter to simply show that I would have four paths, but in reality, I would have a joiner to join to the different feeds, then concatenate the feeds together into one overarching report.
The data, in its most simple form, looks like the following:
| date | channel | metric 1 | metric 2 | etc. |
|---|---|---|---|---|
| 2023-01-01 | seo_google | 5 | 6 | 7 |
| 2023-01-02 | seo_google | 6 | 7 | 8 |
| 2023-01-03 | seo_google | 43 | 52 | 62 |
| 2023-01-04 | seo_google | 5 | 6 | 7 |
| 2023-01-05 | seo_google | 3 | 4 | 5 |
| 2023-01-06 | seo_google | 23 | 28 | 34 |
| 2023-01-07 | seo_other | 4 | 5 | 6 |
| 2023-01-08 | seo_other | 5 | 6 | 7 |
| 2023-01-09 | seo_other | 4 | 5 | 6 |
| 2023-01-10 | seo_other | 3 | 4 | 5 |
| 2023-01-11 | seo_other | 35 | 42 | 50 |
| 2023-01-01 | social_paid | 5 | 6 | 7 |
| 2023-01-02 | social_paid | 6 | 7 | 8 |
| 2023-01-03 | social_paid | 7 | 8 | 10 |
| 2023-01-04 | social_paid | 786 | 943 | 1132 |
| 2023-01-05 | social_paid | 4 | 5 | 6 |
| 2023-01-06 | social_paid | 4 | 5 | 6 |
| 2023-01-07 | social_paid | 3 | 4 | 5 |
| 2023-01-08 | social_paid | 35 | 42 | 50 |
| 2023-01-09 | social_paid | 5 | 6 | 7 |
| 2023-01-10 | social_paid | 6 | 7 | 8 |
| 2023-01-01 | social_organic | 7 | 8 | 10 |
| 2023-01-02 | social_organic | 786 | 943 | 1132 |
| 2023-01-03 | social_organic | 4 | 5 | 6 |
| 2023-01-04 | social_organic | 4 | 5 | 6 |
| 2023-01-05 | social_organic | 3 | 4 | 5 |
| 2023-01-06 | social_organic | 35 | 42 | 50 |
| 2023-01-07 | social_organic | 5 | 6 | 7 |
| 2023-01-08 | social_organic | 6 | 7 | 8 |
| 2023-01-01 | text_marketing | 7 | 8 | 10 |
| 2023-01-02 | text_marketing | 786 | 943 | 1132 |
| 2023-01-03 | text_marketing | 4 | 5 | 6 |
| 2023-01-04 | text_marketing | 3 | 4 | 5 |
| 2023-01-05 | text_marketing | 35 | 42 | 50 |
| 2023-01-06 | text_marketing | 5 | 6 | 7 |
| 2023-01-07 | text_marketing | 6 | 7 | 8 |
| 2023-01-08 | text_marketing | 7 | 8 | 10 |
How would I structure a loop (if possible) where seo_google (field value 1) gets filtered and pushed through to workstream 1, seo_other gets pushed through to next work stream, social_paid through the next, etc. so that I can create this with a loop node, groupby, rule filter, and multiple outputs? or is this not feasible?
Thank you!